背景
大部分我们的数据处理作业在完成计算以后,都希望能够把结果可视化的展示出来,形成类似每日报表这样的东西,供大家直观的查看。
或者能有类似阿里双11那种实时的数据大屏效果就更好了
如果自己去做一个类似的数据可视化的系统会非常复杂,我这里要介绍的就是E-MapRediuce的处理结果,如何通过阿里云已有的DataV工具来进行展示。
它有如下的一些特点:
-
可视化数据图表是实时的。
只要数据一发生变化,图表就会立刻变化。 -
权限控制
可以限制只有主子账号可以查看,同时也能指定报表公开给所有人。
1. 计算数据
我这里会列举2个场景作为示范,一个是离线的场景,报表数据每天计算一次,另一个是在线的流式场景,报表数据每10分钟更新一次,介绍他们大致的处理方式
a) 离线场景
示例场景介绍:
用户通过日志服务(SLS)将服务器的访问日志收集上来,然后投递到OSS,并起一个E-MapReduce集群来进行处理。分析出当天的pv,uv或其他的业务指标。
这个处理过程请参考这里使用Hive处理服务器日志
最终能得到需要的结果hive表。
b) 流式场景
示例场景介绍:
用户通过日志服务(SLS)将服务器日志收集上来,然后在E-MapReduce集群中,运行一个Spark Streaming作业,对数据进行业务分析。
这个处理过程的详细说明将在下一篇中详细介绍。
2. 报表数据导入数据库
目前DataV还不能直接支持使用HDFS数据,但是可以支持API接口和RDS(Mysql)的数据源。我们这里选用RDS作为我们的数据源,当然如果你有自己的Mysql数据也可以直接使用
创建表
我们需要在数据库中创建一张表,我们示范创建一张简单的pv表,如下
CREATE TABLE `pv` (
`page` varchar(32) NOT NULL,
`amount` int(11) DEFAULT NULL,
PRIMARY KEY (`page`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8其中page是用户访问的页面的id标号,amount是该页面被访问的次数。
主键是page。
a)离线场景
经过上面的离线计算我们得到了一张Hive表,我们使用Sqoop将他导入到RDS中去。
sqoop export --connect jdbc:mysql://{ip}:3306/{dbname} --username {user} --password {pwd} --table {tablename} --export-dir {hdfs_dir} --input-fields-terminated-by '\001'这里其他的参数都好理解,有2个需要说明下:
hdfs_dir
这个是Hive对应的hdfs路径,我们如何从Hive表中得到呢?
我们在hive中使用如下命令即可查询到表对应的HDFS路径
desc extended tablename;结果如下,其中的location后面的值就是我们需要的路径了:
--input-fields-terminated-by '001'
这个是默认的Hive都会使用 001 来做分割符,所以我们需要把每行用这个分割成多个字段,然后保存到RDS中。分割出来的每一个字段对应RDS中表的每一列
b)流式场景
流式场景就是直接在Spark Streaming中直接写数据库,后续我们会写一个文章来详细介绍这个过程。
3. 创建并配置DataV
完成了上面的数据库准备和数据导入,现在我们就可以开始展示这些数据了。
登录DataV
i 创建数据源
在首页先创建一个数据源,点击数据源新增
这里我选择rds,其实mysql和rds是一样的,你如果是自己的mysql也是一样配置
创建完成以后会看到一个数据源
ii 创建项目
然后我们新建一个项目,由于默认的几个都是很复杂的图,我们只需要一个简单的,所以你需要手动的删除掉这些用不上的组件。这会花费一些时间。
iii 设置页面
完成以后,我们先设置屏幕的大小,点击右侧的“页面设置”,设置屏幕大小
考虑有各种不同的页面,我们先设置小一点,设置为宽度:800,高度:600
然后“缩放方式”选择:全屏铺满, 不过会导致比例有点失真,你可以根据你的实际情况进行调整。
iv 添加图标并设置
我们从常规图表中选中“梯形柱状图”,并进行拉伸,扩大到适合的大小。
接着,设置我们的数据绑定到这个图上,点击右侧的数据
选择“数据源类型”:数据库
选择“选择数据库”:一开始我们创建的那个数据源
在“SQL”中写语句,以我们的示例为例,我们的数据库中的pv表有2个字段一个是page,代表用户的访问页面id,一个是amount,代表页面被访问的次数。
我们看到梯形柱状图需要x,y两个坐标轴的数据,x对应类目也就是我们的页面id,y对应值,也就是访问量,我们使用如下的sql来
select page as x, amount as y from pv order by amount desc limit 10;这样就把所有访问页面的前十给展示出来了
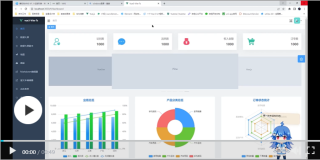
类似如下的效果:
然后,如果你的数据是动态更新的,那么你可以设置下面的
“自动更新”,设置一个合适的频率来更新图标,每当数据变化就可以立刻看到。
v 权限设置
默认情况下,这个图表只可以被主子账号访问。
如果要被所有人访问,在屏幕的右上,有一个分享按钮,点击打开后会产生一个公开的访问地址,所有人都可以访问