下面是之前在一个技术群里面分享的阿里云表格存储的内容,因为时间因素,只对[技术分享附件]中的少部分内容进行了分享,下面是分享内容,欢迎下载附件并就里面的内容深入交流。
接下来的内容分为几个方面,第一是背景,就是为什么要做这个东西;第二是几个使用场景,让大家有个感性的认识;第三是系统架构以及该架构如何做到高性能、高可靠、高可用;第四是一些工程经验;我也比较希望大家看看最后的附录中我对垂直和分层两大设计体系的思考,这部分我们可以做更深入的交流。
好,下面正式开始。先介绍为什么要做,大家可以看PPT第3页。

第一个问题是扩展性的问题。我们把类似Oracle、MySQL等关系型数据库叫传统数据库,注意不是说这些数据库过时了,只是就功能点和业务场景划分的。我们注意到的是,传统数据库基本都是单机设计,这样做容易提供丰富的关系计算(数据全部在一起),但是也导致当用户数据量和计算量增加的时候,可扩展性是一个新的课题。今天业务比较活跃的话,单机MySQL能够搞定的数据量大概在1T以内,当然高手们有很多优化手段能够获得更好的结果,不过大多数程序员是要忙于业务的,不可能专门搞数据库,优化到极致还是很难的,而且如论如何,都会碰到单机硬件的天花板。
这时候有一个方案就是分库分表,这类解法需要业务的配合,首先就是要求业务层面上能够做到拆分和隔离,比如游戏可以一个区一个库;然后是业务代码会感知到分库分表,并在数据库访问层处理好路由规则,比如某条业务数据应该到哪台机器上访问之类的,还要处理机器不可用时候的容错,这增加了业务代码的复杂性。
第二个问题是关于灵活性的。我想不少人都碰到过随着业务的发展需要数据表添加一个字段,但是绝大部分传统数据库添加字段是一个复杂的操作,可能要锁表停业务,或者做数据的全量拷贝,这时候如果数据表允许用户任意添加字段就会是一个吸引人的功能,这也是类似表格存储这样支持宽行的NoSQL产品的一个很大优势。
再看看可用性的难题。一个机器上的进程要保持持续可用是相当不容易的,因为太多的因素可以影响到他,从机房供电到机器散热、从网络拥塞到时钟异常、从操作系统bug到软件bug,从硬盘故障到运维错误,只有每一项都完美的配合才能做到这个进程持续可用,实际上基本是不可能的。
针对单进程可靠性不足的问题,传统数据库大多提供了主备方案,这种方案一般是在数据可靠性和服务可用性之间做一个权衡。如果选择同步复制,那么可用性就会受到影响,因为主备只要一个挂了,服务就不可用。如果选择了异步复制,那么就牺牲了数据可靠性,因为只要主库down机,就可能有几秒的数据没有复制到备库。非常牛逼的团队可以同时解决上面两个问题,解决的方案就是利用新兴数据库类似的技术,比如利用分布式存储提供数据高可靠或者通过类似Paxos的一致性协议独自做多主。
解决上面三个问题的方案可以是在传统数据库上改造,也可以是开发新的存储系统。我们是选择了后者,于是做了表格存储。表格存储并不是要替换传统数据库,也没有能力这么做,只是迎合巨量数据的爆发满足了一些新的需求。表格存储最开始在公司内部叫做OTS(Open Table Service),后来对外发布则叫做表格存储。表格存储架构极大的参考了Google的三驾马车之BigTable,群友也可以通过读BigTable的论文来获得更深入的理解;有一个开源产品叫HBase,也是参考BigTable,群友也可以借此获得更多的信息。
下面看第二个话题,就是表格存储能做什么,我们快速的过一下。第一个例子是日志存储和读取,结构图见下。PPT 第5页。

表格存储后台采用了LSM(Log structured merge)模型,是偏爱写的,这正好契合了日志写多读少的场景,一个实际的例子是200Byte左右的日志行,我们单机每秒可以写60,000行。日志应用除了将正文存储在表格存储上,也将倒排索引存储进来,这样就可以满足用户多维度查询的需求,这个日志服务在整个集团层面已经大规模的使用。
第二个例子是邮箱服务,见PPT 第8页。

这个重点是多个索引的建立,比如一封邮件进来,需要按照发件人,发件时间,收件人,主题等建立多个维度的索引(想想邮箱中的按照发件人排序,按照主题排序等功能),这个索引的特点是他是一个局部索引,也就是说事务范围是一个用户账户下的数据(用户不会看到别人的邮件),这比通用的数据库事务好做很多,我们目前对公司内开通了这个功能。这个场景可以很容易的扩展到社交领域。
第三个是金融风控的场景,这个场景其实挺简单的,就是把风控模型导入到表格存储里面,然后在需要的时候来读,因为一笔风险判断可能要读N条数据,所以性能要求极高(高命中率,SSD磁盘),当然,高可用也是一个重要考量。
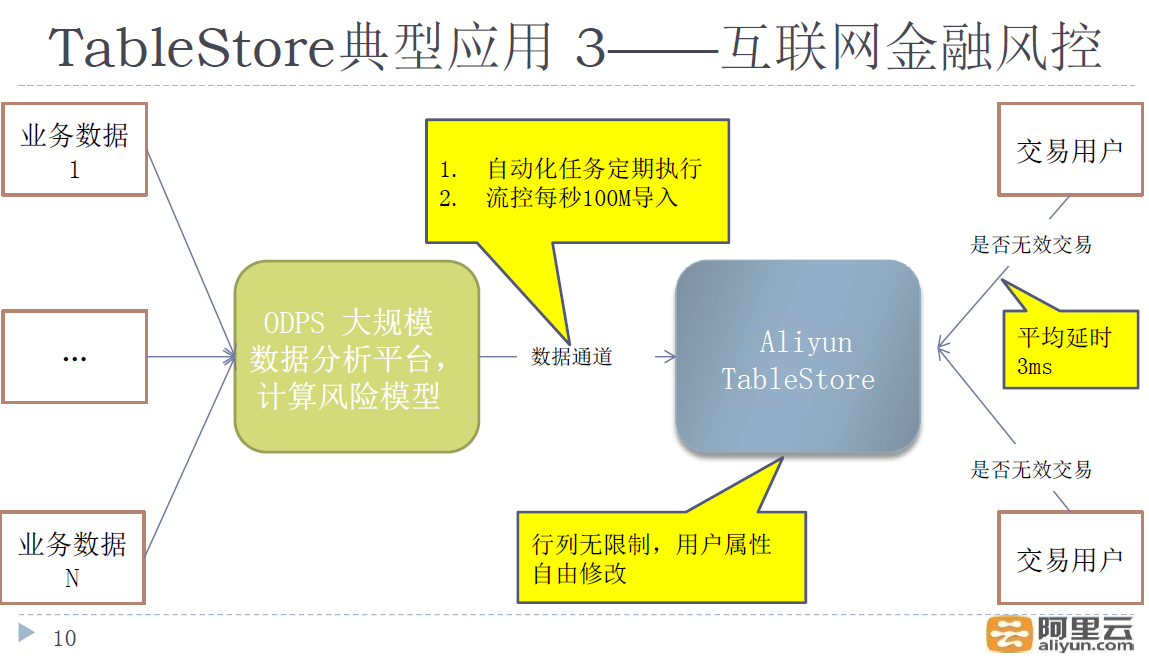
通过上面三个场景,我们对表格存储有了一个感性的认识,就是写入能力强,高可用,高性能以及支持单表局部事务,其他特点还有支持数据自动过期(比如日志数据3个月前的自动删除),多版本(比如高并发时候要求数据不得覆盖),过滤器,不支持跨表事务,不支持SQL查询,不支持Join查询。
下面看第三个话题,表格存储的架构,PPT第13页。
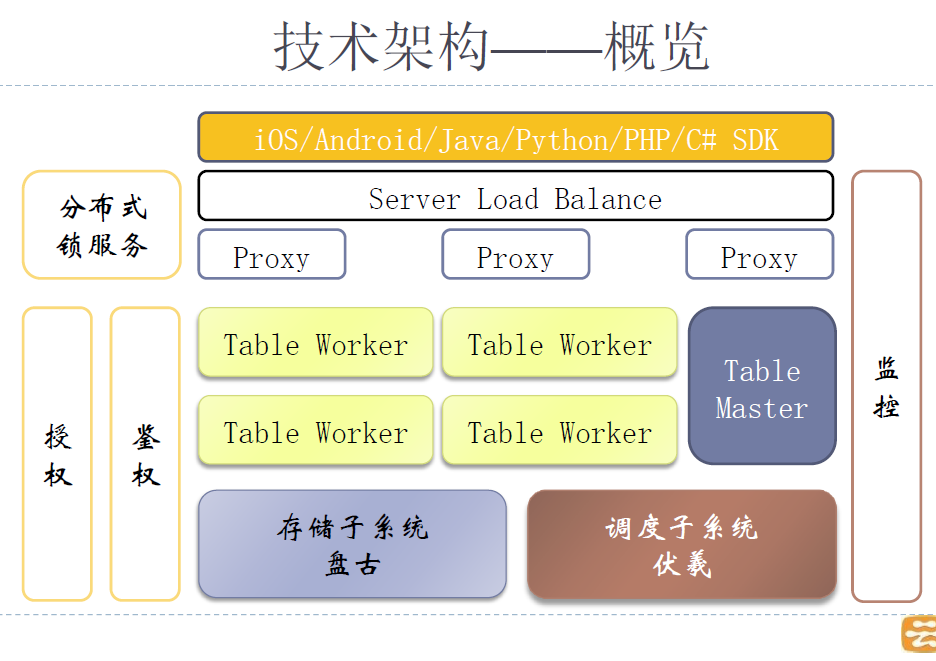
上图是一个通用的分层存储产品架构图。最下面是存储和调度系统,上面是产品的Master/Worker,再向上是接入层负责鉴权等功能,最前面是多个语言包括移动端的SDK。其他监控、锁服务等也是分布式系统的基本配置。今天我们只讲存储系统和中间的Master/Worker层。
分布式存储系统是公司所有产品共享的,除了表格存储,很多阿里云的产品都是基于这个存储系统来开发的。分布式存储系统架构见PPT 14页,大体看来跟GFS类似(Hadoop体系中HDFS也是类似),只是master做成了Paxos组,failover可以做到秒级切换。
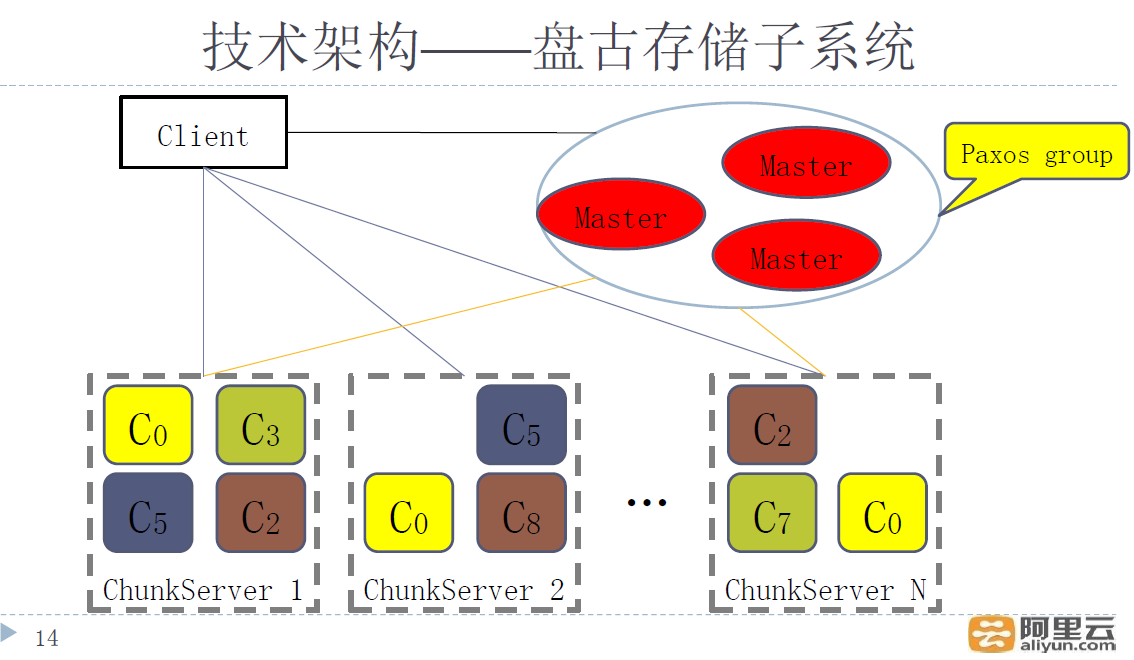
细节太多,下面列一些比较重要的,

上面我们说到了表格存储的数据高可靠在单可用区内就是基于存储系统实现的,存储系统中每个文件N份拷贝(一般是3),机器出现down机马上可以发布M对N多点数据复制,保证了10个9以上的数据可靠性。
我们就上面的多文件类型支持多说几句,其中日志文件类型是专门为低延时写入类型业务开发的,是相对于开源产品HDFS的一个很大的优势。见PPT 16页。

首先,日志数据是星形发送给各个ChunkServer的(同时发给A/B/C三台机器),而不是链式发送(先发给A,A发给B,B发给C),这样能降低网络上的延时开销;其次,在ChunkServer层对相同stream内的写可以做聚合,高压力小包写入场景下能大大降低磁盘IO次数,从而也获得性能上的提升。
好,存储系统只讲这个,下面我们看看表格存储的Master和Worker角色。在此之前我们说一下分区的概念。一个表可能增长的很大(上P的都有),这时候一台机器已经无法支撑,于是表格存储将一个表水平分为多个分区,每个分区可以独立的被某个机器加载。分区-机器对应关系的构建称为调度。
Master角色负责表meta的管理,比如建表、删表;分区的调度,比如找最合适的worker来加载分区;自动的负载均衡,比如某个分区太忙要自动分裂,某机器太忙要迁移走一些分区等。我们先以建表为例来展示master-worker的交互,见PPT 20页。
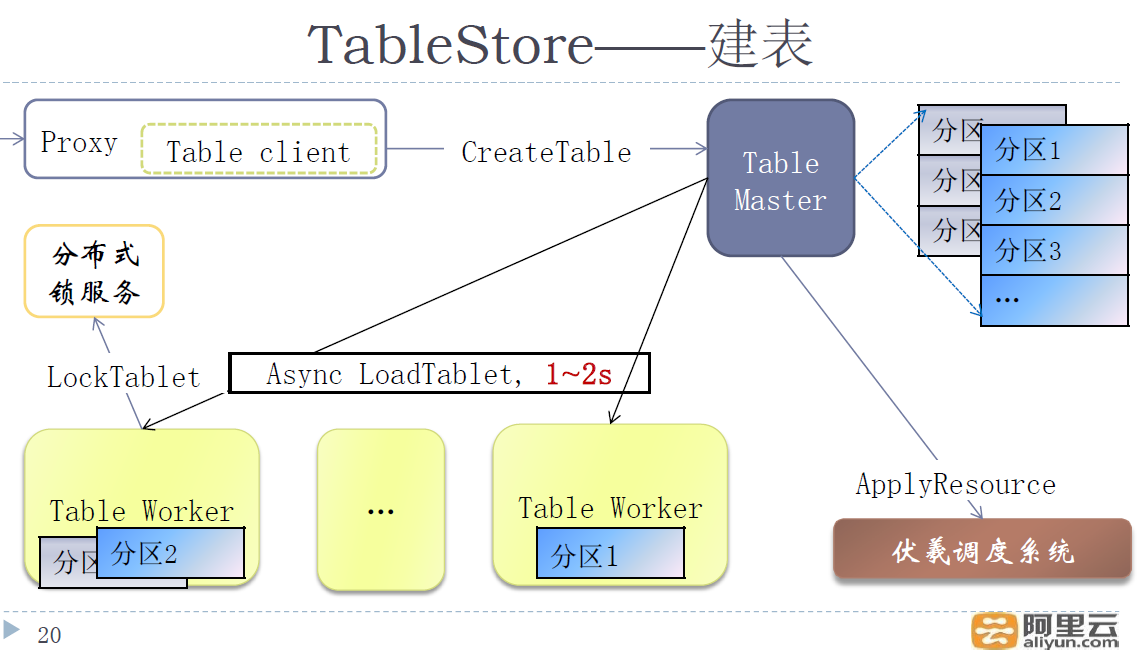
客户端发送建表请求给master,master对表meta做持久化成功后就返回。Master会在后台异步的为该表所有的分区寻找合适的worker来加载,这个过程一般10s以内完成,此时客户单就可以开始读写。
下面我们再讲两点,分别回应文章开头提到的传统数据库可用性的问题,从两个角度,一个是机器down机怎么办,一个是机器负载高怎么办。
先看机器down机的场景,PPT 第21页。

Worker和master之间有心跳,一个机器down掉之后,master和worker之间的心跳会断掉(思考题,如果机器假死,不能服务但是心跳不断怎么办),然后master就会迅速的将该worker上加载的分区分配到集群内其他机器上,因为是多个机器并行加载,因此速度很快,这个过程一般数十秒就可以完成,最坏一分钟,然后用户就可以正常使用了,整个过程是自动化的,运维无需介入。
大家也看到了,这个过程对分布式存储系统有很重的依赖,正是因为分布式文件系统存储了N份,才使得任何机器down掉数据都仍然是可用的,才使得迅速恢复服务变得可能。
第二个问题也是老问题了,就是用户的访问量突然变大,系统能否自适应的快速调整,仍然满足用户需求,不发生响应慢、拒绝服务这样的问题。PPT 第22页提到了类似场景的解决方案,

当master发现某些分区特别忙的时候(比如应用刚建表时候只有一个分区,然后做了个活动,突然流量就涨上来了),会在1分钟内将分区从中间分裂掉,然后找两台worker分别加载这两个分区,如果该分区仍然很忙,那么可以继续分裂。依靠底层的分布式文件系统,分区分裂的时候不必拷贝数据,只要对已有文件集合做个链接就可以,数秒就能完成。比起传统数据库,这种扩展能力对业务的侵入要少得多,而且无需拷贝数据。当然,如果业务提前知道流量将上涨,也可以预先将表做K个分区。
Master/worker的很多细节这里暂时不做展开,待会可以深入讨论。现在我们进入第四个话题,就是在整个开发过程中有哪些经验是可以分享的。工程方面来说,有这么几条。
一是开发要能够自己测试代码,单元测试、系统测试等众多测试都要参与进去,参与了测试才知道问题容易在哪里出现,什么样的代码更容易测试,什么样的代码容易出bug,也能培养开发同学对全系统的责任心。
二是要在团队内建立完善的自动化工具链,比如版本管理系统、bug跟踪系统、任务跟踪系统、checkin前自动运行基本测试的系统、自动化版本发布系统,最后大一统的持续集成系统把这些全部连接在一起。只有工具链完善,好用,开发才愿意在上面添砖加瓦,否则开发想写个测试,一看我靠自己还得写个测试运行框架,那算了吧。构建自动化工具链是架构师必须承担的责任,最好要自己首先跳进去写代码。这方面很多开源工具都可以提供帮助。
三是要鼓励团队自主学习,不仅仅是行政和语言上,更要是行动和细节上。比如看到的难度合适的文章及时分享给团队(也要避免文章轰炸,一月两三篇够了),经常跟团队某些爱学习的同学讨论新技术和已有系统如何改造等,进展会比较缓慢,过程中要有耐心。当然,也很难期望每个人都热爱学习新东西,每个人都能做自己比较擅长的事情就好。
关于性能方面的一些经验见PPT 37页。

粗略的说就是优化网络、磁盘、CPU利用。比如我们统一前后端协议就可以减少不同协议转换的开销、应用程序和网络通讯库之间指针赋值就可以减少数据拷贝的开销等都是优化CPU利用率的做法;而以管道的方式写日志则是通过聚集更多的小包来减少网络和磁盘IO次数;还有通过网卡中断平衡提高小包收发能力等等。
性能优化并没有太多规则可以遵循,一般是看到问题就深入下去干掉,然后就是下一个问题。最终,这些优化的经验会影响接下来的架构设计,并在下一个周期中减少性能优化的工作量。最好的优化就是设计优化(当然,会有人提到过度优化,这个度的把握是要注意的),不给问题产生的机会。
这次分享就到这里,谢谢大家,欢迎讨论。