热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
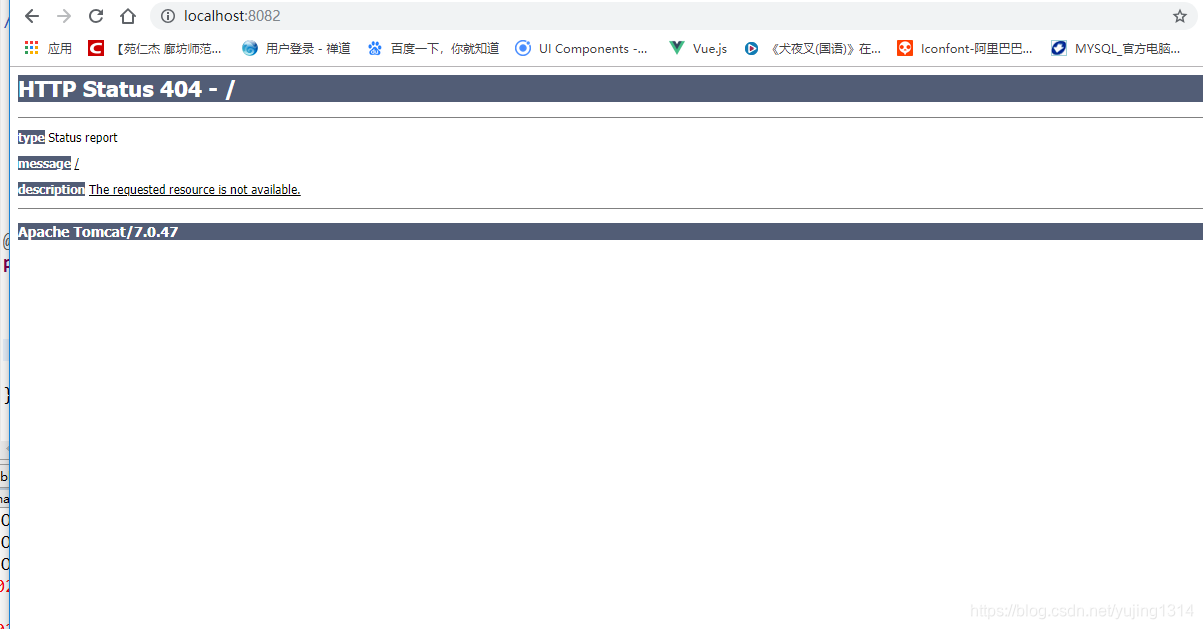
HTTP Status 404(The requested resource is not available)
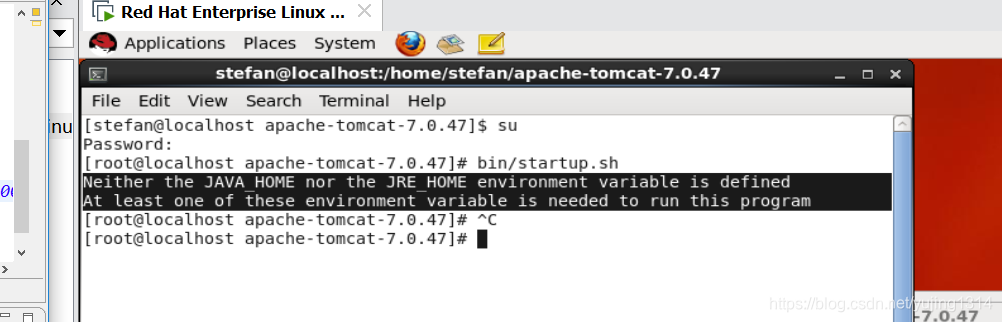
Linux启动tomcat报错:Neither the JAVA_HOME nor the JRE_HOME environment variable is defined
Java基础&API(3)
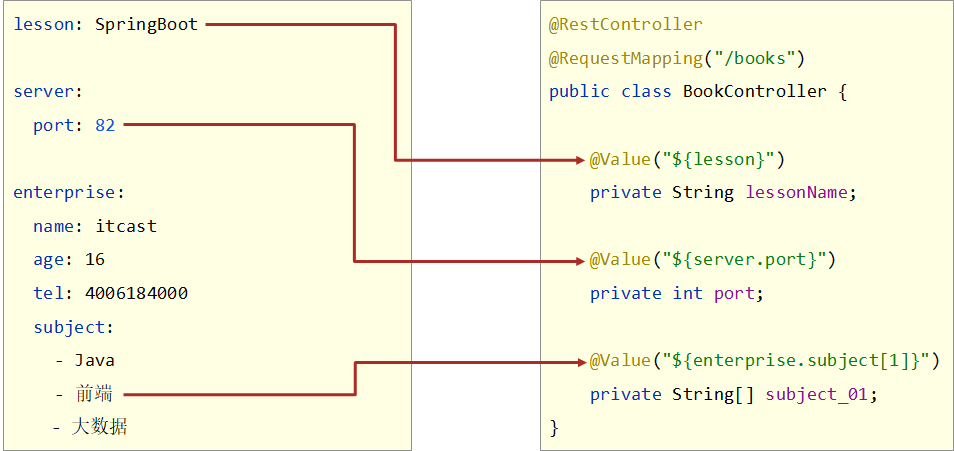
全套SpringBoot讲义01-二
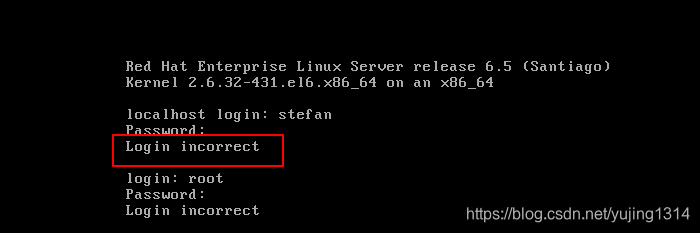
linux 登录时一直显示Login incorrect
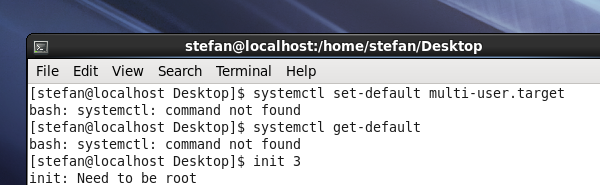
Linux 如何关闭防火墙(开启管理员权限)
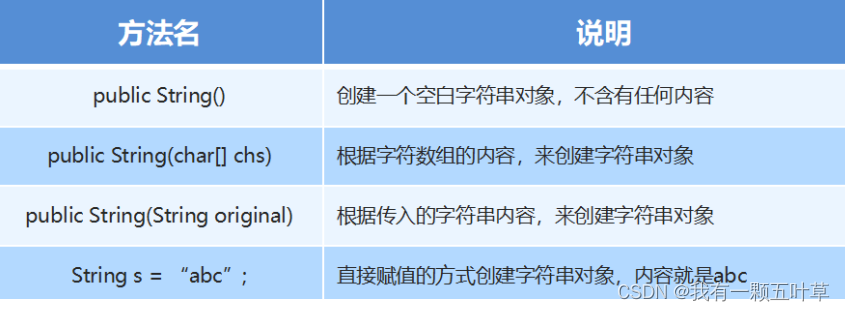
Java基础&API(2) String、StringBuilder详解
使用tomcat插件启动项目的问题
Java基础&常用API(1)
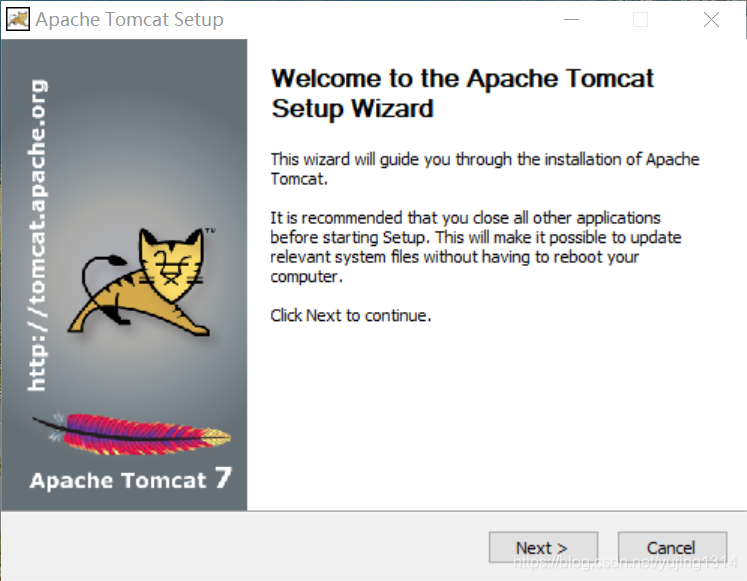
Tomcat7 的安装和配置
【eclipse】pom.xml 红叉的解决办法
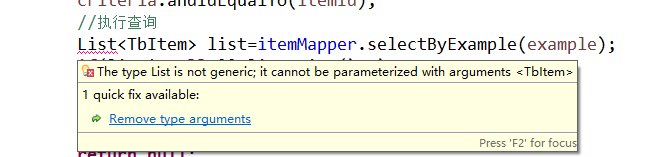
The type List is not generic; it cannot be parameterized with arguments <TbItem>
代码之美:从功能实现到艺术创作
Java基础&面向对象&继承&抽象类
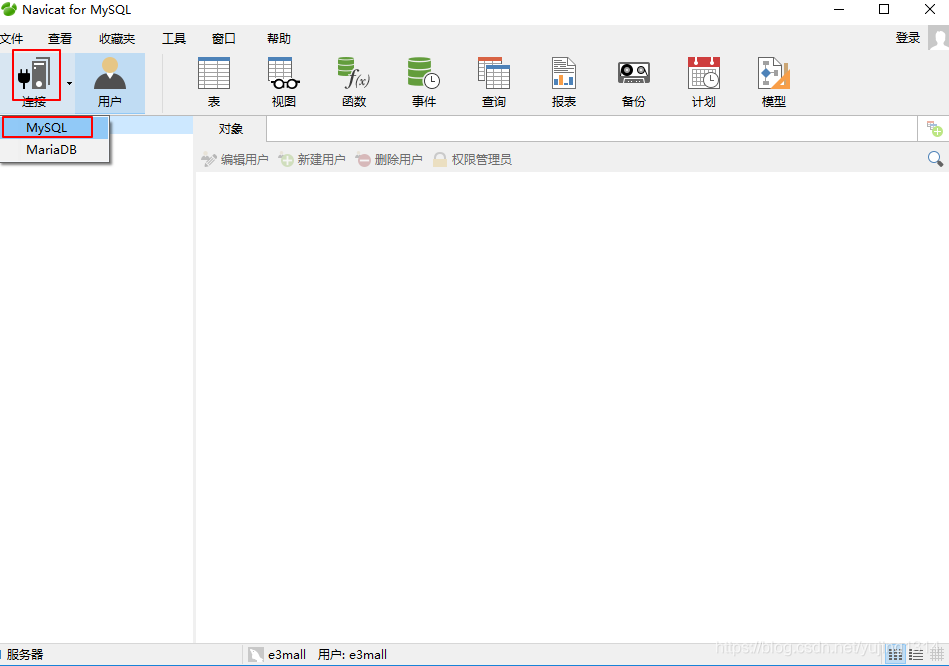
使用Navicate连接Mysql过程详解
网络安全与信息安全:防御前线的关键技术与策略
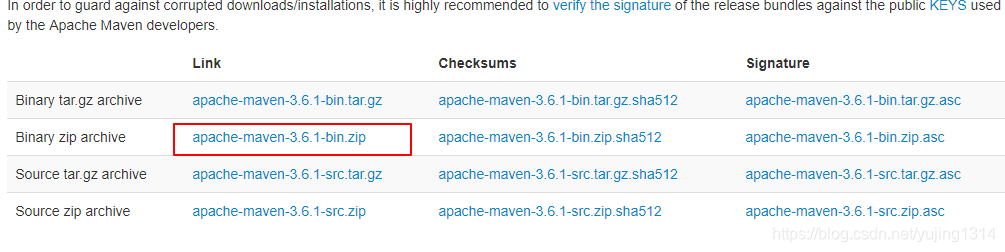
Maven安装配置(Windows10)
构建高效机器学习模型的最佳实践
构建高效自动化运维系统:策略与实践
CoreException: Could not get the value for parameter compilerId for plugin execution default-compile
Java基础&方法
网络安全与信息安全:防御前线的技术与意识
全套SpringBoot讲义01-一
云端防御战线:云计算与网络安全的协同进化
eclipse的详细安装教程
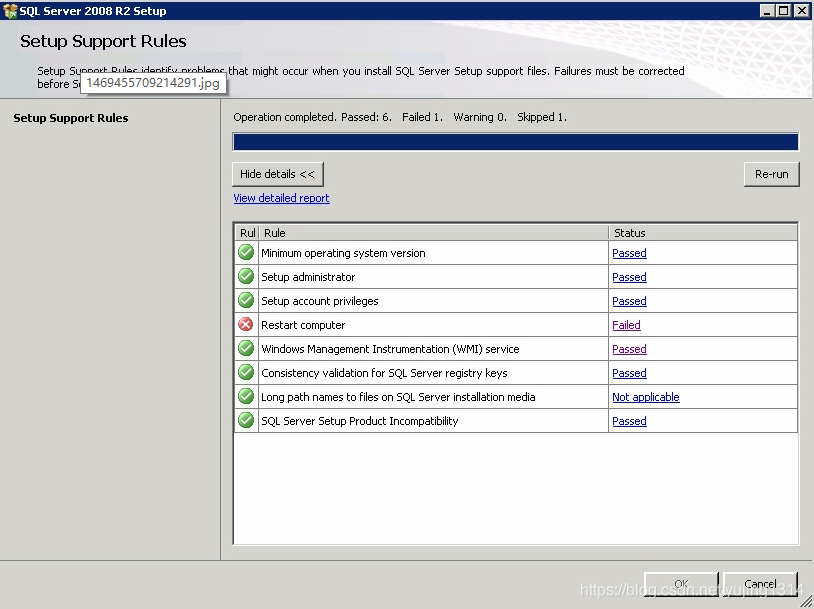
SQL Server2008 安装报错Restart computer failed的解决办法
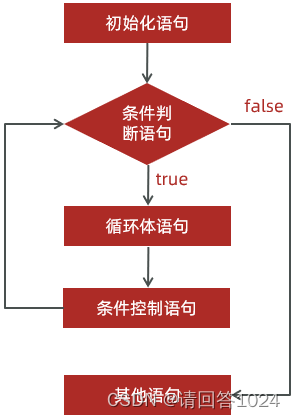
Java基础&循环语句
ionic4 路由跳转刷新实战
[Java 基础] Java修饰符
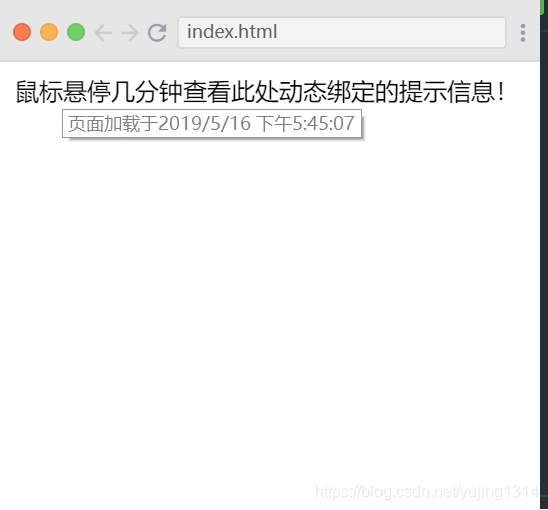
【Vue】小例子入门以及生命周期探讨
[设计模式Java实现附plantuml源码~行为型]定义算法的框架——模板方法模式
【Java基础】面向对象和内存分析
Java基础&选择语句
VSCode 开发Vue必备插件
[设计模式Java实现附plantuml源码~行为型] 对象状态及其转换——状态模式
Vue 如何新建一个项目(如何安装依赖)
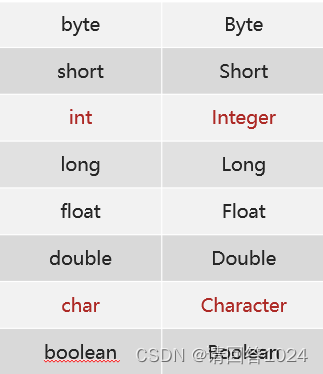
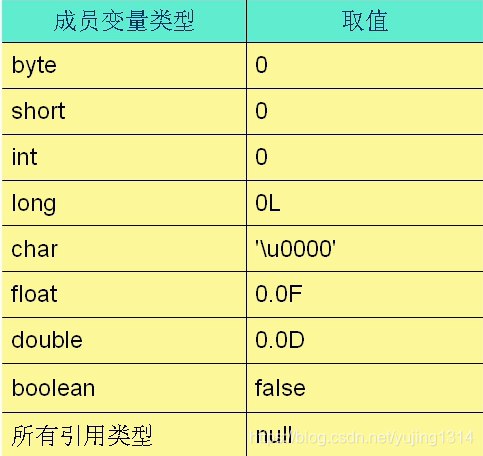
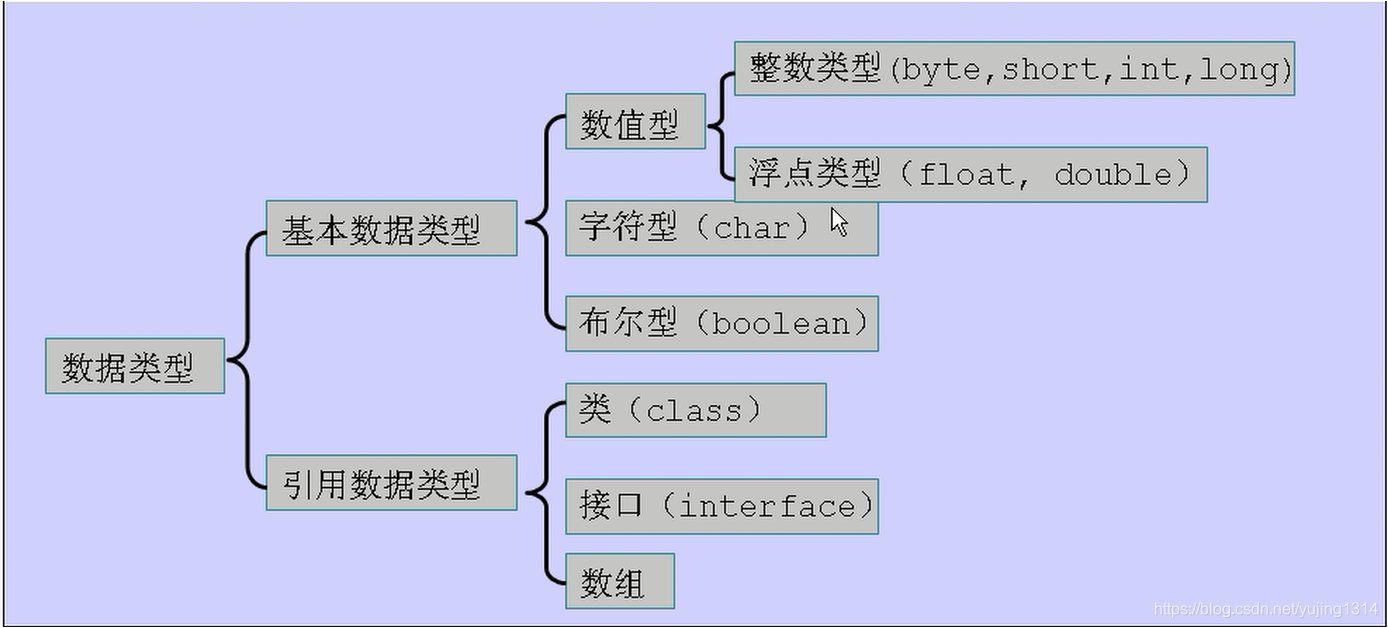
【Java基础】数据类型以及程序执行过程浅析
Java基础&运算符
掌握MySQL数据库这些优化技巧,事半功倍!
高级运维工程师的打怪升级之路
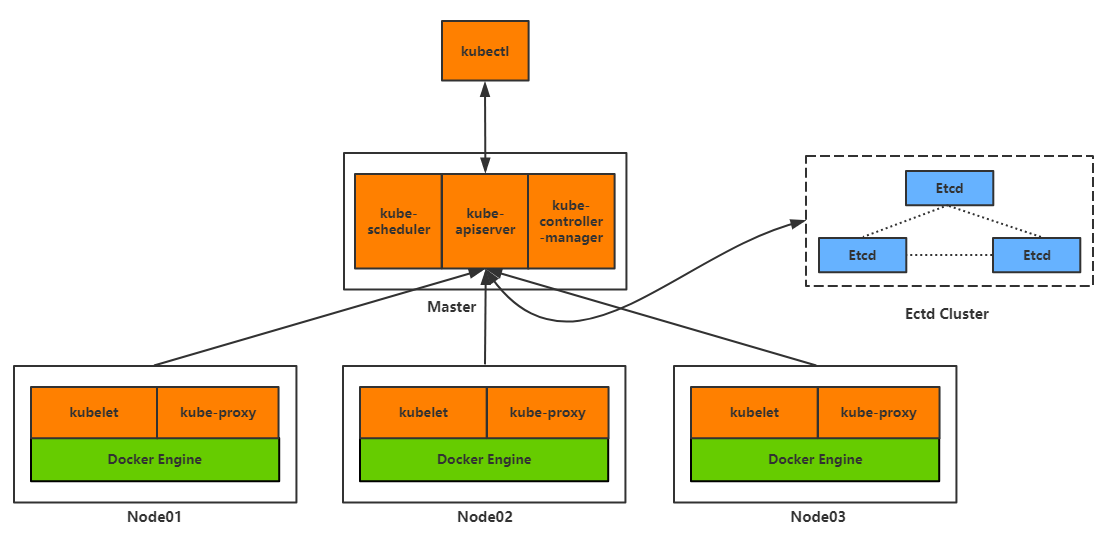
Kubernetes(K8S)集群管理Docker容器(部署篇)
ionic 4 将数据存入缓存并读取(附加清空缓存)
Java入门及环境变量
Kubernetes(K8S)集群管理Docker容器(概念篇)
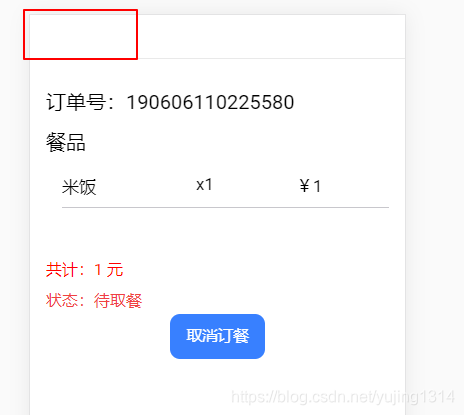
ionic 4 点击按钮跳转页面传值并刷新
[AIGC] 深入理解Flink中的窗口、水位线和定时器