在 Oracle 12c 当中,优化器的一个新特性就是提供了新类型的柱状图数据,Top - N 频率柱状图和混合柱状图。优化器利用它们可以更加高效、精确地计算执行计划代价,选择最优计划。这里将探究一下 Top - N 频率柱状图在什么情况下获得、以及它如何影响优化器的选择率的计算。
12c 在线文档描述:
Top - N 频率柱状图是频率柱状图的一个变种,它忽略了那些"非流行数据"(即出现频率低的数值)。例如,1000枚硬币中只有一枚面值1分的硬币,那在创建柱状图分组时,它就可以被忽略。Top - N 频率柱状图能产生一个更利于"流行数据"(高频率数据)的柱状图。
如何产生 Top - N 频率柱状图
首先需要了解的一个事实是,在收集统计信息数据时,如果为估算值设置了一个非默认值,则统计数据过程就类似于11G,即不会产生新类型的柱状图。因此,产生 Top - N 频率柱状图的一个必要条件就是让估算比为默认
例如:

从在线文档对 Top - N 频率柱状图的描述可知,Top - N 频率柱状图分组数量一定小于唯一值数量(Distinct Value Number)。所以,产生 Top - N 频率柱状图的另外一个必要条件是设置的分组数或者默认分组数设置(默认254)小于其唯一值数。
在进一步为字段收集统计数据之前,统计数据收集过程首先会计算近似唯一值数。这一步骤会调用 SQL 分析器(SQL Analyzer)来分析当前输入参数所产生的一条 SQL 语句。例如如下语句:
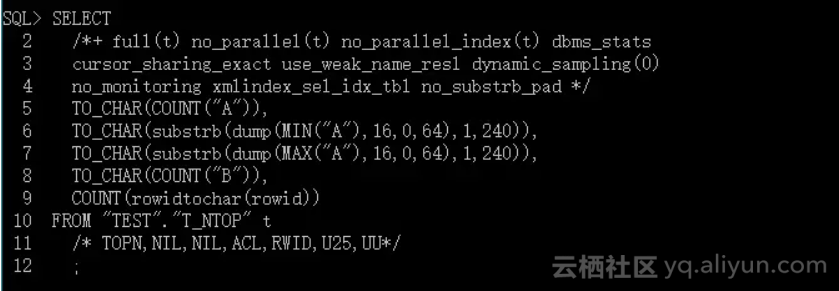
SQL 分析器不光会获得这条查询语句的结果,还会根据输入选项(如TOPN, NIL, NIL, ACL, RWID, U25, UU)在执行和分析过程中调用内部函数获取更多的额外信息。其中就有 TOP - N 数值信息。然而,如果 TOP - N 数值的数据总数在该字段的非空值数据总数中的比例低于一个阈值(1-1/MNB,MNB 为最大分组数,Maximum Number of Buckets,它是影响选择频率柱状图还是高平衡柱状图的重要因素,参见http://www.hellodba.com/reader.php?ID=19&lang=EN)时,TOP - N 数据会被丢弃,也就是说,不会产生Top - N频率柱状图。因而,TOP - N 数值的数据总数在该字段的非空值数据总数中的比例大于(1-1/MNB)也成为产生 Top-N 频率柱状图的一个必要条件。
而字段的最大、最小唯一值必须包含在柱状图数据当中,因此统计过程还需要检查是否需要从现有 Top - N 数据中移除数据以容纳最大、最小值:如果最大、最小值已经在 Top - N 数据当中,则不需要移除,否则将数据量最小的数值移除以腾出位置给最大最小值。相应的,要根据调整后的 Top - N 数据记录总数在非空数值记录总数中的比例再与阈值比较以决定是否采纳 Top - N 频率柱状图。
概括产生 Top - N 频率柱状图的条件:
1. 估算比为默认值;
2. 柱状图分组数小于唯一值数;
3.(调整后的 Top - N 数据记录总数)/(非空数值记录总数)>(1-(1/MNB))
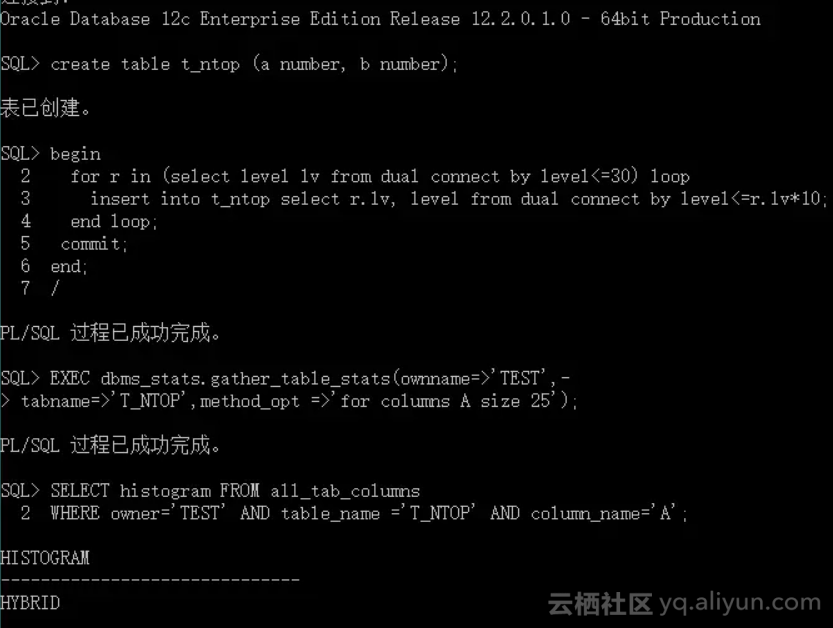
可以看到,尽管设置了分组数小于唯一值(30)的25,并采用了默认估算值,统计收集过程最终还是未给该字段收集 Top - N 频率柱状图。检查 Top - N 数据记录总数在非空数值记录总数中的比例以及阈值。
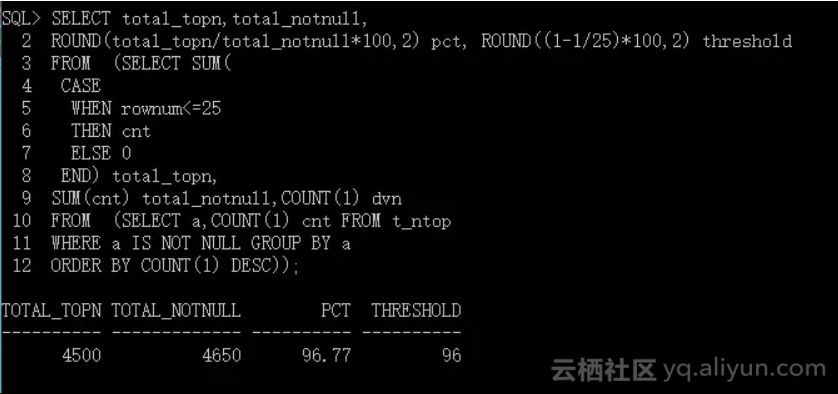
最初计算的 Top - N 数据记录总数在非空数值记录总数中的比例是大于阈值的。再看 Top - N 数据记录总数是否会被调整:
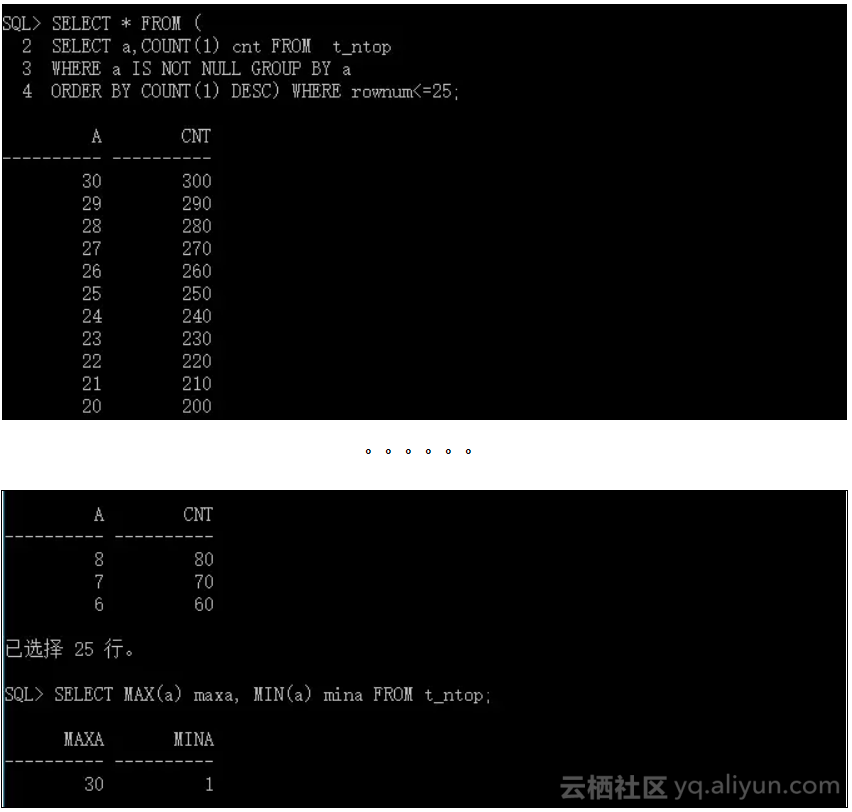
最小值(1)并没有在最初的 Top - N 数值当中,它要替换 Top - N 数值当中的数据量(60)最少的数(6)。调整后计算得到的百分比为:

因此可以看到该值小于阈值(96),所以不会产生 Top - N 频率柱状图。
1. 如果判定谓词中数据位于柱状图当中,则采用柱状图数据计算选择率;
2. 如果判定谓词中数据不位于柱状图当中,则由柱状图以外的唯一值数及其数据数量来计算选择率。
举例说明:
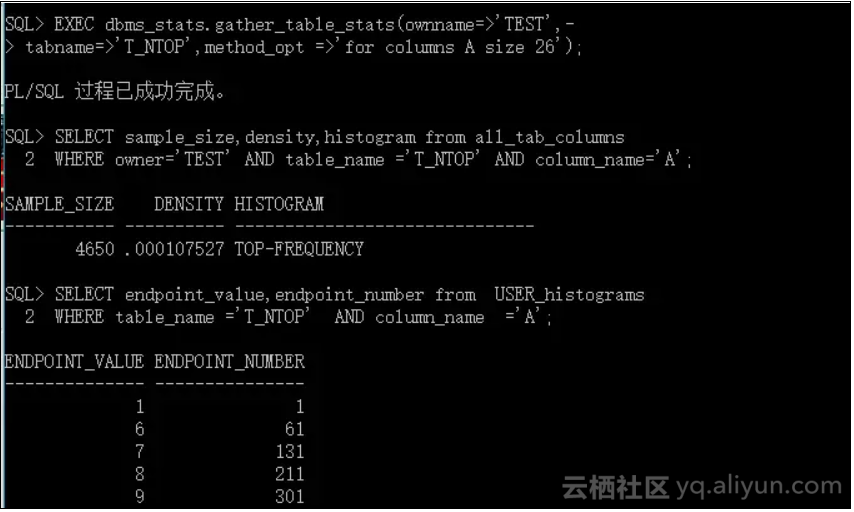
。。。。。。

注意:因为最小值(1)没有被包含在最初分析的 Top-N 值当中,它替换了里面数据量最少的唯一值(5),并且数据量设置为1。
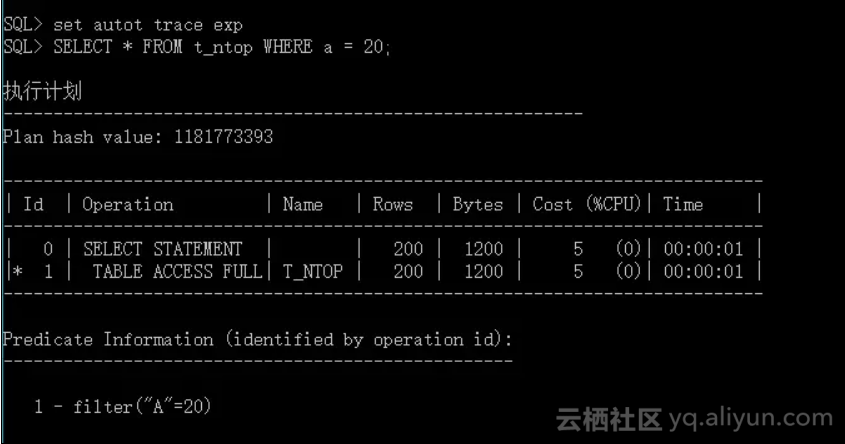
唯一值20的分组数据量为 200 (1951-1751),计算所得选择率为 200/取样大小 = 200 / 4650,因此,过滤后的数据记录数为 cardinality*selectivity = 200。
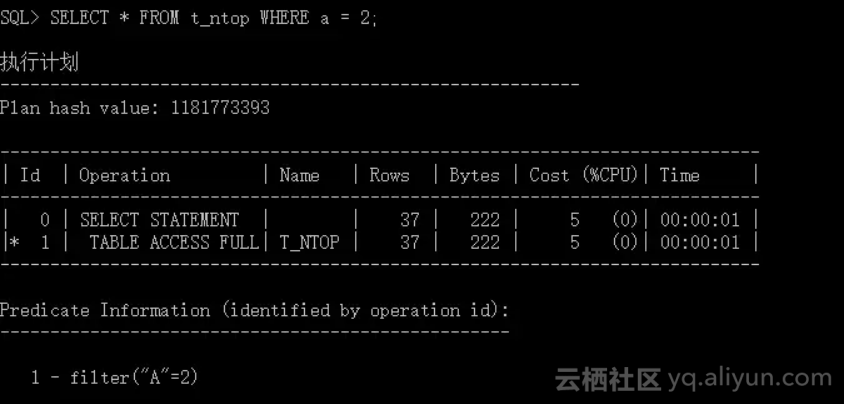
"2" 不是一个 Top - N 数值,这一谓词表达式的选择率为该字段的密度(Density)。然而,对于 Top - N 频率柱状图字段,优化器会根据非 Top - N 数值数据重新计算密度。本例当中,新的密度为(非空值总数 - Top - N 数值总数)/(非 Top-N 数值总数)/(非空值总数)= (4650-4501)/(30-26)/4650 = 0.008010753。因此,过滤后的数据记录为 cardinality*selectivity=trunc (4650*.008010753) = 37。
TIPS:新计算所得密度可以通过 10053 事件跟踪观察到。
原文发布时间为:2018-03-9
本文作者:黄玮