引用:http://baike.baidu.com/view/371811.htm
编辑本段简介
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免
费开放源代码工具;就其本身而论,Lucene是现在并且是这几年,最受欢迎的免费java资讯检索程式库。人们经常提到资讯检索程式库,就像是搜寻引擎,但是不应该将资讯检索程式库与网搜索引擎相混淆。
[1]
编辑本段历史
Lucene最初是由Doug Cutting开发的,在SourceForge的网站上提供下载。在2001年9月做为高质量的开源Java产品加入到Apache软件基金会的 Jakarta家族中。随着每个版本的发布,这个项目得到
明显的增强,也吸引了更多的用户和开发人员。2004年7月,Lucen
e1.4版正式发布,10月的1.4.2版本做了一次bug修正。表1.1显示了Lucene的发布历史。


版本 发布日期 里程碑
0.01 2000年3月 第一个开源版本(SourceForge)
1.0 2000年10月
1.01b 2001年7月 最后的SourceForge版本
1.2 2002年6月 第一个Apache Jakarta版本
1.3 2003年12月 复合索引格式,
查询分析器增加,远程搜索,token定位,可扩展的API
1.4 2004年7月 Sorting, span queries, term vectors
1.4.1 2004年8月 排序性能的bug修正
1.4.2 2004年10月 IndexSearcher optimization and misc. fixes
1.4.3 2004年冬 Misc. fixes2.4.1 2009年3月8日发布新版本
2.3.0 2008年1月 更新为2.3.0
2.4.0 2008年10月 更新为2.4.0
2.4.1 2009年 5月 更新为 2.4.1
2.9.0 2009年9月25号 更新为2.9.0
2.9.1 2009年11月6号 更新为2.9.1
3.0.0 2009年11月25号 更新为3.0.0
3.0.1 2010年2月26号 更新为3.0.1
3.0.2 2010年6月18号 更新为3.0.2
3.0.3 2010年12月3号 更新为3.0.3
3.3.0 2011年7月初 更新为3.3.0
3.4.0 2011年9月14日 更新为3.4.0
3.5.0 2011年11月26日 更新为3.5.0
3.5.0 2012年4月12日更新为3.6.0
3.6.1 2012年7月23日更新为3.6.1
编辑本段创始人
Lucene['lusen]的原作者是Doug Cutting,他是一位资深
全文索引/检索专家,曾经是V-Twin搜索引擎的主要
开发者,后在Excite担任高级系统架构设计师,目前从事于一些Internet底层架构的研究。早先发布在作者自己的,他贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。后来发布在SourceForge,2001年年底成为apache软件基金会jakarta的一个子项目。

编辑本段特点及优势
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,
程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些
商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse[9]的2.1版本中也采用了Lucene作为帮助子系统的
全文索引引擎,相应的IBM的
商业软件Web Sphere[10]中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene是一个高性能、可伸缩的信息搜索(IR)库。它可以为你的应用程序添加索引和搜索能力。Lucene是用java实现的、成熟的开源项目,是著名的Apache Jakarta大家庭的一员,并且基于Apache软件许可 [ASF, License]。同样,Lucene是目前非常流行的、免费的Java信息搜索(IR)库。
突出的优点
Lucene作为一个全文检索引擎,其具有如下突出的优点:
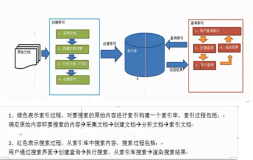
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的
倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的
面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势。
首先,它的开发源代码发行方式(遵守Apache Software License[12]),在此基础上
程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面相对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,
商业软件的灵活性远远不及Lucene。
其次,Lucene秉承了
开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的
面向对象架构,
程序员可以在Lucene的基础上扩充各种功能,比如扩充中文处理能力,从
文本扩充到HTML、PDF[13]等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。
最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,
程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是
开放源代码社区的
程序员正在不懈的将之使用各种传统语言实现(例如.net framework[14]),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,
系统管理员可以根据当前的平台适合的语言来合理的选择。
如何用java实现lucene(只使用,不求甚解版-_-")
前提
lucene有7个包需要导入:analysis,document,index,queryParser,search,store,util
编辑本段搜索
IndexSearcher searcher= new IndexSearcher("E:/index") Query query = new TermQuery(new Term("title", "lucene"));//单个
字节查询
//Query query = new FuzzyQuery(new Term("title", "lucena"));//模糊查询
//BooleanQuery query = new BooleanQuery();//条件查询
//BooleanQuery qson1 = new BooleanQuery();
//Query q1 = new TermQuery(new Term("title", "lucene"));
//qson1.add(q1, Occur.MUST);//MUST是必须满足的
//BooleanQuery qson2 = new BooleanQuery();
//Query q2= new TermQuery(new Term("sex", "woman"));
//qson2 .add(q2, Occur.MUST_NOT);//MUST_NOT是必须不满足
//query.add(qson1, Occur.SHOULD);
//query.add(qson2, Occur.SHOULD);//SHOULD代表满足qson1或者满足qson2都可以
//PhraseQuery query = new PhraseQuery();//近距离查询
//query.setSlop(5);//距离设置为5
//query.add(new Term("title", "lucene"));
//query.add(new Term("title", "introduction"));//查询出title中lucene和introduction距离不超过5个字符的结果
//Query query = new PrefixQuery(new Term("title", "lu"));//WildcardQuery的lu*一样
//RangeQuery query = new RangeQuery(new Term("time", "50"),new Term("time", "60"), true);
//true代表[50,60],false代表(50,60)
Hits hits = searcher.search(query);
for (int i = 0; i < hits.length(); i++) {
Document d = hits.doc(i);
String title= d.get("title");
System.out.print(title+ " ");
}
这样,基本上就可以使用了
注:以上代码为lucene早些版本的写法。lucene3.02的写法有所改变。
编辑本段建立索引
IndexWriter writer = new IndexWriter("E:/index", new StandardAnalyze(),true,MaxFieldLength.UNLIMITED); //true代表覆盖原先数据,maxFieldLength用来限制Field的大小
Document doc = new Document();
doc.add(new Field("title", "lucene introduction", Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
doc.add(new Field("time", "60", Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.addDocument(doc);
writer.optimize(); //优化
writer.close();
| 顶级项目 |
|
|---|
| 其他项目 |
|
|---|
| 子项目 |
|
|---|
- 参考资料
-
-
1. Java搜索引擎 Lucene .开源社区网 [引用日期2012-08-18] .
-
2. Apache Lucene .Apache Lucene .2012-11-7 [引用日期2012-11-7] .
-
- 扩展阅读:
-
- 1
- 2
Lucene使用经验总结,文章汇总:http://liyanblog.cn/tags/Lucene