深度学习作为近几年推动人工智能在机器视觉、语音、自然语言处理等领域取得显著进展的主要方法,已经发展成一门相对成熟的学科。同时,随着越来越多科技企业和科研机构的投入,深度学习的基础支撑技术和工程系统也越来越完善,并且呈现百花齐放的局面。以深度学习计算框架为例, Google的Tensorflow拥有最为庞大的粉丝群,Keras在产业界和学界的接受度都有大幅提升,而Caffe在图像类的模型训练上依然是很多算法工程师的最爱。同时,还有大量其他开源框架,比如MXNet, Torch, PyTorch, CNTK, deeplearning4j等也都保持快速演进,并且在不同体系结构和计算环境下也都有相应的框架项目。
目前,阿里云容器服务提供的深度学习解决方案内置了对Tensorflow, Keras, MXnet框架的环境,并支持基于它们的深度学习模型开发、模型训练和模型预测。同时,对于模型训练和预测,用户还可以通过指定自定义容器镜像的方式,使用其他深度学习框架。
本文将描述如何通过自定义镜像的方式,实现使用Caffe框架在GPU设备上进行多卡模型训练。
使用阿里云容器服务的深度学习解决方案,主要的工作包括:
1. 准备计算资源集群
a) 购买ECS计算资源,可以包括CPU和GPU;
b) 创建容器集群管理上述ECS节点;
2. 准备数据存储,用于保存和共享训练数据集、训练日志和结果模型
a) 创建阿里云共享存储服务实例。目前可以支持阿里云OSS和NAS存储服务;
b) 为上述数据存储创建数据卷,用于将共享存储实例挂载入容器内部。方便训练、预测代码从本地目录读写训练数据等;
3. 在阿里云容器服务控制台的解决方案页面填写参数,配置、启动模型训练任务
以下将就这几项工作,详细介绍。
1. 创建容器服务集群
通过阿里云容器服务控制台 https://cs.console.aliyun.com (首次使用需要免费开通服务),创建容器集群,详见文档
https://help.aliyun.com/document_detail/52677.html?spm=5176.doc53547.6.900.VyPXtY
注:
1. 容器集群所管理的ECS节点资源,可以提前购买好,然后添加到容器集群内。也可以在创建容器集群的时候自动购买。但目前自动购买仅支持包年包月的ECS实例,在加入容器集群后可以再修改为按量付费的类型。
2. 不同ECS服务区域,提供的GPU实例类型可能不同。需要在提前确认。
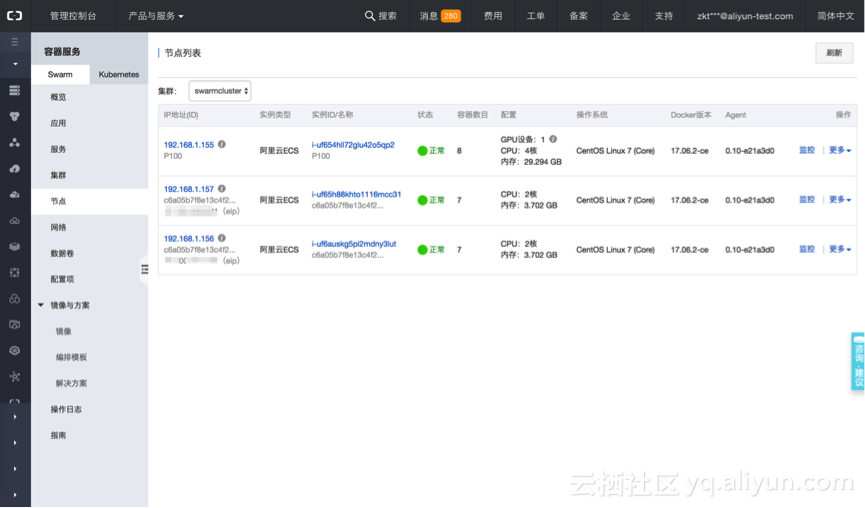
可以在容器服务控制台查看容器集群的详情,如这里创建的华东2可用区B的容器集群“swarmcluster”
2. 创建共享数据存储
容器服务可以通过数据卷挂载的方式支持阿里云OSS对象存储和NAS文件存储。首先,需要创建存储服务实例。
注1: 请在与上述ECS节点的相同阿里云服务区域,创建OSS或NAS存储实例。否则,运行在ECS上的容器将无法访问它们。
OSS对象存储实例创建方法,详见
https://help.aliyun.com/document_detail/31896.html?spm=5176.doc31842.2.5.ug192v
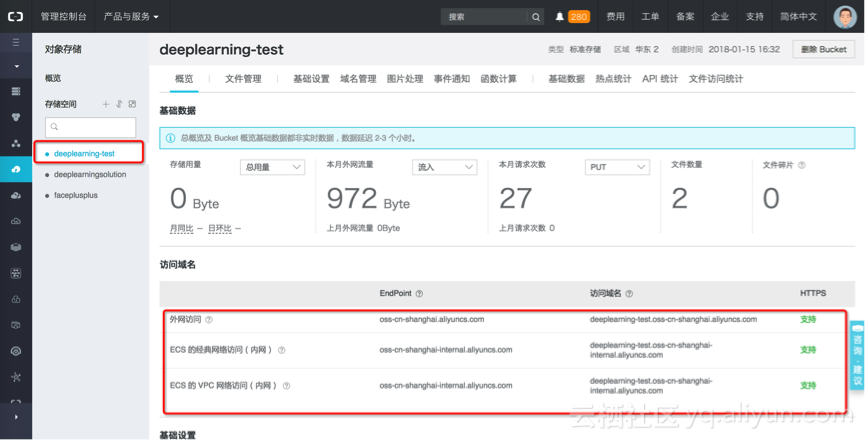
我们在华东2区创建OSS bucket“deeplearning-test”,可以查看其内、外网的访问地址
NAS文件存储实例创建需要两步,详见
1. 创建文件系统
https://help.aliyun.com/document_detail/27526.html?spm=5176.doc27527.6.551.t4fGpd
2. 添加挂载点
https://help.aliyun.com/document_detail/60431.html?spm=5176.doc27526.6.552.mTQl8H
3. 创建数据卷
创建好数据存储实例后,需要在容器集群中创建对应的数据卷。比如,使用OSS作为训练数据和日志存储,可以创建OSS数据卷,步骤详见
https://help.aliyun.com/document_detail/52681.html?spm=5176.doc52677.6.902.DMpKvy
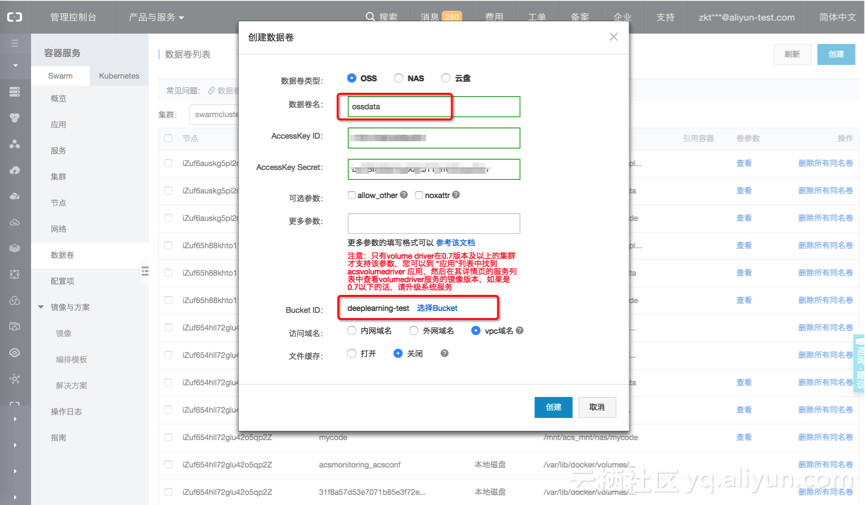
这里我们创建OSS数据卷“ossdata”,用于连接上述创建的OSS bucket “deep learning-test”。
创建NAS数据卷的过程与OSS基本类似。
4. 启动训练任务
至此,准备工作就绪。可以在容器服务深度学习解决方案中创建模型训练任务,使用CPU/GPU开始训练caffe模型。(可以参考支持 Tensorflow的文档,熟悉如何创建一个内置框架支持的模型训练任务。https://help.aliyun.com/document_detail/52691.html?spm=5176.doc52681.6.909.e9Ka98)
目前,解决方案还未内置对Caffe框架的支持。可以通过指定自定义镜像的方式,使用用户自己的Caffe框架来训练模型。过程如下,
a) 构建和推送自定义的容器镜像
用户在开通容器服务的同时,也会开通容器镜像仓库服务。可以使用镜像仓库服务,在与集群相同的阿里云区域创建公开的,或者私有的容器镜像仓库。并把希望使用的Caffe框架制作成docker镜像,推送到镜像仓库中。以后在该集群部署的训练任务就可以使用这个Caffe镜像了。
容器镜像仓库构建的文档可以参考
https://help.aliyun.com/document_detail/60997.html?spm=5176.doc60765.6.547.eGFyUs
https://help.aliyun.com/document_detail/44535.html?spm=5176.doc25985.6.676.HGxEOq
在本示例里,我们可以在华东2区创建镜像仓库
registry.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe,
使用dockerfile和docker build命令在本地构建好acs-caffe的gpu版镜像,并推送到上述镜像仓库中。
具体地,可以在集群中的一个ECS节点上创建custom_train_caffe.dockerfile文件,示例内容如下:
FROM bvlc/caffe:gpu
RUN apt-get update && apt-get install -y git vim
RUN mkdir /starter
COPY ./custom_train_helper.sh /starter
WORKDIR /starter
RUN chmod +x custom_train_helper.sh
ENTRYPOINT ["./custom_train_helper.sh"]该镜像基于caffe官方基础镜像bvlc/caffe:gpu,并使用一个自定义的脚本custom_train_helper.sh作为用镜像启动容器时的入口进程。在相同目录下创建custom_train_helper.sh文件供dockerfile文件里构建镜像时使用,内容如下:
#!/bin/bash
default_output_path='/output'
default_remote_volume_path=$DEFAULT_REMOTE_VOLUME_PATH
default_input_path='/input'
# default input dir
if [ -d "$default_remote_volume_path" ] && [ ! -z $default_remote_volume_path ]; then
ln -s $default_remote_volume_path $default_input_path
fi
# default output dir
if [ ! -d "$default_output_path" ]; then
mkdir -p $default_output_path
fi
# exec user's command
eval "$@"
echo "Done training."
# auto persist outputs to user's remote volume
if [ -d $default_remote_volume_path ] && [ ! -z $default_remote_volume_path ]; then
cp -r $default_output_path/ $default_remote_volume_path
else
echo "Cannot find remote data volume $default_remote_volume_path, checkpoints are not persisted remotely."
fi脚本逻辑很简单,主要是在执行具体训练命令的前后期,设置工作目录,和训练日志、结果的备份工作。
接下来,在同级目录下构建自定义镜像。
[root@iZuf654hll72glu42o5qp2Z custom-train]# ls -l
-rw-r--r-- 1 root root 396 1月 15 11:22 custom_train_caffe.dockerfile
-rw-r--r-- 1 root root 952 1月 15 11:16 custom_train_helper.sh
[root@iZuf654hll72glu42o5qp2Z custom-train]# docker build -t registry-vpc.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe:gpu -f custom-train_caffe.dockerfile .
[root@iZuf654hll72glu42o5qp2Z ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry-vpc.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe gpu a654defdd52a 24 hours ago 3.48GB
bvlc/caffe gpu e9d3774d2526 12 days ago 3.39GB然后可以将构建好的镜像registry.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe:gpu推送到之前在华东2区创建的镜像仓库中去。可以参考
https://help.aliyun.com/document_detail/60743.html?spm=5176.doc60765.6.543.JJch13
示例如下:
[root@iZuf654hll72glu42o5qp2Z custom-train]# docker login --username=user@aliyun.com registry-vpc.cn-shanghai.aliyuncs.com
Password:
Login Succeeded
[root@iZuf654hll72glu42o5qp2Z custom-train]# docker push registry-vpc.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe:gpu
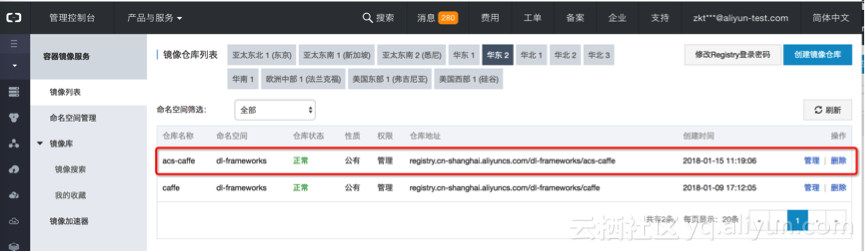
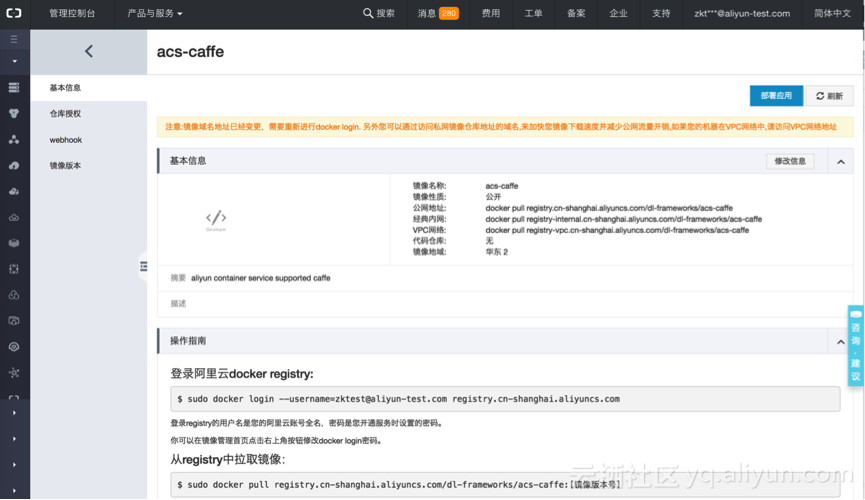
可以在容器镜像服务的控制台https://cr.console.aliyun.com,“管理”这个镜像仓库。可以查看到刚刚推送的caffe镜像的公网、内网地址。
b) 在容器服务控制台(https://cs.console.aliyun.com)进入 “解决方案” - “模型训练” 页面,选择“创建”任务
在配置训练任务的页面表单里填入必要的参数:
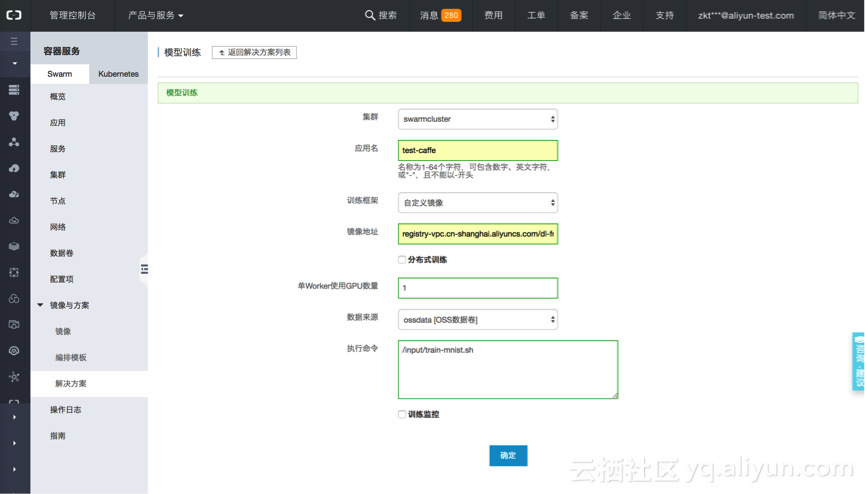
具体的参数意义和值如下:
集群:swarmcluster,指定训练任务运行的集群
应用名:test-caffe,训练任务将作为一个容器应用被部署在容器集群中运行;
训练框架:选择自定义镜像
镜像地址:填入上述推送的caffe镜像地址,如
registry.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe:gpu 。
分布式训练:勾选后可指定Parameter Server架构的分布式训练任务配置
单worker使用GPU数量:单机训练时,任务所使用的GPU卡数量
数据来源:存储训练数据集的数据卷,可支持OSS、NAS和本地数据卷
执行命令:执行模型训练任务的命令。
这里填写的命令,和通常启动训练时执行的命令是一样的。可以执行python程序,如
python /input/tensorflow/mnist_dist_train.py --data_dir=/input/mnist/data/ --train_steps=5000 --log_device_placement=False --log_dir=/output/mnist/log --batch_size=100 --learning_rate=0.01 --sync_replicas=False --num_gpus=2也可以执行shell脚本,比如 "/input/train-mnist.sh"。只要确保shell文件存在于容器内正确的路径下。在任务容器启动时都会以 “sh –c 命令”的形式自动执行。
本示例中用到的训练命令是执行脚本“train-mnist.sh”。该脚本只要提前存放在OSS存储bucket“deeplearning-test”的根目录下。
在使用上述构建的镜像启动容器时,会通过“ossdata”数据卷自动挂载到容器内的“/input”目录下。这样就可以在容器内像执行本地脚本一样运行“train-mnist.sh”了。
示例脚本内容也很简单,会运行Caffe自带的mnist训练例子。
#!/bin/bash
set -e
cd /opt/caffe/
./data/mnist/get_mnist.sh
sh examples/mnist/create_mnist.sh
sh examples/mnist/train_lenet.sh其中 create_mnist.sh用于准备mnist训练数据集,代码如下:
#!/usr/bin/env sh
# This script converts the mnist data into lmdb/leveldb format,
# depending on the value assigned to $BACKEND.
set -e
EXAMPLE=examples/mnist
DATA=data/mnist
BUILD=build/examples/mnist
BACKEND="lmdb"
echo "Creating ${BACKEND}..."
rm -rf $EXAMPLE/mnist_train_${BACKEND}
rm -rf $EXAMPLE/mnist_test_${BACKEND}
$BUILD/convert_mnist_data.bin $DATA/train-images-idx3-ubyte \
$DATA/train-labels-idx1-ubyte $EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}
$BUILD/convert_mnist_data.bin $DATA/t10k-images-idx3-ubyte \
$DATA/t10k-labels-idx1-ubyte $EXAMPLE/mnist_test_${BACKEND} --backend=${BACKEND}
echo "Done."train_lenet.sh脚本用于真正执行Caffe训练任务,其中指定了模型定义为lenet_solver。代码如下:
#!/usr/bin/env sh
set -e
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt $@
训练监控:目前只支持基于Tensorboard的训练监控可视化服务,本例中先不使用。如果勾选,会自动部署Tensorboard服务,并与下面指定的日志存储路径自动关联。这样,训练代码中输出的日志可以被Tensorboard读取。
训练日志路径:用于存储训练过程中输出的日志和结果。请在训练代码中使用同样的路径。
“确定”后,训练任务将被作为容器应用创建,自动调度到合适的GPU节点,并开始执行训练命令
c) 查看训练容器运行详情
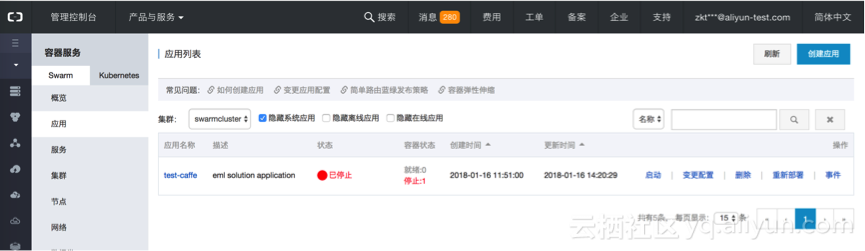
训练任务创建后,会以应用容器的方式运行。在容器服务控制台,进入“应用”页面,可以找到前面创建的任务“test-caffe”。
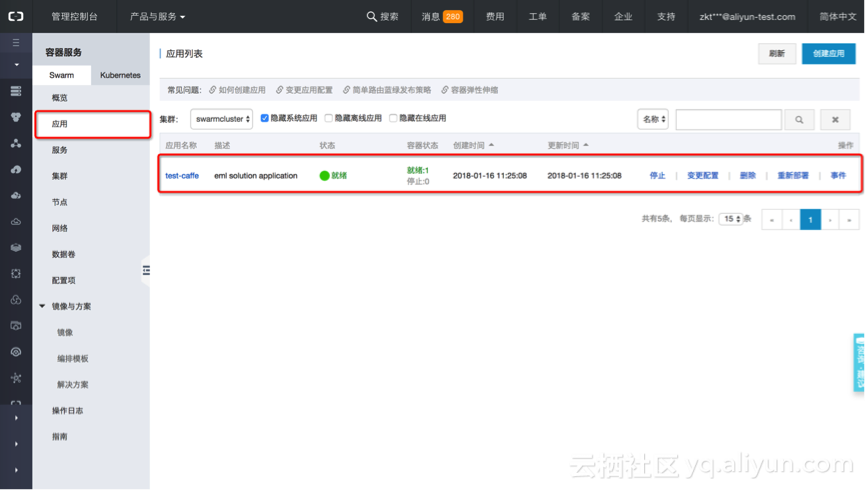
可以点击应用名,查看更多任务执行的状况。
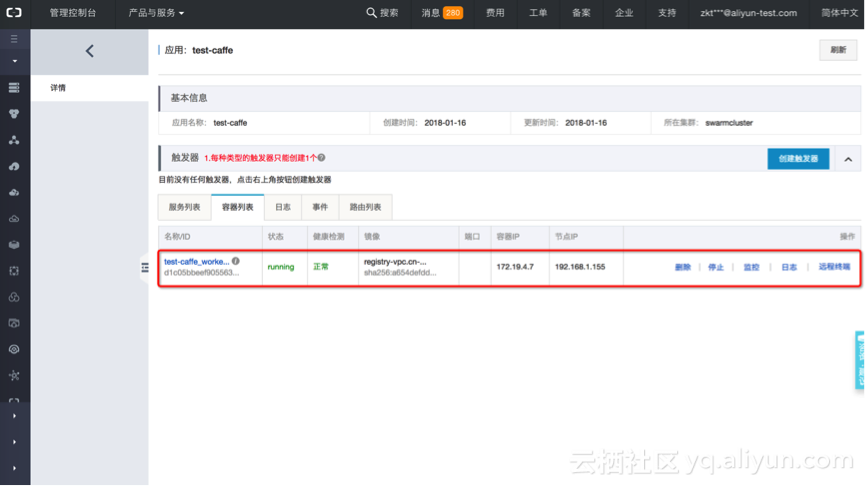
可以看到上述任务有一个容器“test-caffe_worker1”在运行,查看该容器的运行的节点位置,以及查看资源监控和日志信息。也可以通过简单的web远程终端,直接进入该容器内部。效果和通过SSH进入容器一样。
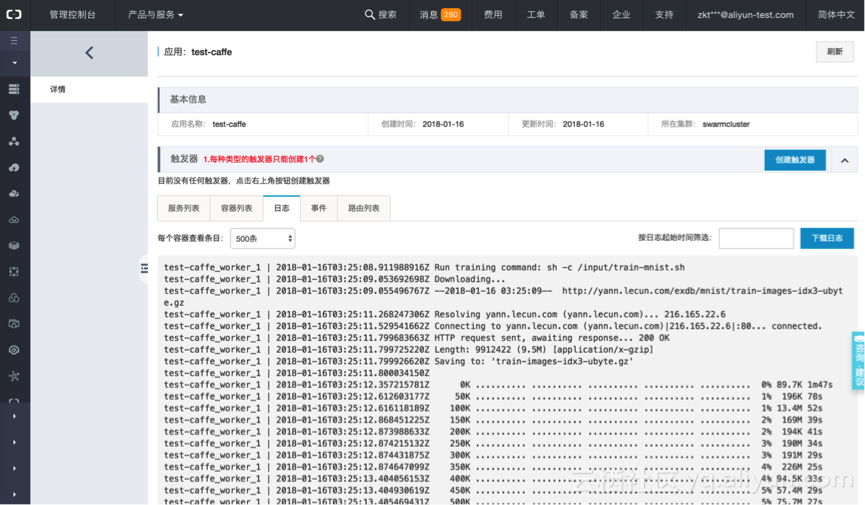
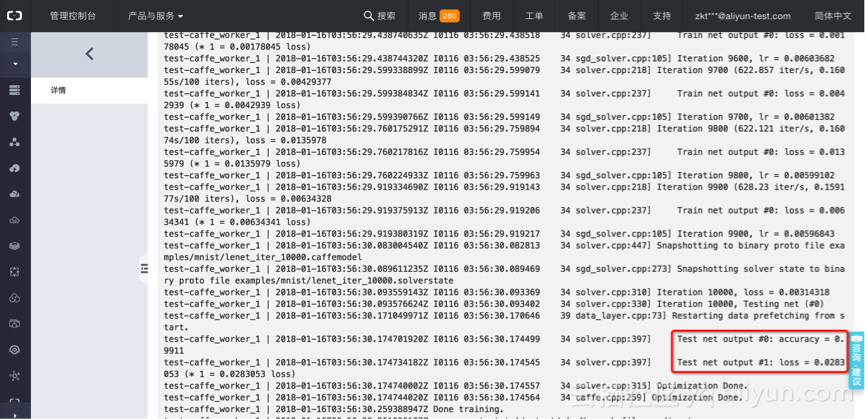
训练过程输出的日志会实时地显示在对应的容器名下。
通过简单的web远程终端进入容器内部操作。
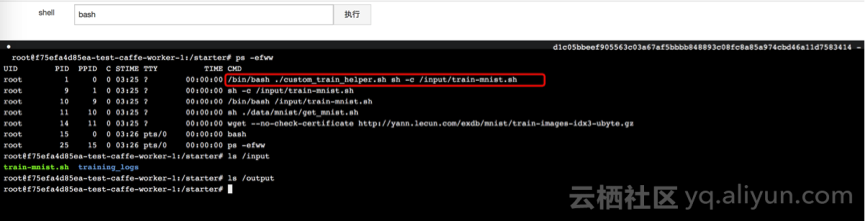
根据训练任务的复杂程度,在等待一段时间后,训练结束。任务容器会自动退出,释放所占用的GPU等资源。
至此,通过自定义镜像的方式,用户可以使用容器服务简单、快速地运行基于Caffe等任何深度学习框架的模型训练。训练任务调度、计算资源分配、GPU使用率优化、数据存储的集成、集群管理,监控等工作都不需要额外的投入。