开源实时日志分析 ELK , ELK 由 ElasticSearch 、 Logstash 和 Kiabana 三个开源工具组成。官方网站:https://www.elastic.co
其中的3个软件是:
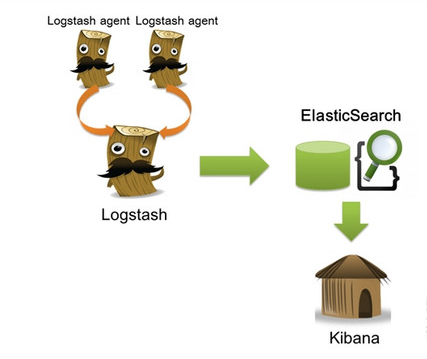
Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制, restful 风格接口,多数据源,自动搜索负载等。
Logstash 是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索)。
kibana 也是一个开源和免费的工具,他 Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志
| 系统 | 系统需要安装的软件 | ip | 描述 |
| centos6.4 | Elasticsearch/test5 | 192.168.48.133 | 搜索存储日志 |
| centos6.4 | Elasticsearch/test4 | 192.168.48.131 | 搜索存储日志 |
| centos6.4 | Logstash/nginx/test1 | 192.168.48.129 | 用来收集日志给上面 |
| centos6.4 | kibana,nginx/test2 | 192.168.48.130 | 用来后端的展示 |
一、先安装elasticsearch集群,并测试通过再进行其他软件安装。
在test5,test4上安装分别安装elasticsearch-2.3.3.rpm 前提要安装java1.8 步骤如下:
yum remove java-1.7.0-openjdk
rpm -ivh jdk-8u91-linux-x64.rpm
yum localinstall elasticsearch-2.3.3.rpm
配置elasticsearch 在目录/etc/elasticsearch目录下面
lasticsearch.yml elasticsearch.yml.bak logging.yml scripts
编辑 vim lasticsearch.yml
修改如下配置
cluster.name: myelk #设置集群的名称,在一个集群里面都是这个名称,必须相同
node.name: test5 #设置每一个节点的名,每个节点的名称必须不一样。
path.data: /path/to/data #指定数据的存放位置,线上的机器这个要放到单一的大分区里面。
path.logs: /path/to/logs #日志的目录
bootstrap.mlockall: true #启动最优内存配置,启动就分配了足够的内存,性能会好很多,测试我就不启动了。
network.host: 0.0.0.0 #监听的ip地址,这个表示所有的地址。
http.port: 9200 #监听的端口号
discovery.zen.ping.unicast.hosts: ["192.168.48.133", "192.168.48.131"] #知道集群的ip有那些,没有集群就会出现就一台工作
两台的配置都一样就是上面的IP和note名称要配置不一样就行
安装插件 head和kopf 之后访问 ip:9200/_plugin/head 和ip:9200/_plugin/kopf (插件可以图形查看elasticsearch的状态和删除创建索引)
/usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf
/usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head
二、安装nginx和logstash软件
在test1上安装好nginx服务 就是收集它的日志呢
yum -y install zlib zlib-devel openssl openssl--devel pcre pcre-devel
./configure --prefix=/usr/local/nginx --with-pcre --with-openssl= --with-zlib=
make && make install
日志在/usr/local/nginx/logs/access.log
然后在test1上安装logstash-2.3.3-1.noarch.rpm
yum remove java-1.7.0-openjdk
rpm -ivh jdk-8u91-linux-x64.rpm
rpm -ivh logstash-2.3.3-1.noarch.rpm
/etc/init.d/logstash start #启动服务
/opt/logstash/bin/logstash -e "input {stdin{}} output{stdout{ codec=>"rubydebug"}}"
#检测环境 执行这个命令检测环境正常否,启动完成后 直接输入东西就会出现之后输入
/opt/logstash/bin/logstash -e 'input {stdin{}} output{ elasticsearch { hosts => ["192.168.48.131:9200"] index => "test"}}'
就是输入东西到48.131的elasticsearch上 会在/path/to/data/myelk/nodes/0/indices 生成你名称test索引文件目录 可以多输入几个到48.131的目录看看有没有文件有就证明正常。
之后在/etc/logstash/conf.d 建立以.conf结尾的配置文件,我收集nginx就叫nginx.conf了内容如下;
###########################################################################################
input {
file {
type => "accesslog"
path => "/usr/local/nginx/logs/access.log" #日志的位置
start_position => "beginning" #日志收集文件,默认end
}
}
output {
if [type] == "accesslog" {
elasticsearch {
hosts => ["192.168.0.87"] ###elasticearch的地址
index => "nginx-access-%{+YYYY.MM.dd}" #生成的索引和刚才的test一样会在那里生成后面的是日期变量。
}
}
}
##########################################################################################
一定要仔细,之后运行/etc/init.d/logstash configtest检测配置是否正常。
之后在elasticearch查看有没有索引生成。多访问下nginx服务
如果没有就修改这个文件
vi /etc/init.d/logstash
######################################################################################################
LS_USER=root ###把这里换成root或者把访问的日志加个权限可以让logstash可以读取它 重启服务就会生成索引了
LS_GROUP=root
LS_HOME=/var/lib/logstash
LS_HEAP_SIZE="1g"
LS_LOG_DIR=/var/log/logstash
LS_LOG_FILE="${LS_LOG_DIR}/$name.log"
LS_CONF_DIR=/etc/logstash/conf.d
LS_OPEN_FILES=16384
LS_NICE=19
KILL_ON_STOP_TIMEOUT=${KILL_ON_STOP_TIMEOUT-0} #default value is zero to this variable but could be updated by user request
LS_OPTS=""
#######################################################################################################
三、安装kibana软件
上面的都安装完成后在test2上面安装kibana
rpm -ivh kibana-4.5.1-1.x86_64.rpm
编辑配置文件在这里/opt/kibana/config/kibana.yml 就修改下面几项就行
#######################################################################################################
server.port: 5601 端口
server.host: "0.0.0.0" 监听
elasticsearch.url: "http://192.168.48.131:9200" elasticsearch地址
######################################################################################################
四、其他的一些配置。
kibana是直接访问的比较不安全,我们需要用nginx访问代理,并设置权限用户名和密码访问
先在kibana服务器上安装nginx 不介绍了
在nginx里面配置
#################################################################################
server
{
listen 80;
server_name localhost;
auth_basic "Restricted Access";
auth_basic_user_file /usr/local/nginx/conf/htpasswd.users; #密码和用户
location / {
proxy_pass http://localhost:5601; #代理kibana的5601之后就可以直接80访问了
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
####################################################################################
创建密码和用户文件:htpasswd.users
需要安装httpd-tool包先安装它
htpasswd -bc /usr/local/nginx/conf/htpasswd.users admin paswdadmin
#前面是用户后面是密码
##################################################################################
一、基本操作
1、命令行运行 bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
#bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
Logstash startup completed
hello world
{
"message" => "hello world",
"@version" => "1",
"@timestamp" => "2017-03-22T01:34:46.013Z",
"host" => "0.0.0.0"
}
2、加载配置文件运行 bin/logstash -f log.conf
input {
stdin { }
}
output {
stdout {
codec => rubydebug {}
}
elasticsearch {
embedded => true
}
}
3、语法
a、区段
logstash 用{} 定义区域,区域内可以包括插件区域定义,一个区域内可以定义多个插件 如:
input {
stdin { }
syslg { }
}
b、数据类型
支持字符串、数值、数组、哈希
二、命令行参数
1、-e “执行”参数的默认值:
input {
stdin { }
}
output {
stdout { }
}
2、--config 或-f : 用来指定启动加载的配置文件
bin/logstash -f log.conf (读取单个配置文件)
bin/logstash -f /etclogstash.d/ (读取目录下所有的配置文件)
3、--configtest 或-t : 测试配置文件是否能正常解析,如果错误,会有提示
./bin/logstash -t -f filebeat20170109.conf
4、--log 或-l: 用于指定输出日志(logstash默认输出日志到标准错误)
bin/logstash -l /tmp/logstash.log
5、--filterworkers 或 -w :指定工作线程
bin/logstash -w 5
6、--pluginpath 或-P 指定插件
7、--verbose 输出一定的调试日志
8、--debug 输出更多的调试日志
三、插件
列出 bin/plugin list
安装 bin/plugin install logstash-output-webhdfs
升级 bin/plugin update logstash-input-tcp
四、启动方式 nohup bin/logstash -f log.conf &
建议启动方式 daemontools,如supervisord
一、输入
a、标准输入:
input {
stdin {
add_field => {"key" =>"value"}
codec =>"plain"
tags => ["add"]
type => "std"
}
}
output {
stdout {
codec => rubydebug {}
}
}
其中tags和type 是logstash中两个特殊字段。type 一般用来指定事件类型,tags是在数据处理过程中,由具体的插件来添加或删除。
b、文件输入
logstash 使用FileWatch的ruby gem库来监听文件变化,支持glob展开文件路径
FileWatch只支持文件的绝对路径而且不会自动递归目录,但可以用**来缩写表示递归全部子目录
/path/to/**/*.log
input {
file {
path => "/var/log/messages"
type => "syslog"
}
file {
path => "/var/log/httpd/access_log"
type => "apache_log"
}
}
filter {
if [type] == "syslog" {
grok {
match => [ "message", "%{SYSLOGBASE} %{GREEDYDATA:message}" ]
overwrite => [ "message" ]
}
}
else if [type] == "apache_log" {
grok {
match => ["message", "%{COMMONAPACHELOG}"]
}
}
}
output {
stdout { codec => rubydebug }
elasticsearch { embedded => "true"}
}
c、TCP输入,最常见的是配合nc命令导入旧数据
版本说明:
Elasticsearch 5.0
Logstash 5.0(暂时未用)
Filebeat 5.0
Kibana 5.0
ELK是一套采集日志并进行清洗分析的系统,由于目前的分析的需求较弱,所以仅仅采用filebeat做日志采集,没有使用logstash
一、环境准备&&软件安装:
1、首先,需要安装Java环境
下载安装包:jre-8u111-linux-x64.rpm
安装:yum install jre-8u111-linux-x64.rpm
2、 新建一个用户,elsearch,用来启动elasticsearch,因为该软件必须用普通用户启动。
useradd elsearch
3、修改变量参数:否则启动elasticsearch会报bootstrap错误。
1、ulimit -u 10240 #
2、vim /etc/sysctl.conf
vm.max_map_count = 655360
sysctl -p
3、vim /etc/security/limits.conf
* soft noproc 65536
* hard noproc 65536
* soft nofile 65536
* hard nofile 65536
4、软件安装
安装包下载地址:https://www.elastic.co/downloads
使用的是绿色安装包,解压即用。
1、filebeat安装
tar -xvf filebeat-5.0.0-linux-x86_64.tar.gz
cp filebeat-5.0.0-linux-x86_64 /usr/local/filebeat -r
./filebeat -configtest 测试配置是否正确
2、kibana安装
tar -xvf kibana-5.0.0-linux-x86_64.tar.gz
cp kibana-5.0.0-linux-x86_64 /usr/local/kibana -r
3、logstash安装(暂时未用)
tar -xvf logstash-5.0.0.tar.gz
cp logstash-5.0.0 /usr/local/logstash -r
4、elasticsearch安装
unzip elasticsearch-5.0.0.zip
cp elasticsearch-5.0.0 /usr/local/elasticsearch -r
二、配置&&启动
1、启动elasticsearch
cd /usr/local/
chown -R elsearch:elsearch elasticsearch 将权限给elsearch用户
su elsearch
cd /usr/local/elasticsearch
修改配置文件如下:
cat config/elasticsearch.yml |grep -v "#"
path.data: /usr/local/elasticsearch/data
path.logs: /usr/local/elasticsearch/logs
network.host: 192.168.221.30
http.port: 9200
#vim conf/elasticsearch.yml
cluster.name: serverlog
#集群名称,可以自定义
node.name: node-1
#节点名称,也可以自定义
path.data:
/home/elasticsearch/elasticsearch-2
.3.4
/data
#data存储路径
path.logs:
/home/elasticsearch/elasticsearch-2
.3.4
/logs
#log存储路径
network.host: 10.0.18.148
#节点ip
http.port: 9200
#节点端口
discovery.zen.
ping
.unicast.hosts: [
"10.0.18.149"
,
"10.0.18.150"
]
#集群ip列表
discovery.zen.minimum_master_nodes: 3
#集群几点数
启动:
cd /usr/local/elasticsearch/bin
./elasticsearch #使用-d参数,放到后台执行
我配置的elasticsearch.yml如下
cluster.name: es-5.0-ztgame
node.name: node-18
network.host: 0.0.0.0
http.port: 19200
http.cors.enabled: true
http.cors.allow-origin: "*"
我配置的kibana.yml如下
server.port: 15601
server.host: "0.0.0.0" #修改监听地址,不然只能本机访问
elasticsearch.url: "http://10.12.15.126:19200"
查看启动情况:
[root@localhost elasticsearch]# lsof -i:9200
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 29987 elsearch 237u IPv6 470519 0t0 TCP 192.168.221.30:wap-wsp
在浏览器中查看:
输入:192.168.221.30:9200
能看到类似信息则启动成功:
{
"name" : "FrmZoqD",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IcATEXFBQkGsZdh4P_TiTw",
"version" : {
"number" : "5.0.0",
"build_hash" : "253032b",
"build_date" : "2016-10-26T04:37:51.531Z",
"build_snapshot" : false,
"lucene_version" : "6.2.0"
},
"tagline" : "You Know, for Search"
}
注意本机防火墙要关掉。
2、配置&&启动filebeat
#!/bin/bash
PATH=/usr/bin:/sbin:/bin:/usr/sbin
export PATH
agent="/usr/local/filebeat/filebeat"
args="-c /usr/local/filebeat/filebeat.yml -path.home /usr/local/filebeat -path.config /usr/local/filebeat -path.data /usr/local/filebeat/data -path.logs /var/log/filebeat"
test_args="-e -configtest"
test() {
$agent $args $test_args
}
start() {
pid=`ps -ef |grep /usr/local/filebeat/data |grep -v grep |awk '{print $2}'`
if [ ! "$pid" ];then
echo "Starting filebeat: "
test
if [ $? -ne 0 ]; then
echo
exit 1
fi
$agent $args &
if [ $? == '0' ];then
echo "start filebeat ok"
else
echo "start filebeat failed"
fi
else
echo "filebeat is still running!"
exit
fi
}
stop() {
echo -n $"Stopping filebeat: "
pid=`ps -ef |grep /usr/local/filebeat/data |grep -v grep |awk '{print $2}'`
if [ ! "$pid" ];then
echo "filebeat is not running"
else
kill $pid
echo "stop filebeat ok"
fi
}
restart() {
stop
start
}
status(){
pid=`ps -ef |grep /usr/local/filebeat/data |grep -v grep |awk '{print $2}'`
if [ ! "$pid" ];then
echo "filebeat is not running"
else
echo "filebeat is running"
fi
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
status)
status
;;
*)
echo $"Usage: $0 {start|stop|restart|status}"
exit 1
esac
修改配置文件:
cd /usr/local/filebeat
cp filebeat.yml filebeat.yml.default
vim filebeat.yml
filebeat.prospectors:
- input_type: log
paths:
- /var/log/messages
document_type: "messages"
output.elasticsearch:
hosts: ["192.168.221.30:9200"] #filebeat传到Elasticsearch
index: filebeat-%{+yyyy.MM.dd} #这里的索引index会跟kibana的索引有关系
touch /var/log/test.log #测试日志文件
启动:
./filebeat -e -c filebeat.yml -d "publish"
测试
输入一条语句进行测试
echo "hello,test" >test.log
将filebeat放入后台执行:
nohup ./filebeat -e -c filebeat.yml >>/dev/null 2>&1 &
3、配置&&启动kibana
修改配置:
cd /usr/local/kibana
vim config/kibana.yml
server.port: 5601
server.host: "27.131.221.30"
elasticsearch.url: "http://27.131.221.30:9200"
修改以上三项。
启动动服务:
cd /usr/local/kibana/bin/
./kibana
如果都配置正确的话,会进入到kibana的页面,刚开始会让你配置一个index索引
这条索引跟我们上面filebeat里面配置的索引有关。
filebeat-*
*就是时间格式,我们是按照时间来进行索引的。
如果是用logstash进行采集数据的话,那么索引就是logstash-*
当然,我们也可以配置多条索引,例如我们同时用filebeat和logstash进行采集不同的业务日志。
3、安装logstash
解压
# tar -xzf logstash-5.2.0.tar.gz -C /usr/local/
编辑配置文件
# cat /usr/local/logstash-5.2.0/config/nginx.yml
input {
beats { #监听在5043端口接收来自filebeat的日志
port => "5043"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"} #过滤规则
}
geoip {
source => "clientip" #过滤规则获取IP
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
配置logstash的配置文件
#cd /etc/logstash/conf.d
#vim logstash.conf
input {
file {
path => ["/var/log/nginx/access.log"]
type => "nginx_log"
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug
}
}
检测语法是否有错
#/opt/logstash/bin/logstash -f /etc/logstash/conf.d/logstash.conf --configtest
Configuration OK #语法OK
修改logstash的配置文件,将日志数据输出到redis
#cat /etc/logstash/conf.d/logstash.conf
input {
file {
path => ["/var/log/nginx/access.log"]
type => "nginx_log"
start_position => "beginning"
}
}
output {
redis {
host => "10.0.18.146"
key => 'logstash-redis'
data_type => 'list'
}
}
检查语法并启动服务
#/opt/logstash/bin/logstash -f /etc/logstash/conf.d/logstash.conf --configtest
Configuration OK
启动
nohup /usr/local/logstash-5.2.0/bin/logstash -f /usr/local/logstash-5.2.0/config/nginx.yml &
4、安装filebeat
在客户端安装filebeat,用于推送日志
# tar -xzf filebeat-5.2.0-linux-x86_64.tar.gz -C /usr/local/
新建推送配置
vim /usr/local/filebeat-5.2.0-linux-x86_64/ipaper.yml
filebeat.prospectors:
- input_type: log
paths:
- /data/wwwlogs/test1.log #指定推送日志文件
- /data/wwwlogs/test2.log
output.logstash:
hosts: ["192.168.0.54:5043"] #指定接收logstash
启动filebeat
5、安装kibana
解压kibana
# tar -xzf kibana-5.2.0-linux-x86_64.tar.gz -C /usr/local/
修改监听地址,不然只能本机访问
# vim /usr/local/kibana-5.2.0-linux-x86_64/config/kibana.ym
server.host: "0.0.0.0"
启动
# /usr/local/kibana-5.2.0-linux-x86_64/bin/kibana &