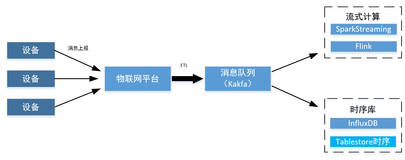
OTS在业务停写的情况下,可以通过DATAX工具对OTS数据的全量迁移。本文描述了在进行业务割接的情况下,ots数据的全量迁移配置方法,以及数据校验方法。
1 OTS数据迁移方法
1.1 工具环境要求
tablestore客户端工具机:在本地安装表格存储客户端管理工具,提供图形化的操作界面,用于创建、更新和删除数据表。
datax数据迁移工具机:安装python、jdk 和datax。Jdk版本需要1.7及以上,python版本推荐2.6.x。
以上两台工具机需要跟老、新环境的OTS实例开通防火墙策略的80端口。
1.2 迁移前提条件
1) 源ots停止新数据的写入。
2) 用datax迁移前,确定好ots表结构的primary key及其他所有的属性列。
1.3 OTS数据迁移割接步骤
ots采用datax进行数据迁移,在ots源停止新数据写入的情况下,把源库的表的数据全部迁移到新库。
1.3.1 目标端创建ots表
通过TableStore客户端创建新库对应的数据表,表结构如下:
|
|
列名称 |
类型 |
| primaryKey |
PrimaryKeyName |
string |
注意:
ots创建表结构时只创建primarykey,属性列不需要创建。
1.3.2 配置datax任务
datax的迁移配置ots_migration.json的配置内容如下,在迁移数据的配置中,需要列全所有的属性列。
| { "job": { "setting": { "speed": { "channel": "5" } }, "content": [ { "reader": { "name": "otsreader", "parameter": { "endpoint":"http://xxx.vpc.ots.yyy.com/", "accessId":"src_accessId", "accessKey":"src_ accessKey ", "instanceName":"KHGL-VPC2-01", "table":"tablename", "column" : [ {"name":" PrimaryKeyName "}, {"name":"createId"}, {"name":"createUser"}, {"name":"createName"}, {"name":"searchTime"}, {"name":"state"}, {"name":"stateDesc"}, {"name":"createTime"} ], "range": { "begin":[{"type": "INF_MIN"}], "end":[{"type":"INF_MAX"}] } } }, "writer": { "name": "otswriter", "parameter": { "endpoint":"http://xxx.vpc.ots.yun.zzz.com/", "accessId":"dest_accessId", "accessKey":"dest_accessKey", "instanceName":"RHYKF-OTS-VPC1-1", "table":"tablename", "primaryKey" : [ {"name":"zCodeMD5", "type":"string"} ], "column" : [ {"name":"createId","type":"string"}, {"name":"createUser","type":"string"}, {"name":"createName","type":"string"}, {"name":"searchTime","type":"string"}, {"name":"state","type":"string"}, {"name":"stateDesc","type":"string"}, {"name":"createTime","type":"string"} ], "writeMode" : "PutRow" } } } ] } } |
1.3.3 执行datax任务
执行datax命令
| nohup python datax.py ots_migration.json>ots_result & |
2 OTS数据校验方法
2.1 数据校验的场景
通过datax分别把源和目标ots数据导出为文本文件,可以首先对两个导出数据文件进行md5sum比较,如果md5sum的返回值不同,需要根据数据割接窗口的时间要求和数据一致性要求进行如下两点操作。如果对数据一致性要求较高,需要对两个数据文件进行diff比较。如果数据文件较大,此校验方法耗时会比较长,可简单对两个数据文件的行数进行对比。
2.2 数据校验的方法
2.2.1 通过diff进行数据一致性校验
将源和目标端的全量数据导出到第三方服务器上,通过diff方式对比源和目的端的数据,来进行数据校验。
通过diff的方式,对两个数据文件,进行逐行对比。由于datax是按照顺序进行数据的导出,不要求事先对数据文件进行排序。
l Diff使用方法
| diff file1 file2 |
2.2.2 通过行数统计的方法进行数据校验
将源和目的端的全量数据导出到第三方服务器上,通过行数统计的方式对比源和目的端的数据,具体操作命令通过datax把ots的源和目标数据分别导出文本,分别从datax的导出日志中获取到ots源和目标数据的行数。
示例如下:其中读出记录总数就是ots数据行数。
| 2017-11-24 22:05:12.023 [job-0] INFO JobContainer - 任务启动时刻 : 2017-11-24 21:31:10 任务结束时刻 : 2017-11-24 22:05:12 任务总计耗时 : 2041s 任务平均流量 : 4.00MB/s 记录写入速度 : 82053rec/s 读出记录总数 : 167390000 读写失败总数 : 0 |
3 OTS数据迁移回滚方法
由于OTS不支持增量迁移方法,一旦涉及到业务上线之后,OTS已经有数据写入,但需要进行业务回滚的场景,需要依照正向迁移的方式将ots数据进行全量回切。