1 前言与背景
为提升对前沿算法技术的研究和理解,去年以个人参赛的方式参加了CIKM 国际数据挖掘大赛AnalytiCup,尝试在7月-8月的一个月时间内,利用业余时间,独立搭建了一套简单的自然语言学习框架,最终在与169支队伍竞技中获得第16名的成绩。
这次比赛是我个人的第一次简单尝试,由于业务较紧,年前没有时间写下来,现在回过头来总结,期望把一些经验和技术方法和大家做一个交流,在技术问题上共同提高。
2 Lazada Product Title Quality Challenge
2.1 问题描述
本次大赛问题由Lazada公司提供,解决的是对于电商网站日益增多的商品交易场景下,识别商品标题是否清晰以及是否简洁的问题。挑战的具体目标是,分别对每个商品标题的清晰度和它的简洁度进行打分([0,1]区间内打两个分)。
要说明的是,这两个指标并不相同,清晰度指的是一个标题的内容是否足够让人容易理解清楚,并且描述是全面准确。
一个不清晰的句子例子是:“Silver Crystal Diamante Effect Evening Clutch Wedding Purse Party Prom Bag Box”。因为分不清卖的是“Wedding Purse”还是“Party Prom Bag Box”。
而一个清晰的句子例子是:“Soft-Touch Plastic Hard Case for MacBook Air 11.6 Case(Models:A1370 and A1465) - with Transparent Keyboard Cover (Transparent)(Export)”。
而与此不同,简洁度指的是一个标题内容不啰嗦。
一个不简洁的句子例子是:“rondaful pure color window screening wedding banquet glass yarn”,因为同义词的冗余度较高,且也存在一定的不清晰。
一个简洁的句子例子是:“moonmini case for iphone 5 5s (hot pink + blue) creative melting ice cream skin hard case protective back case cover”。
为了探索解决这个问题,Lazada提供了真实场景下的一系列原始数据,包括:商品标题,商品的三级类别树,商品的描述,商品的价格,商品的ID等。除此之外,Lazada还提供了一部分人工标注信息。
2.2 数据集
大赛提供了标准数据集进行评估,一共划分为三种数据集,第一份为train data用于训练,第二份为validate data用于第一阶段测试,第三份为test data用于最终测试。
3 Analysis and Design
3.1 问题分析
这个问题是一个很清晰的监督学习问题,但是难点在于,这是一个纯语义层面的短文本挖掘问题,首先没有任何的反馈数据,同时可利用的信息非常有限,只有标题,分类,描述等一些非常基本的信息,但要识别的确是一个非常高维和高度抽象的语义层面上的清晰度和简洁度。但另一方面来说,解决这样的问题也具有非常强的现实普适意义。对于内部业务来说,使用最简单的数据,去识别抽象的商业目标,这是一种非常有价值的通用技术。
在解决这个问题的过程中,本工作用到了两类方向的相关技术,一是自然语言处理,二是数据挖掘。具体方法将在下文展开细节介绍。
此外,由于清晰度和简洁度实际上是两个独立的目标,因此从识别上,对这两个目标分别构建了两个独立模型,单独求解。
3.2 方案设计
方案将构建两个独立的回归模型,对清晰度和简洁度两个指标分别进行训练打分。由于前面分析,这是一个短文本的挖掘问题,因此采取的方案是,先构建多个不同维度下的中间语义,再用中间语义对最终目标求解。这样尽可能的通过构造和扩展的方式,可以生成更多的可用信息,从而解决短文本数据上这一天然缺陷的问题。
最终的方案中,构建了以下几大维度的中间语义信息,用作后续的模型训练。
- 长度维度。长度这一维度是对于清晰和简洁都较为重要的一个分析层面
- 冗余性维度。冗余性对于简洁度的分析来说非常重要。
- 相关性维度。相关性对于两个目标来说,都有较强的说明商品标题是否准确的参考意义。
- embedding维度。Embedding是主要通过词向量的形式作为更多的信息补充,可以有效得到一些人为难以定义的区分信息。
- 黑名单维度。黑名单对于一些无法刻画出来语义信息,但却统计意义上具有区分度的一些难以定义的区分信息很有帮助。
- 词性维度。这是自然语言能够影响用户判断的一个较为重要的维度信息。
从这些维度设计中可以看出,系统没有使用任何反馈信息,并且都是围绕标题、类别等短文本而衍生出的中间语义信息,这些语义信息不仅对于清晰度和简洁度的识别很有帮助,并且通常对于搜索相关性,自动标签等多种其他常见任务来说都有重要的作用。
这一过程的本质可以看做是将一个监督学习的问题分解为了多个子问题,从而引入更多的弱目标,然后通过弱目标来强化最终强目标的准确率。
4 系统设计
为了有效的构建多个维度的监督学习体系,整个系统从数据、特征、模型、验证四个方面实现,是一套基于自然语言处理的机器学习框架,不依赖任何特定业务数据。框架包含数据预处理、可视化分析、特征工程、模型训练、集成学习、交叉验证等几个核心模块。整个系统的设计示意图如下:
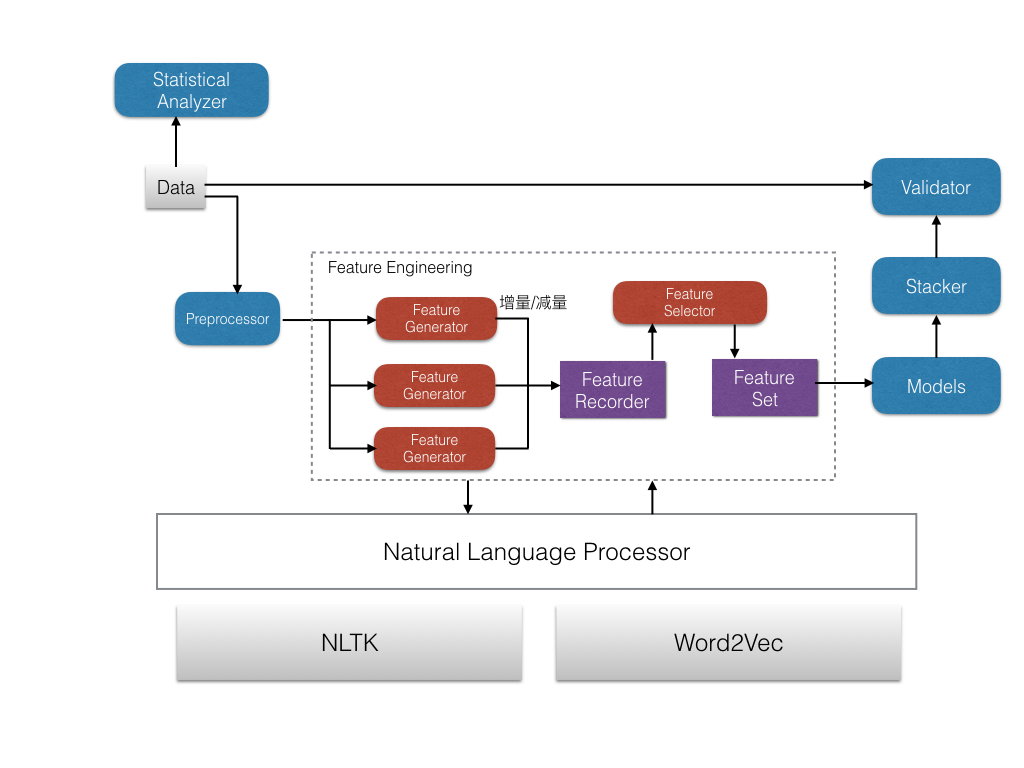
这里分别简单介绍下几个主要模块的功能与实现。
4.1 Statistical Analyzer
这是统计分析模块,主要对于原始数据进行归类以及对不同维度进行可视化分析,这个模块并不在机器学习主流程中,却对于一个开放性的业务问题具有非常重要的作用,能从原始数据中找到有价值的规律性和可解释性,并且优势在于,能在最低成本最快的效率下发现有价值的信息。
4.2 Feature Engineering组件
这一部分包含多个特征生成模块(架构在自然语言处理模块之上)和特征选择模块。特征工程是业务中最为重要的一项工作,其复杂程度远大于模型的变化性,大量特征之间的组合是指数级别的,快速找到一组较为全面又合适的特征集对于通用机器学习问题来说非常关键。因此,所实现的系统专门设计了特征池(Feature Recorder)和特征选择器(Feature Selector)。特征池可以方便的存储已有的特征,并灵活的进行增量和删除,从而不改变原有的记录,这样能大大加快实验的效率,因为各种特征之间的组合量实在太大,重复计算是非常庞大而耗时的。而专门在一个特征池里做到特征的复用和增量,需要特征管理有灵活的扩展能力,否则在管理越来越多的特征时,系统就会非常紊乱。于是在这次设计系统的过程中,我尝试对于特征计算专门面向一簇的特征和一个样本group_id进行一个特征单元,然后特征单元就可以根据配置随意组合,既保证高效,也保证代码管理性清晰,适合大型学习任务。
特征选择器,在这里设计为通过交叉验证的数据集上表现最好的一个特征子集来设计,此外,在进行耗时的选择之前,会优先用TOP K来先初筛一遍特征。
4.3 Models组件
这一部分是训练模型的组件,和特征工程完全解耦,可以方便的用于训练任何业务数据。总体设计上分为三块部分:1)模型学习模块,2)集成学习模块,3)交叉验证模块。在模型学习模块中实现了大量的常用模型,可直接通过配置加载选择。而集成学习模块是作为精度调优的利器,本工作使用stacking的方式实现了集成学习,最终使得训练结构为两层,第一层是单独模型训练,第二层是用XGBoost训练stacking。
5 特征工程
特征工程是对于机器学习应用的最重要的工作之一,在这次比赛中,一共使用了一百多项特征用于训练,由于篇幅,这里只介绍部分主要特征的设计思想。
冗余性特征,借鉴对语言的结构化处理,构造了各种不同的刻画冗余性的特征,例如n-gram的重复度(3 gram-8 gram),n-char的重复度(3 char-8 char),unique的数量/比例,词向量的similarity(分为多个区间),以及各个特征的max, min, average, sum等统计值。此外,这里使用的n-gram和n-char都将句子本身看做是无序词的集合,即不依赖顺序,也不需要是连续的词。
类别性特征,对于三级类目,分别先进行one-hot的序列化(长尾部分归一),然后对one-hot做了PCA的主成分分析进行降维,从而形成数值化特征。
相关性特征 这里使用word2vec对于词和各级类目之间的相似性作为标题内容是否准确相关的考量,为刻画全面,同时也使用了多个统计指标,如全句最相关,全句相关总和,全句相关Top N。
embedding特征, 使用了google news作为词库,将每个词映射为embedding的词向量,并直接给深度学习算法使用,深度学习具有从原始词向量中提取有用特征的能力。
TF-IDF特征,把标题和描述看做一个doc,把单词看做keyword,这样可以构建一个TF-IDF的map,利用这个map作为句子的一种语义分布。
词性特征,除了上述通过一些机器学习通用处理分析外,还使用了NLTK工具对句子entry词性做了分析,对句子的名词,形容词构建了统计特征。
6 核心算法介绍
在最终的提交方案中,有四大类算法具有最重要的效果提升,分别为:XGBoost模型,CNN模型,LSTM模型,和集成学习调优。下面分别简单介绍
XGBoost,这是当前工业界效果最佳的监督学习算法之一,在本次工作中也收获了单模型最大的效果。这是一类将多个弱分类器合成强分类器的boost算法,最大的特点是优化目标时使用二阶泰勒展开,同时使用一阶和二阶导数,并且在代价函数中引入了正则项,在过拟合方面有着更好的效果。此外XGBoost借鉴了随机森林的列抽样的做法,也能有效防止过拟合并加速计算速度。从性能上来说,XGBoost是目前性能显著最优的boost算法。从效果上来说,它与微软的LightGBM非常接近。
CNN,在所有学习任务中,CNN具有第二好的效果,它的学习方式直接从embedding词向量进行学习,网络自动提取有效特征,而没有用到专门人工构建的特征。在比赛实现中,使用了6层结构,前两层为卷积层,后四层为全连接DNN结构。
LSTM,除了CNN之外,还使用了LSTM网络,这是一类特殊的RNN,具有对long term的词具有记忆作用的网络结构。由于因为标题输入短文本,LSTM的效果和CNN几乎持平,但是因为网络结构不同,两者之间也有一定的互补作用。
Stacking,为了做进一步的精度调优,本工作还使用了stacking的方式将类型不同的算法结合起来取长补短,但与boosting不同,boosting是将多个弱分类器变为一个强分类器,而stacking的作用是将多个强分类器变为一个更强的分类器。在这次工作中,stacking第一层集成了XGBoost, CNN, LSTM, SVM, Lasso Regression等多个模型的效果,将模型特征和原始特征结合作为stacking第二层的输入,整个stacking训练结构设计如下:
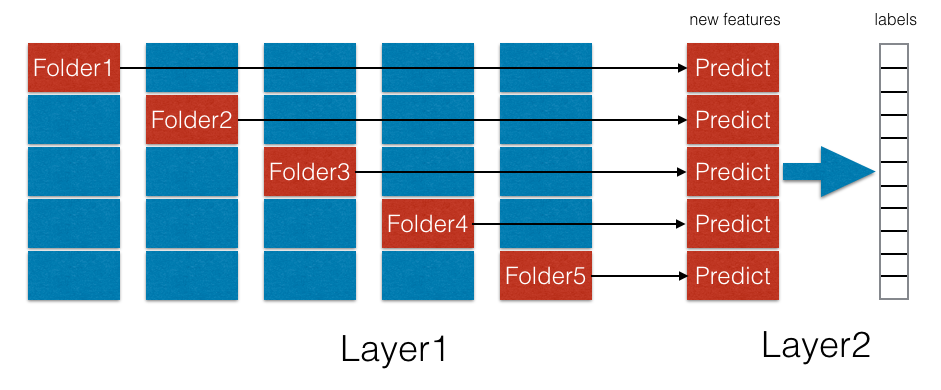
可从图中看出,stacking技术本身也是一种网络结构,在比赛的实现中是一个二层网络,它可以有效提供准确精度,但由于不同的模型不同的数据样本需要重新生成中间特征,因此在模型数量较大,层数较高时,stacking的实现复杂度也会变得非常大。
7 一些理解和经验
从这次比赛当中,个人认为有一些理解和经验是值得启发的。
经验一:差异在什么地方
这次比赛最终的版本是基于上面的这种方案设计进行实现的,但是仅用这样一套方法,事实上效果并不能非常显著的提高。这里通过工作发现的一个特点是,对于标题类文本,相似特征集之间单个来看,几乎是相同的表达,但依然具有明显的互补性。以冗余性举例,从直觉上理解定义一个相似度的权重和词相重合的权重就能充分表达冗余性。但是在实际实验过程中,可以发现表达形式上非常接近或者几乎一样的,比如独立性词的比例和数量,相似度小于0.4的词的比例和数量,最大的相似度,重合的个数,二元重合的个数等一些,甚至是句子clean一遍后再重复定义的特征集,在大量累积起来的时候,也能取得很大的提升。这个现象的本质,我认为是自然语言的特征定义是非常立体的,这里的特征不像效果数据那样独立分布,而是互相有很多的互补,我把这种互补能力看做是自然语言在高维的一副图,尤其是词粒度的特征,在相似特征累积之后,它们可能在虚拟图像上会把各自的一些空缺填补。于是本次比赛确实使用了非常多几乎一致的特征。这是提升效果的关键之一。
经验二:什么模型适合特征累积
并不是所有算法在特征累积之后能够产生很大的提升,比如SVM,LR,在使用大量特征的时候,效果是几乎不增长的。对特征累积表现最为明显的是boost系列的模型。从原理上来说,这并非巧合,恰恰是因为boosting的思想是层层对做的不好的样本单独处理,或是专门优化残差,因此大量的相似特征,在进一步迭代优化期间,起到了很好的收敛效果。而且在标题分类这个问题上,数据具有很明显的层级分布,即某一类特征具有一层,另一类特征具有另一层。根据比赛中的可视化分析可以发现,最最难以判断的一层数据,其实只有样本量的1%。除了boost以外,CNN和LSTM是另一类对特征累积适应很好的算法,当然在这个问题当中,系统使用词的原始向量作为特征。
经验三:错误标注
在比赛的实验过程中,确实发现了一些标题,非常近似,有些只差了一个括号,却label信息不一样。
个人认为,标注信息是存在一定有误的,当然这个比例非常低。从现实角度来说,因为基于人工标注,标注信息小比例有误也是非常常见的。因此一个更加practical 的训练方式是在这种并非完全准确的数据上,能通过一定识别,把错误标注从训练数据中剔除出来,再进行训练,可以更加符合实际场景,从而取得一定效果提升。
8 展望
在本次比赛尝试中,通过上述模型和特征方法,取得了一个准确率比较高的效果,但解决这个比赛问题并不是主要的目的,在这个过程中,也总结沉淀下了一些通用性的框架和经验,这套训练方式本身是基础性的工作,可用在日常的业务工作和前沿的探索。同时,通过这次比赛,我认为有一些方向可以作为选择去提高基础训练的能力。例如如果想从通用角度,优化一个训练框架,可以有以下一些思路:a) 支持百级模型优化组合的集成学习网络 b) 深度学习网络结构和表达能力的探索,尤其是原始特征和经验特征更好融合的能力,c) 加强数据的预处理能力和层次性结构聚类,d) 加强抗噪声干扰的功能,e) 持续提升特征工程效率。
这些就是本次比赛的一些浅见和思考,希望大家多交流和批评指正。
