今天,华盛顿大学陈天奇团队开发的TVM发布了更新,不需要写任何JavaScript代码,直接就能把深度学习模型编译到WebGL/OpenGL,然后在浏览器运行。
深度学习离不开TensorFlow,MXNet,Caffe和PyTorch这些可扩展深度学习系统,但它们大多专门针对小范围的硬件平台(例如服务器级GPU)进行优化,要适应其他平台需要付出相当大的工程成本和费用,这对深度学习系统的灵活部署提出了挑战。
大量不同的深度学习框架(编程语言),越来越多的硬件架构,两者之间需要一个桥梁。TVM框架正是为此而生,旨在让研究人员和开发者能够在各种不同的硬件,从手机、嵌入式设备到低功耗专用芯片这些不同的系统上,快速轻松地部署深度学习应用,而且不会牺牲电池电量或速度。
TVM是神经网络和硬件后端之间一个共同的层(a common layer),无需为每一类设备或服务器建立一个单独的基础架构,该框架使开发人员能够在多种不同的硬件设备上快速轻松地部署和优化深度学习系统,帮助研究人员快速优化新算法的实现,验证新的思路,还有助于促进深度学习研究领域的硬件和软件协同设计。
新发布OpenGL / WebGL后端支持
TVM已经支持多个硬件后端:CPU,GPU,移动设备等......这次我们添加了另一个后端:OpenGL / WebGL。
OpenGL / WebGL使我们能够在没有安装CUDA的环境中利用GPU。目前,这是在浏览器中使用GPU的唯一方式。
这个新的后端允许我们以一下3种方式使用OpenGL / WebGL:
- 本地OpenGL:我们可以将深度学习模型编译成OpenGL,并直接在本地机器上运行,完全只使用Python。
- 带有RPC的WebGL:我们可以将深度学习模型编译为WebGL,并将其作为一个共享库导出,并带有JavaScript主机代码和WebGL设备代码。然后,我们可以通过RPC将这个共享库部署到TVM JavaScript运行时系统,在浏览器内运行。
- 带有静态库的WebGL:我们可以将深度学习模型编译为WebGL,将其与TVM JavaScript运行时系统连接,并导出整个包。然后,可以在浏览器的网页中运行模型,不需要依赖项。详细流程如图1所示。
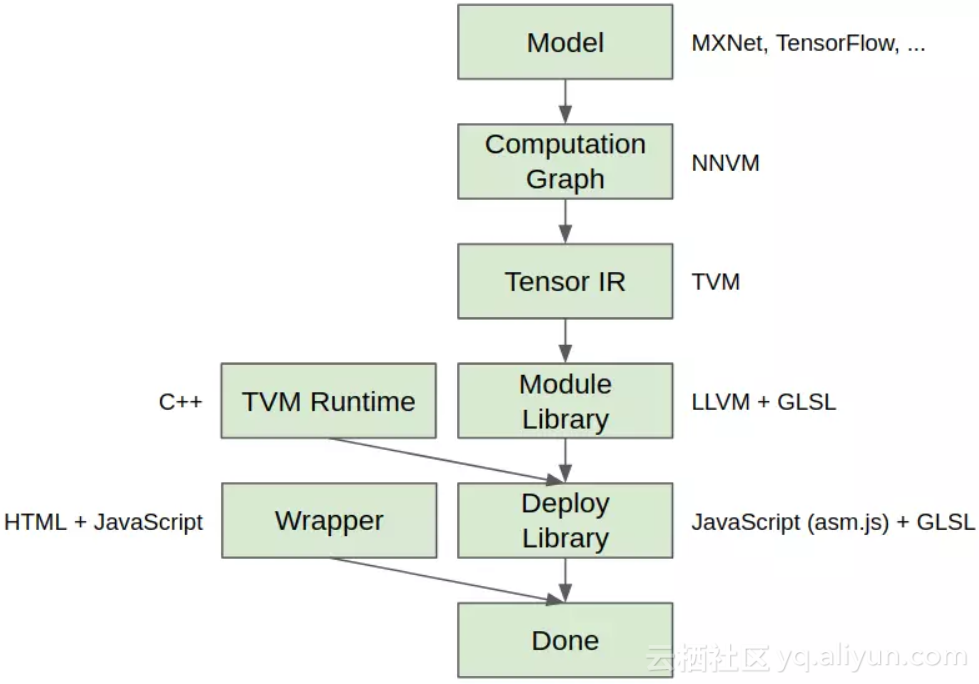
图1
以上三种方式的演示代码:https://github.com/dmlc/nnvm/blob/master/tutorials/from_mxnet_to_webgl.py
这与X有何不同?
在浏览器上运行神经网络并不是非常新奇的事。Andrej Karpathy提出的ConvNetJS,以及Google的DeepLearning.JS都是这样的想法。
那么使用WebGL的TVM有什么独特之处?最大的区别是TVM中的操作内核是自动编译的,而不是人工编译的。如图2所示,TVM使用统一的AST定义内核,并将其编译为不同平台上的代码。
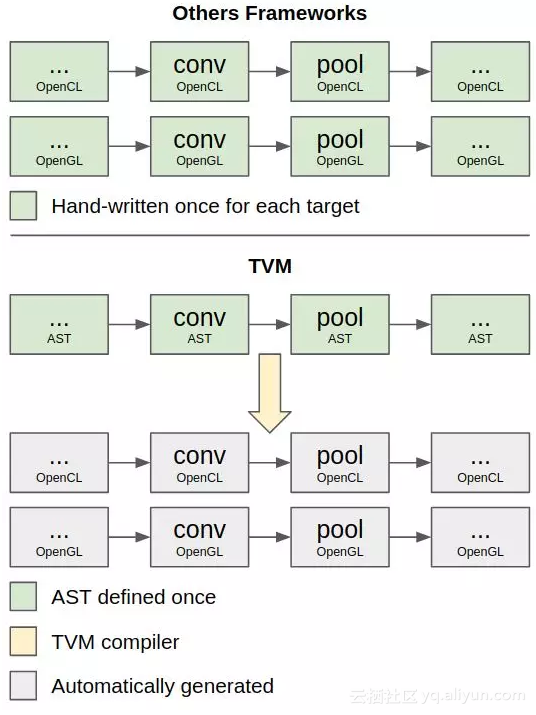
图2
这意味着:
- 你不需要编写大量附加代码,就可以将现有模型部署到WebGL。NNVM / TVM模型定义对于所有target都是相同的,因此你只需将其编译到新的target。
- 如果要添加新的操作系统内核,你只需要在TVM中定义一次,而不用为每个target实现一次。你不需要知道如何编写GLSL代码来向WebGL添加新的操作系统内核!
Benchmark
这里,我们为一个典型的工作负载执行基准测试:使用resnet18进行图像分类。
我使用的是有5年历史的8核英特尔®酷睿™i7-3610QM笔记本电脑,以及一个GTX650M。
在这个基准测试中,我们从Gluon模型库里下载了resnet18模型,并对猫的图像进行端到端分类。我们只测量了模型执行时间(不包含模型/输入/参数的加载),并且每个模型运行100次以取得平均值。结果如图3所示。
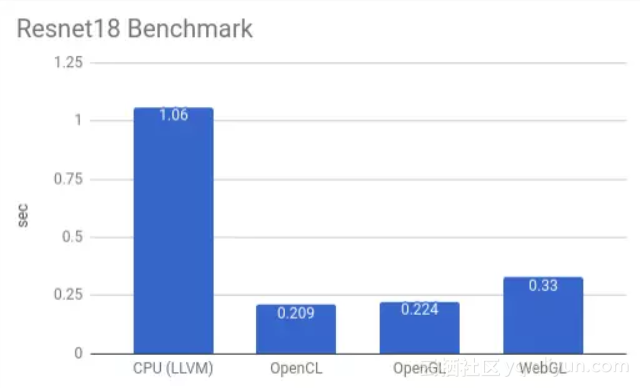
图3
该基准测试在以下4种不同的设置下运行:
- CPU(LLVM):模型被编译为LLVM IR和JIT’ed,完全在CPU上运行。
- OpenCL:模型被编译成OpenCL。还有一些glue code被编译到LLVM,负责设置和启动OpenCL内核。然后我们在本地机器上运行。
- OpenGL:与OpenCL相同,但编译为OpenGL。
- WebGL:glue code被编译为LLVM,并使用Emscripten转换为JavaScript。设备代码被编译为WebGL。我们在Firefox上执行模型。
从上面的结果可以看出,TVM OpenGL后端与OpenCL具有相似的性能。有趣的是,浏览器的WebGL版本并不比桌面OpenGL慢很多。考虑到主机代码是JavaScript,这很令人惊讶。这可能是由于Emscripten生成了asm.js,可以在Firefox中显著优化。
这是将深度学习模型自动编译到Web浏览器的第一步。随着我们将优化带入TVM堆栈,可以期待更多性能改进。
TVM:一个端到端的优化堆栈
可扩展框架,如TensorFlow,MXNet,Caffe和PyTorch是目前深度学习领域最流行和实用的框架。但是,这些框架只针对范围较窄的服务器级GPU进行了优化,如果要将工作负载部署到其他平台(例如手机,嵌入式设备和专用加速器FPGA、ASIC等),就需要大量费力的工作。我们提出一个端到端的优化堆栈TVM,具备图形级和运算符级的优化,以为不同硬件后端提供深度学习工作负载的性能可移植性。我们讨论了TVM解决深度学习优化的挑战:高级操作符融合、跨线程的低级内存重用、任意硬件基元的映射,以及内存延迟隐藏。实验结果表明,TVM在多个硬件后端的性能可与现有支持低功耗CPU和服务器级GPU的最优库相媲美。我们还通过针对基于FPGA的通用深度学习加速器的实验,展示了TVM对新的硬件加速器后端的适应能力。该编译器基础结构已经开源。
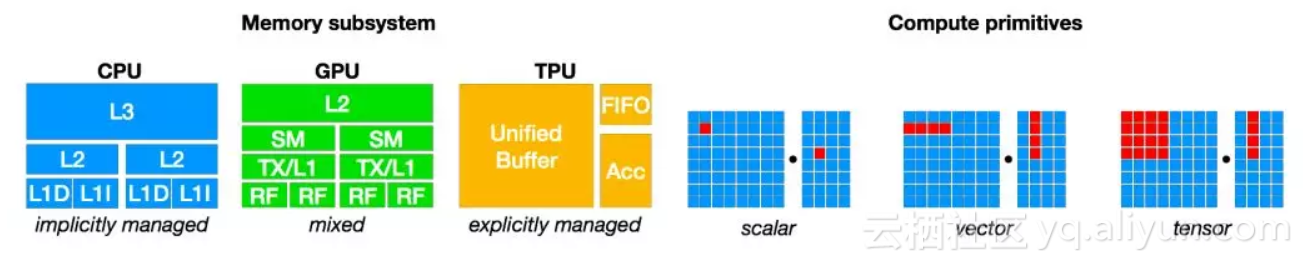
图4:CPU、GPU与TPU类的加速器需要不同的片上存储架构和计算基元。在生成优化代码时我们必须考虑这个问题。
我们提出TVM,一个端到端的优化编译器堆栈(如图5所示),它能降低和微调深度学习的工作负载,以适应多种硬件后端。TVM的设计目的是分离算法描述、schedule和硬件接口,这个原则受到Halide的compute/schedule分离的想法的启发,而且通过将schedule与目标硬件内部函数分开进行了扩展。这一额外的分离可以支持新的专用加速器及其相应的新的内部函数。
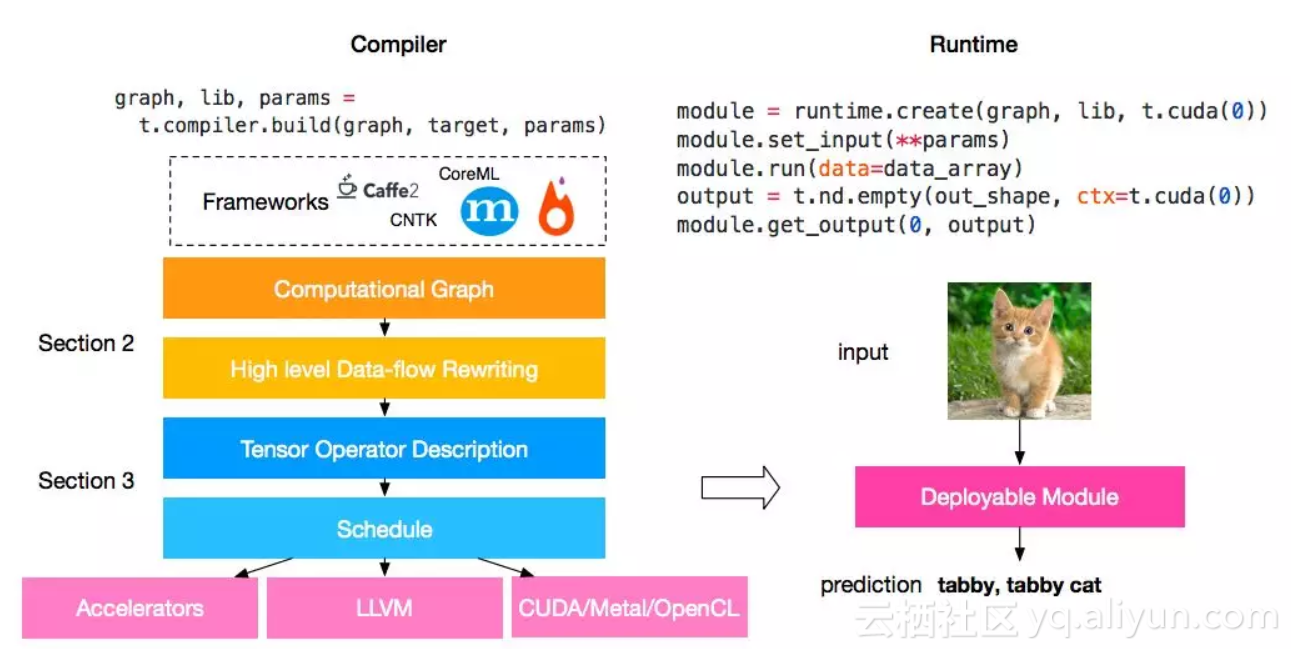
图5:TVM 堆栈图。目前的堆栈支持多种深度学习框架以及主流 CPU、GPU 以及专用深度学习加速器。
TVM具有两个优化层:一个是计算图优化层;另一个是带有新的schedule primitives的张量优化层。结合这两个优化层,TVM可以从大多数深度学习框架中获取模型描述,执行高级和低级优化,并为后端生成特定硬件的优化代码,例如Raspberry Pi,GPU和基于FPGA的专用加速器。本研究的贡献如下:
![]() 我们的编译器可以生成可部署的代码,其性能可与当前最优的库相媲美,并且可适应新的专用加速器后端。
我们的编译器可以生成可部署的代码,其性能可与当前最优的库相媲美,并且可适应新的专用加速器后端。
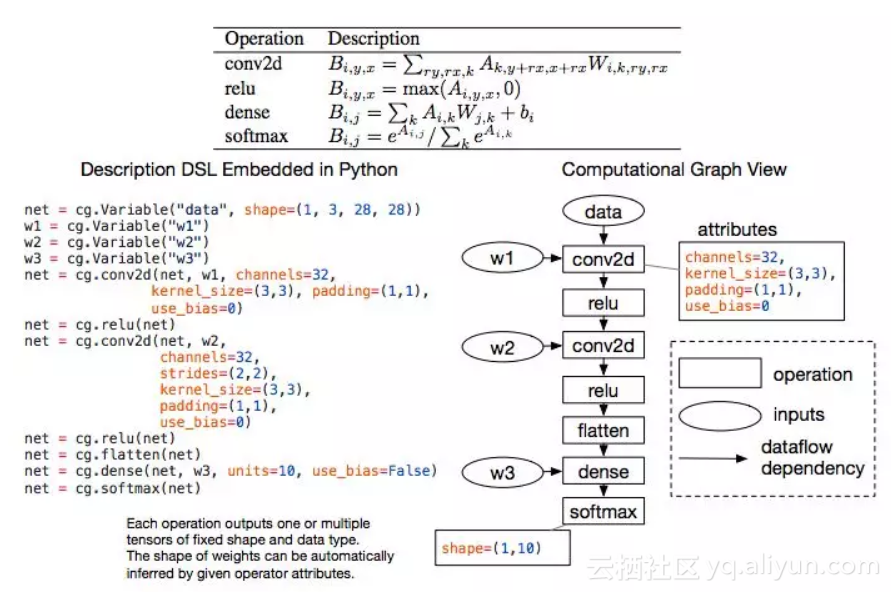
图6:两层卷积神经网络的计算图示例。图中的每个节点代表一次运算,消耗一个或多个tensor,并产生一个或多个tensor。
更多细节,请阅读论文:https://arxiv.org/pdf/1802.04799.pdf
XLA v.s. TVM:深度学习“中间表示”之争
从结构上看,TVM是一个完整的深度学习中间表示(IR)堆栈的基础层(base layer),提供了一个可重用的工具链,用于编译高级神经网络算法,生成适合特定硬件平台的低级机器代码。
借鉴构建编译器的方法,团队构建了一个两级的中间层,由NNVM(用于任务调度和内存管理的高级IR)和TVM(优化计算内核的低级IR)。 TVM随附一套可重复使用的优化库,能够随意调整,适应从可穿戴设备到高端云计算服务器的各种硬件平台的需求。
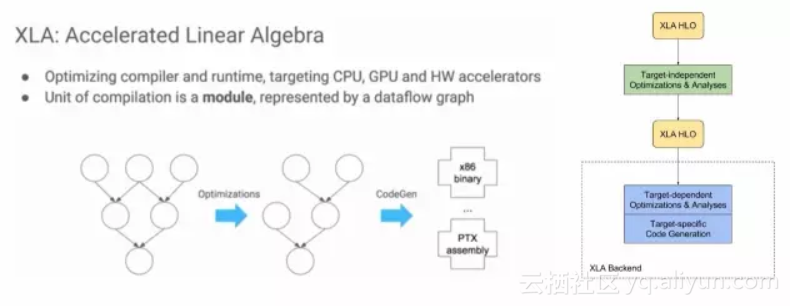
谷歌的XLA也是使用两层优化的结构,但XLA只针对TensorFlow。相比之下,TVM则试图成为一个开放的接口。
不仅如此,陈天奇之前在回答知乎提问“如何评价陈天奇的模块化深度学习系统NNVM?”时表示,“TVM和已有的解决方案不同,以XLA作为例子,TVM走了和目前的XLA比更加激进的技术路线,TVM可以用来使得实现XLA需要的功能更加容易 ”。
根据TVM博客,现在已经做了如下更新:

在最近统计的深度学习开源框架排名中,TensorFlow均位于第一,毫无争议。但未来,中间表示(IR)将成为深度学习框架之间竞争的关键。
原文发布时间为:2018-03-13
本文作者:肖琴、文强
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号
