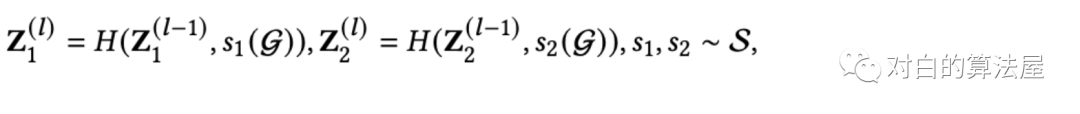推荐系统虽然有很多的技术 但是 总的来说可分为两大类
1. 基于内容的推荐(Content-Based System) 这类系统主要考察时推荐的项(Item)的性质。
2. 协同过滤系统(Collaborative-Filtering System) 这类系统通过计算用户与项之间的相似度来推荐项。
基于内容的推荐:
实现的步奏
1. Item Representation:为每个item抽取出一些特征(也就是item的content了)来表示此item;
2. Profile Learning:利用一个用户过去喜欢(及不喜欢)的item的特征数据,来学习出此用户的喜好特征(profile);
3. Recommendation Generation:通过比较上一步得到的用户profile与候选item的特征,为此用户推荐一组相关性最大的item。

第一步对应Content Analyzer 第二步对应Profile Learner 第三步对应Filtering Component
具体算法推荐算法举例 Profile Learning 步奏用
k-Nearest Neighbor,简称kNN (最近邻方法)
Rocchio算法
Decision Tree,简称DT (决策树算法)
Linear Classifer,简称LC (线性分类算法)
Naive Bayes,简称NB (朴素贝叶斯算法)
基于内容的推荐(CB)的优点
1. 用户之间的独立性(User Independence):既然每个用户的profile都是依据他本身对item的喜好获得的,自然就与他人的行为无关。而CF刚好相反,CF需要利用很多其他人的数据。CB的这种用户独立性带来的一个显著好处是别人不管对item如何作弊(比如利用多个账号把某个产品的排名刷上去)都不会影响到自己。
2. 好的可解释性(Transparency):如果需要向用户解释为什么推荐了这些产品给他,你只要告诉他这些产品有某某属性,这些属性跟你的品味很匹配等等。
3. 新的item可以立刻得到推荐(New Item Problem):只要一个新item加进item库,它就马上可以被推荐,被推荐的机会和老的item是一致的。而CF对于新item就很无奈,只有当此新item被某些用户喜欢过(或打过分),它才可能被推荐给其他用户。所以,如果一个纯CF的推荐系统,新加进来的item就永远不会被推荐。
CB的缺点
1. item的特征抽取一般很难(Limited Content Analysis):如果系统中的item是文档(如个性化阅读中),那么我们现在可以比较容易地使用信息检索里的方法来“比较精确地”抽取出item的 特征。但很多情况下我们很难从item中抽取出准确刻画item的特征,比如电影推荐中item是电影,社会化网络推荐中item是人,这些item属性 都不好抽。其实,几乎在所有实际情况中我们抽取的item特征都仅能代表item的一些方面,不可能代表item的所有方面。这样带来的一个问题就是可能 从两个item抽取出来的特征完全相同,这种情况下CB就完全无法区分这两个item了。比如如果只能从电影里抽取出演员、导演,那么两部有相同演员和导 演的电影对于CB来说就完全不可区分了。
2. 无法挖掘出用户的潜在兴趣(Over-specialization):既然CB的推荐只依赖于用户过去对某些item的喜好,它产生的推荐也都会和用户 过去喜欢的item相似。如果一个人以前只看与推荐有关的文章,那CB只会给他推荐更多与推荐相关的文章,它不会知道用户可能还喜欢数码。
3. 无法为新用户产生推荐(New User Problem):新用户没有喜好历史,自然无法获得他的profile,所以也就无法为他产生推荐了。当然,这个问题CF也有。
CB总结
CB应该算是第一代的个性化应用中最流行的推荐算法了。但由于它本身具有某些很难解决的缺点(如上面介绍的第1点),再加上在大多数情况下其精度都不是最 好的,目前大部分的推荐系统都是以其他算法为主(如CF),而辅以CB以解决主算法在某些情况下的不精确性(如解决新item问题)。但CB的作用是不可 否认的,只要具体应用中有可用的属性,那么基本都能在系统里看到CB的影子。组合CB和其他推荐算法的方法很多,最常用的可能是用CB来过滤其他算法的候选集,把一些不太合适的候选(比如不要给小孩推荐偏成人的书籍)去掉。
协同过滤系统:
协同过滤推荐(Collaborative Filtering recommendation)是在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
系统内部细分
根据侧重点不同 其内部又分为两种算法
Item-Based CF(基于项的协同过滤): 基于User对不同Item的评分计算item之间的相似性,通过item的相似性给于User推荐。


假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
User-Based CF(基于用户的协同过滤): 基于User对不同的Item的评分计算User之间的相似性,通过User的相似性给予User推荐

假设用户 A 喜欢物品 A,物品 C,用户 B 喜欢物品 B,用户 C 喜欢物品 A ,物品 C 和物品 D;从这些用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似的,同时用户 C 还喜欢物品 D,那么我们可以推断用户 A 可能也喜欢物品 D,因此可以将物品 D 推荐给用户 A。
Model-Based CF (基于模型的协同过滤): 基于模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。
注:应该如何在IB(Item-Based CF) 和 UB(User-Based CF) 中选择,这要看产品的数量与用户的数量间的对比,如果产品的数量远远大于用户的数量 如新闻推荐,产品变动大于用户变动的使用UB,如亚马逊 用户变动大于产品变动的 用IB 。(这只是一种举例,具体要根据应用场景使用,像亚马逊,事实上是使用了多重推荐引擎的)。
CF 优点:
1. 它不需要对物品或者用户进行严格的建模,而且不要求物品的描述是机器可理解的,所以这种方法也是领域无关的。
2. 这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好
CF缺点:
1. 方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题。
2. 推荐的效果依赖于用户历史偏好数据的多少和准确性。
3. 在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等。
4. 对于一些特殊品味的用户不能给予很好的推荐。
5. 由于以历史数据为基础,抓取和建模用户的偏好后,很难修改或者根据用户的使用演变,从而导致这个方法不够灵活。
混合的推荐机制:
在现行的 Web 站点上的推荐往往都不是单纯只采用了某一种推荐的机制和策略,他们往往是将多个方法混合在一起,从而达到更好的推荐效果。关于如何组合各个推荐机制,这里讲几种比较流行的组合方法。
1. 加权的混合(Weighted Hybridization): 用线性公式(linear formula)将几种不同的推荐按照一定权重组合起来,具体权重的值需要在测试数据集上反复实验,从而达到最好的推荐效果。
2. 切换的混合(Switching Hybridization):前面也讲到,其实对于不同的情况(数据量,系统运行状况,用户和物品的数目等),推荐策略可能有很大的不同,那么切换的混合方式,就是允许在不同的情况下,选择最为合适的推荐机制计算推荐。
3. 分区的混合(Mixed Hybridization):采用多种推荐机制,并将不同的推荐结果分不同的区显示给用户。其实,Amazon,当当网等很多电子商务网站都是采用这样的方式,用户可以得到很全面的推荐,也更容易找到他们想要的东西。
4. 分层的混合(Meta-Level Hybridization): 采用多种推荐机制,并将一个推荐机制的结果作为另一个的输入,从而综合各个推荐机制的优缺点,得到更加准确的推荐。
本文转自 拖鞋崽 51CTO博客,原文链接:http://blog.51cto.com/1992mrwang/1337918

![推荐系统[八]算法实践总结V2:排序学习框架(特征提取标签获取方式)以及京东推荐算法精排技术实战](https://ucc.alicdn.com/images/user-upload-01/70ed73f0ce394fcfa58285de1b0925c5.png?x-oss-process=image/resize,h_160,m_lfit)