热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
Oracle SQL*Plus的HELP命令:你的数据库“百事通”
代码随想录训练营 | 一刷总结
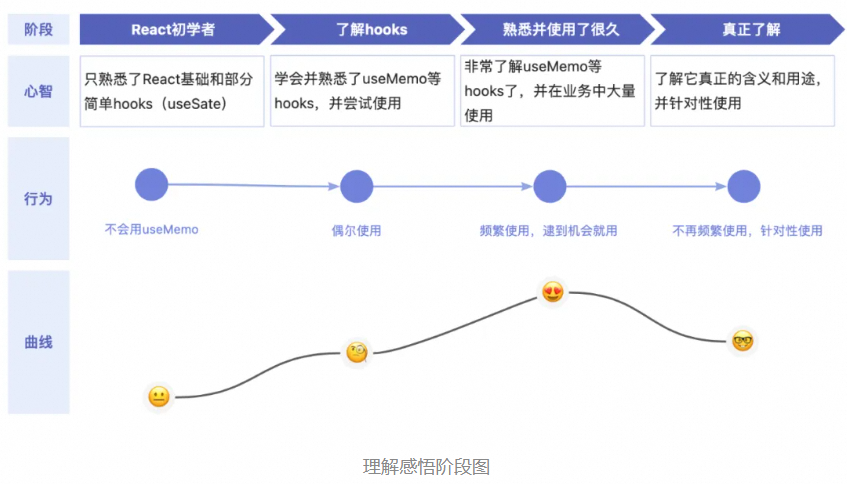
请删掉99%的useMemo
Oracle SQL*Plus的SET命令:你的数据库会话“调色板”
Oracle常用数据字典:数据王国的“藏宝图”
Oracle数据字典:数据王国的“百科全书”
Oracle程序全局区:数据王国的“魔术舞台”
Oracle系统全局区:数据王国的“大舞台”
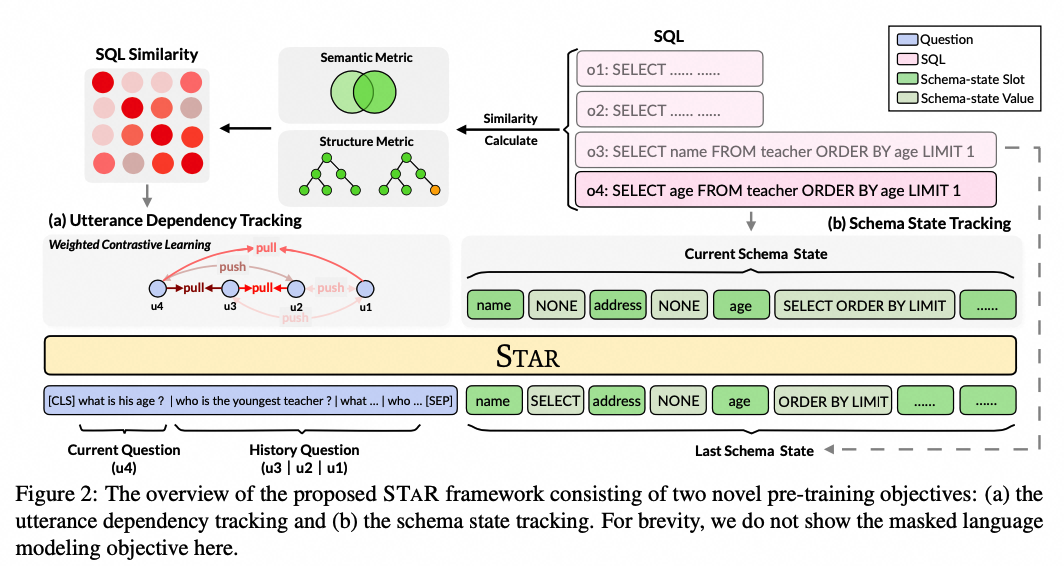
NL2SQL实践系列(2):2024最新模型实战效果(Chat2DB-GLM、书生·浦语2、InternLM2-SQL等)以及工业级案例教学
Oracle的三重奏:密码文件、警告文件与跟踪文件
Oracle服务器参数文件:数据王国的“调控大师”
Oracle日志文件:数据王国的“记事本”
Oracle控制文件:数据王国的导航仪
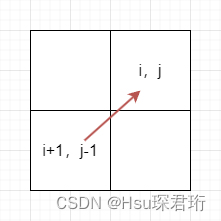
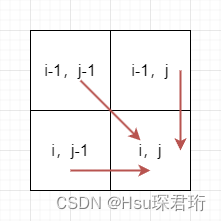
代码随想录算法训练营第六十天 | LeetCode 84. 柱状图中最大的矩形
NL2SQL技术方案系列(1):NL2API、NL2SQL技术路径选择;LLM选型与Prompt工程技巧,揭秘项目落地优化之道
Oracle数据文件:数据王国的秘密藏宝图
代码随想录算法训练营第五十九天 | LeetCode 739. 每日温度、496. 下一个更大元素 I
代码随想录算法训练营第五十七天 | LeetCode 739. 每日温度、496. 下一个更大元素 I
Oracle表空间:数据王国的疆域规划
如何写好代码?一个提升代码可读性的小技巧
代码随想录算法训练营第五十六天 | LeetCode 647. 回文子串、516. 最长回文子序列、动态规划总结
号外号外!ClickHouse企业版正式商业化啦!
Oracle的段:深入数据段与日志段的奥秘
代码随想录算法训练营第五十五天 | LeetCode 583. 两个字符串的删除操作、72. 编辑距离、编辑距离总结
Oracle的段:数据王国的绚丽章节
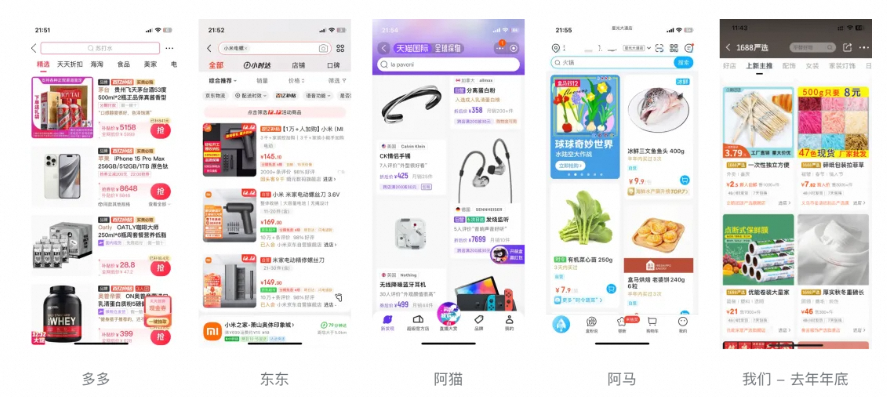
2024年看AIGC是如何让1688主图焕发新春的
从零构建现代深度学习框架(TinyDL-0.01)
手把手教你捏一个自己的Agent
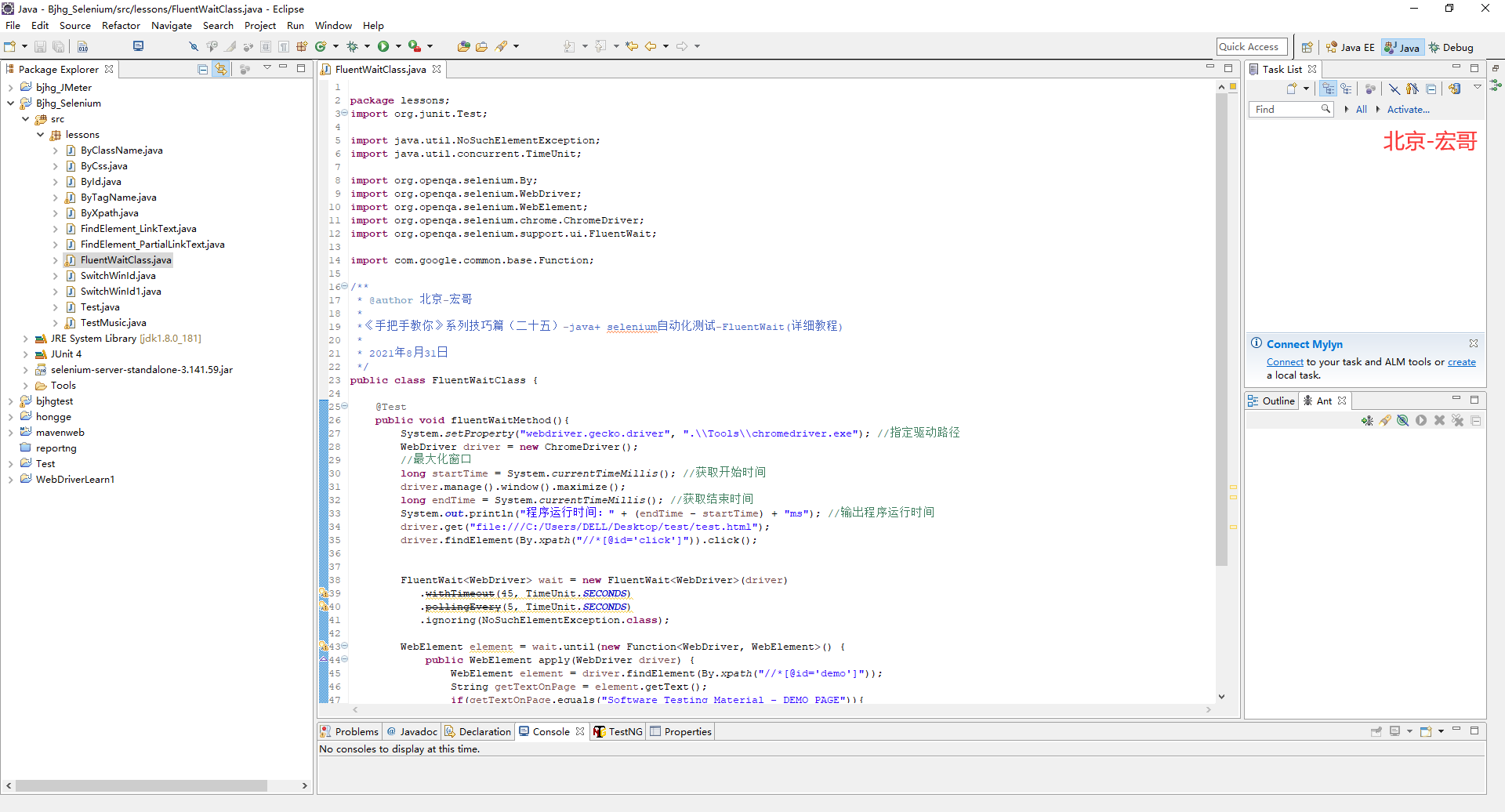
《手把手教你》系列技巧篇(二十五)-java+ selenium自动化测试-FluentWait(详细教程)
一文聊聊程序员的痛楚与磨难选择
Oracle数据区:数据王国的黄金地段
http状态码有哪些?
Oracle数据块:数据王国的基石
什么是js的原型链
对话阿里云佘俊泉:边缘云的持续突破和创新
社区供稿 | vLLM部署Yuan2.0:高吞吐、更便捷
js如何实现修改URL参数并不刷新页面
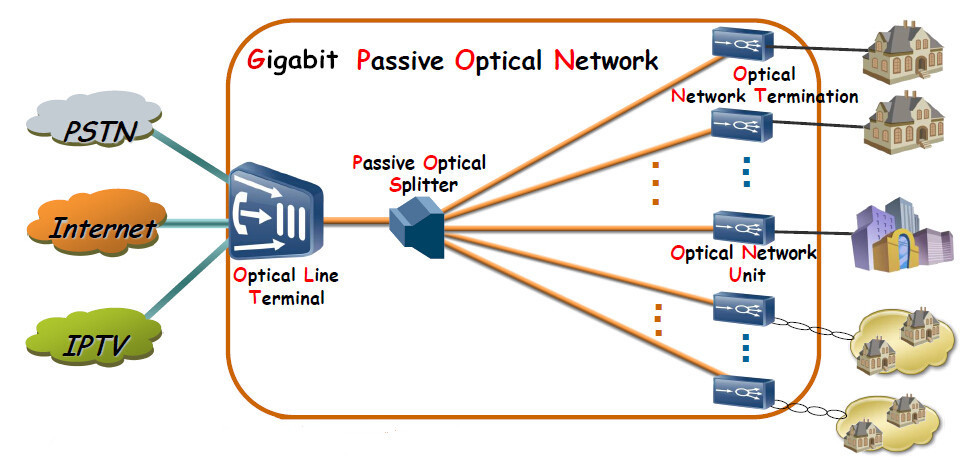
什么是GPON 千兆被动光纤网络?
js获取年月份
什么是跨域?
了解ES6!
jQuery怎样获取下标?
js的鼠标移入移出事件
什么是WPA3?与WPA2有啥区别?
802.11ax (Wi-Fi 6) 如何工作?
什么是双因素身份验证 (2FA)?
jQuery的链式编程
js怎样判断status