网络互联设备的增长带来了大量易于访问的时间序列数据。越来越多的公司对挖掘这些数据感兴趣,从而获取了有价值的信息并做出了相应的数据决策。
近几年技术的进步提高了收集,存储和分析时间序列数据的效率,同时也刺激了人们对这些数据的消费欲望。然而,这种时间序列的爆炸式增长,可能会破坏大多数初始时间序列数据的体系结构。
Netflix作为一家以数据为驱导的公司,对这些挑战并不陌生,多年来致力于寻找如何管理日益增长的数据。我们将分享Netflix如何通过多次扩展来解决时间序列数据的存储架构问题。
时间序列数据——会员观看记录
Netflix会员每天观看超过1.4亿小时的内容。而每个会员在点击标题时会产生几个数据点,这些数据点将被作为观看记录进行存储。Netflix通过分析这些观看数据,为每位会员提供了实时准确的标签和个性化推荐服务,如这些帖子中所述:
![]() 如何判断你在观看一个节目?
如何判断你在观看一个节目?
https://medium.com/netflix-techblog/netflixs-viewing-data-how-we-know-where-you-are-in-house-of-cards-608dd61077da
https://medium.com/netflix-techblog/to-be-continued-helping-you-find-shows-to-continue-watching-on-7c0d8ee4dab6
从以下3个维度累积历史观看记录:
过去十年的发展,Netflix已经在全球拥有1亿名会员,其观看记录的数据亦是大幅增加。在本篇博客中,我们将重点讨论如何应对存储观看历史数据带来的巨大挑战。
从简单的开始
观看记录的第一版原生云存储架构使用Cassandra的理由如下:
在最初的方法中,每个成员的观看历史记录都存储在Cassandra中,并使用行键存储在一行中:CustomerId。这种水平分区的方式能够随着会员数量的增长而有效扩展,并且使得浏览会员的整个观看记录的常见用例变得简单、高效。
然而随着会员数量的增加,更重要的是,每个会员的流量越来越多,行数和整体数据量也越来越多。随着时间的推移,这导致了昂贵的操作成本,对于读写具有海量观看记录的会员数据而言性能较差。
下图说明了初始数据模型的读写流程:
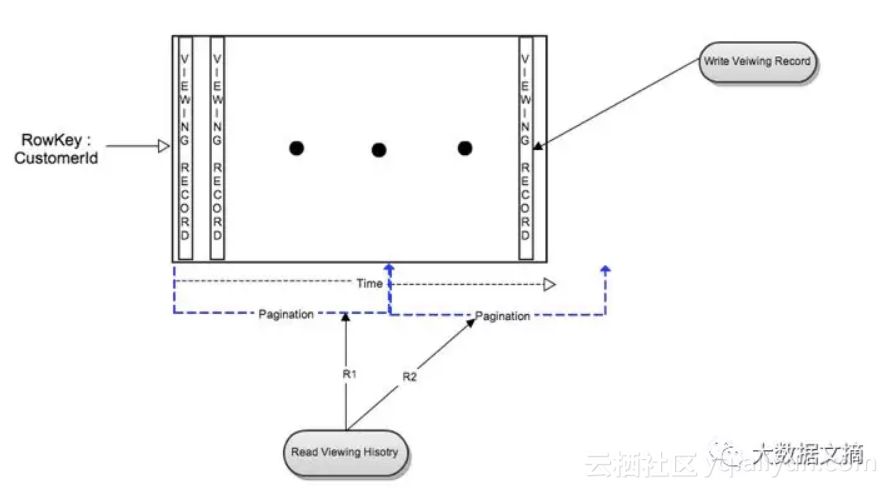
图1:单个图表数据模型
写流程当会员点击播放时,一条观看记录将作为新的列插入。点击暂停或停止后,则该观看记录被更新。可见对于单列的写入是迅速和高效的。
读流程
通过整行读取来检索一个会员的所有观看记录:当每个会员的记录数很少时,读取效率很高。但是随着一个会员点击更多标题产生更多的观看记录。此时读取具有大量列的行数据会给Cassandra带来额外的压力,并造成一定的读取延迟。
通过时间范围查询读取会员数据的时间片:将导致了与上面的性能不一致,这取决于在指定的时间范围内查看记录的数量。
通过分页整行读取大量观看记录:这对于Cassandra来说是好的,因为它并不需要等待所有的数据返回就可以加载。同时也避免了客户端超时。然而,随着观看记录数量的增加,整行读取的总延迟增加了。
放缓原因
让我们来看看Cassandra的一些内部实现,以了解为什么我们最初简单设计的性能缓慢。随着数据的增长,SSTable的数量相应增加。
由于只有最近的数据在内存中,所以在很多情况下,必须同时读取memtables和SSTable才能检索观看记录。这样就造成了读取延迟。同样,随着数据量的增加,压缩需要更多的IO和时间。由于行越来越宽,读修复和全列修复因此变得更加缓慢。
缓存层
虽说Cassandra在观看记录数据写入方面表现很好,但仍有必要改进读取延迟。为了优化读取延迟,需要以牺牲写入路径上的工作量为代价,我们通过在Cassandra存储之前增加内存分片缓存层(EVCache)来实现。
缓存是一种简单的键值对存储,键是CustomerId,值是观看记录数据的压缩二进制表示。每次写入Cassandra都会发生额外的缓存查找,并在缓存命中时将新数据与现有值合并。
读取观看记录首先由缓存提供服务。在高速缓存未命中时,再从Cassandra读取条目,压缩并插入高速缓存。
多年来随着缓存层的增加,这种单一的Cassandra表格存储方法表现良好。基于CustomerId的分区在Cassandra集群中可扩展性亦较好。
直到2012年,观看记录Cassandra集群成为Netflix最大的Cassandra集群之一。为进一步扩展,团队决定将集群规模扩大一倍。
这就意味着Netflix要冒险进入使用Cassandra的未知领域。与此同时,伴随着Netflix业务的快速增长,包括不断增加的国际会员数和即将投入的原创内容。
重新设计:实时和压缩存储方法
显然,需要采取不同的方法进行扩展来应对未来5年的预期增长。团队分析了数据特征和使用模式,重新设计了观看记录存储方式并实现了两个主要目标:
对于每个会员,观看记录数据被分成两个集合:
LiveVH和CompressedVH存储在不同的表格中,并通过不同的调整以获得更好的性能。由于LiveVH的频繁更新和拥有少量的观看记录,因此压缩需频繁进行,且保证gc_grace_seconds足够小以减少SSTables数量和数据大小。
只读修复和全列修复频繁进行保证数据的一致性。由于对CompressedVH的更新很少,因此手动和不频繁的全面压缩足以减少SSTables的数量。在不频繁更新期间检查数据的一致性。这样做消除了读修复以及全列维修的需要。
使用与前面所述相同的方法将新观看记录写入LiveVH。
写流程
使用与前面所述相同的方法将新观看记录写入LiveVH。
读流程
为了从新设计中获益,观看历史记录的API已更新,可以选择读取最近的或完整的数据:
![]() 完整的观看记录:作为LiveVH和CompressedVH的并行读取实现。由于数据压缩和CompressedVH的列较少,因此通过读取较少的数据就可以显著加速读取。
完整的观看记录:作为LiveVH和CompressedVH的并行读取实现。由于数据压缩和CompressedVH的列较少,因此通过读取较少的数据就可以显著加速读取。
CompressedVH更新流程
当从LiveVH中读取观看历史记录时,如果记录数量超过可配置的阈值,那么最近的观看记录就被汇总一次,压缩并通过后台任务存储在CompressedVH中。然后使用行键(行关键字):CustomerId将数据存储在新行中。新的汇总是版本化的,写入后会再次检查查数据的一致性。只有在验证与新版本数据一致后,旧版本的数据才会被删除。为简单起见,在汇总过程中没有加锁,Cassandra负责解决极少的重复写入操作(即最后一个写入操作获胜)。
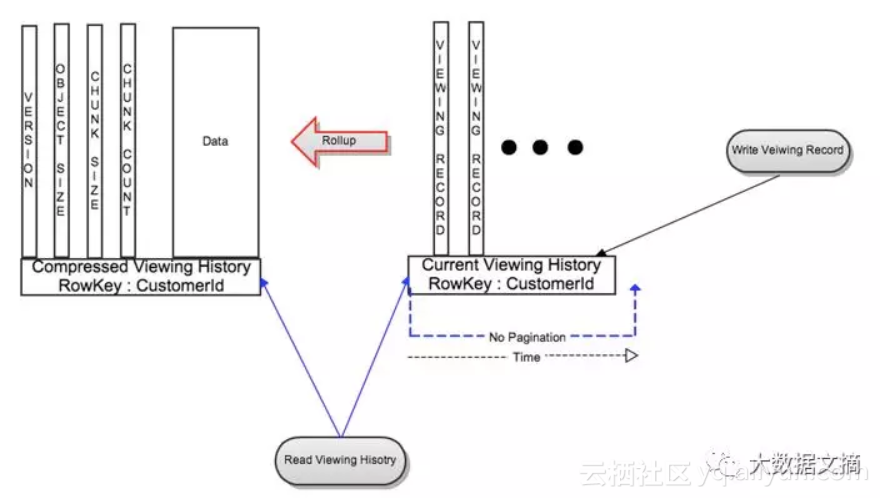
图2:实时和压缩的数据模型
如上图所示,CompressedVH中汇总的行也存储元数据信息,如最新版本号,对象大小和块信息(稍后更多)。版本列存储对最新版本的汇总数据进行引用,以便CustomerId的读取始终只返回最新的汇总数据。
汇总起来的数据存储在一个单一的列中,以减少压缩压力。为了最大限度地减少频繁观看模式的会员的汇总频率,最后几天查看历史记录的值将在汇总后保存在LiveVH中,其余部分在汇总期间与CompressedVH中的记录合并。
通过Chunking进行扩展
对于大多数会员来说,将其整个观看记录存储在单行压缩数据中将在读取流程中提升性能。对于一小部分具有大量观看记录的会员,由于第一种体系结构中描述的类似原因,从单行中读取CompressedVH速度缓慢。不常见用例需要在读写延迟上设一个上限,才不会对常见用例造成读写延迟。
为了解决这个问题,如果数据大小大于可配置的阈值,我们将汇总起来的压缩数据分成多个块。这些块存储在不同的Cassandra节点上。即使对于非常大的观看记录数据,对这些块的并行读取和写入也最多只能达到读取和写入延迟上限。
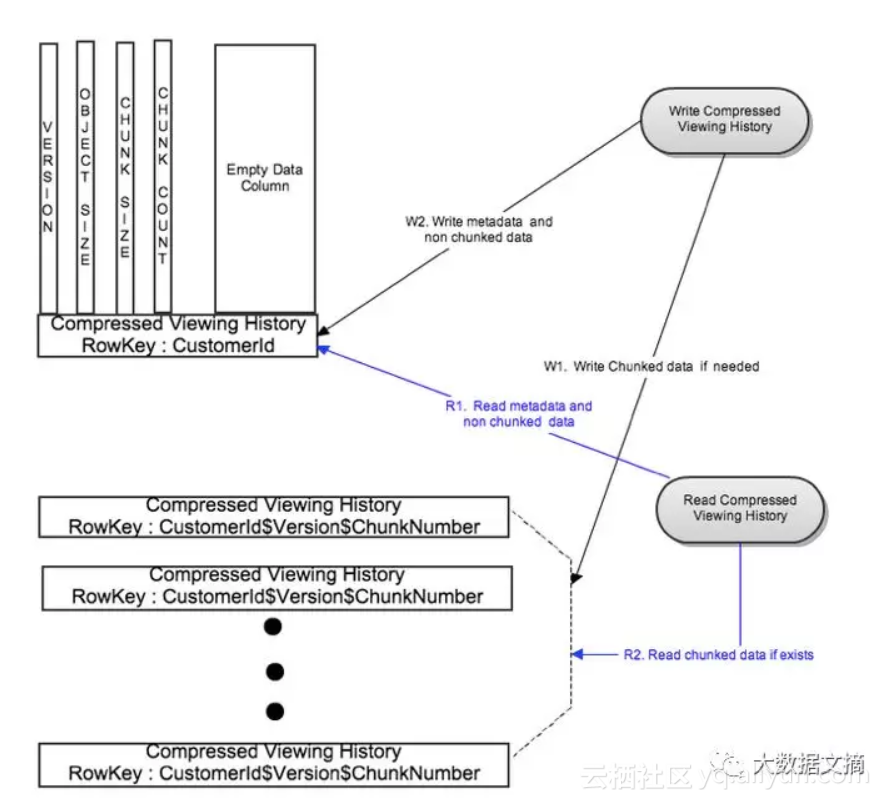
图3:自动缩放通过组块
写流程
如图3所示,根据可配置的块大小,汇总起来的压缩数据被分成多个块。所有块都通过行键:CustomerId $ Version $ ChunkNumber并行写入不同的行。在成功写入分块数据之后,元数据通过行键:CustomerId写入到自己的行。
对于大量观看记录数据的汇总,上述方法将写入延迟限制为两种写入。在这种情况下,元数据行具有一个空数据列,以便能够快速读取元数据。
为了使常见用例(压缩观看记录小于可配置阈值)被快速读取,将元数据与同一行中的观看记录组合以消除元数据查找流程,如图2所示。
读流程
通过关键字CustomerId首次读取元数据行。对于常见用例,块数为1,元数据行也具有最新版本汇总起来的压缩观看记录。对于不常见的用例,有多个压缩的观看记录数据块。使用版本号和块数等元数据信息生成块的不同行密钥,并且并行读取所有块。上述方法将读取延迟限制为两种读取。
缓存层更改
内存缓存层的增强是为了支持对大型条目进行分块。对于具有大量观看记录的会员,无法将整个压缩的观看历史记录放入单个EVCache条目中。与CompressedVH模型类似,每个大的观看历史高速缓存条目被分成多个块,并且元数据与第一块一起被存储。
结果
利用并行,压缩和改进的数据模型,实现了所有目标:
![]() 通过分块和并行的读/写操作保证读/写一致性。常见用例的延迟受限于一次读操作和一次写操作,以及不常见用例的延迟受限于两次读操作和两次写操作。
通过分块和并行的读/写操作保证读/写一致性。常见用例的延迟受限于一次读操作和一次写操作,以及不常见用例的延迟受限于两次读操作和两次写操作。
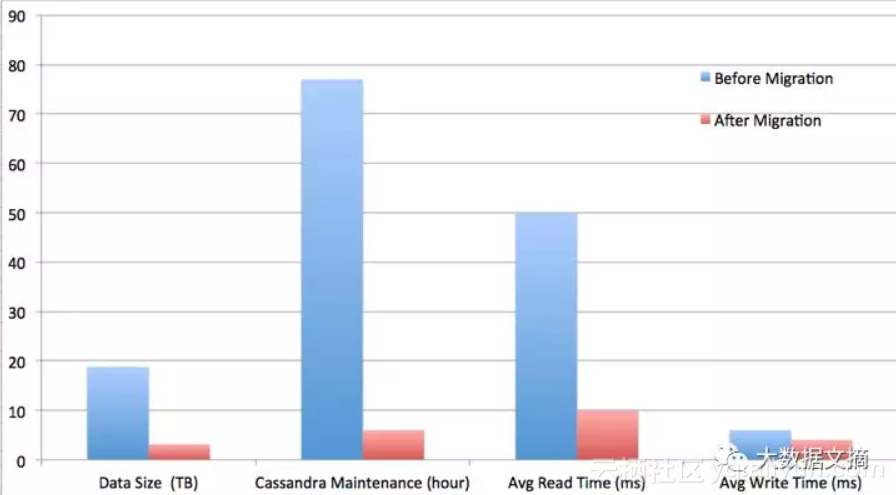
图4:结果
数据大小减少了约6倍,花费在Cassandra维护上的系统时间减少了约13倍,平均读取延迟减少了约5倍,平均写入延迟减少了约1.5倍。更重要的是,它为团队提供了可扩展的架构和空间,可以适应Netflix观看记录数据的快速增长。
原文发布时间为:2018-03-13
本文作者:文摘菌