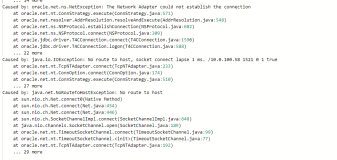
Fri Dec 18 12:23:39 2009
Shutting down instance (abort)
License high water mark = 22
Instance terminated by USER, pid = 29537
Fri Dec 18 12:23:41 2009
Starting ORACLE instance (normal)
LICENSE_MAX_SESSION = 0
LICENSE_SESSIONS_WARNING = 0
Interface type 1 eth1 172.16.1.0 configured from OCR for use as a cluster interconnect
Interface type 1 eth0 192.168.1.0 configured from OCR for use as a public interface
Picked latch-free SCN scheme 1
WARNING: db_recovery_file_dest is same as db_create_file_dest
Autotune of undo retention is turned on.
LICENSE_MAX_USERS = 0
SYS auditing is disabled
ksdpec: called for event 13740 prior to event group initialization
Starting up ORACLE RDBMS Version: 10.2.0.1.0.
System parameters with non-default values:
processes = 300
sessions = 335
__shared_pool_size = 1073741824
__large_pool_size = 16777216
__java_pool_size = 16777216
__streams_pool_size = 0
spfile = /u01/app/oracle/product/10.2.0/db_1/dbs/spfileracdbidc2.ora
sga_target = 2483027968
control_files = +LLPWDB/racdbidc/controlfile/current.261.703277161, +LLPWDB/racdbidc/controlfile/current.260.703277163
db_block_size = 8192
__db_cache_size = 1358954496
compatible = 10.2.0.1.0
log_archive_dest_1 = location=/logstore/archlog
log_archive_max_processes= 4
db_file_multiblock_read_count= 16
cluster_database = TRUE
cluster_database_instances= 2
db_create_file_dest = +LLPWDB
db_recovery_file_dest = +LLPWDB
db_recovery_file_dest_size= 85899345920
thread = 2
instance_number = 2
undo_management = AUTO
undo_tablespace = UNDOTBS2
remote_login_passwordfile= EXCLUSIVE
db_domain =
dispatchers = (PROTOCOL=TCP) (SERVICE=racdbidcXDB)
remote_listener = LISTENERS_RACDBIDC
job_queue_processes = 10
background_dump_dest = /u01/app/oracle/admin/racdbidc/bdump
user_dump_dest = /u01/app/oracle/admin/racdbidc/udump
core_dump_dest = /u01/app/oracle/admin/racdbidc/cdump
audit_file_dest = /u01/app/oracle/admin/racdbidc/adump
db_name = racdbidc
open_cursors = 300
pga_aggregate_target = 824180736
Cluster communication is configured to use the following interface(s) for this instance
172.16.1.216
Fri Dec 18 12:23:42 2009
cluster interconnect IPC version:Oracle UDP/IP
IPC Vendor 1 proto 2
PMON started with pid=2, OS id=29645
DIAG started with pid=3, OS id=29647
PSP0 started with pid=4, OS id=29649
LMON started with pid=5, OS id=29651
LMD0 started with pid=6, OS id=29653
LMS0 started with pid=7, OS id=29655
LMS1 started with pid=8, OS id=29659
MMAN started with pid=9, OS id=29663
DBW0 started with pid=10, OS id=29665
LGWR started with pid=11, OS id=29667
CKPT started with pid=12, OS id=29669
SMON started with pid=13, OS id=29671
RECO started with pid=14, OS id=29673
CJQ0 started with pid=15, OS id=29675
MMON started with pid=16, OS id=29677
Fri Dec 18 12:23:42 2009
starting up 1 dispatcher(s) for network address '(ADDRESS=(PARTIAL=YES)(PROTOCOL=TCP))'...
MMNL started with pid=17, OS id=29679
Fri Dec 18 12:23:42 2009
starting up 1 shared server(s) ...
Fri Dec 18 12:23:42 2009
lmon registered with NM - instance id 2 (internal mem no 1)
Fri Dec 18 12:23:46 2009
Reconfiguration started (old inc 0, new inc 28)
pseudo shared rm latch used
List of nodes:
0 1
Global Resource Directory frozen
* allocate domain 0, invalid = TRUE
Communication channels reestablished
* domain 0 valid = 0 according to instance 0
Fri Dec 18 12:23:47 2009
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Fri Dec 18 12:23:47 2009
LMS 0: 0 GCS shadows cancelled, 0 closed
Fri Dec 18 12:23:47 2009
LMS 1: 0 GCS shadows cancelled, 0 closed
Set master node info
Submitted all remote-enqueue requests
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
Fri Dec 18 12:23:47 2009
LMS 0: 0 GCS shadows traversed, 0 replayed
Fri Dec 18 12:23:47 2009
LMS 1: 0 GCS shadows traversed, 0 replayed
Fri Dec 18 12:23:47 2009
Submitted all GCS remote-cache requests
Fix write in gcs resources
Reconfiguration complete
LCK0 started with pid=20, OS id=29817
Fri Dec 18 12:23:48 2009
ALTER DATABASE MOUNT
Fri Dec 18 12:23:48 2009
Starting background process ASMB
ASMB started with pid=22, OS id=29847
Starting background process RBAL
RBAL started with pid=23, OS id=29851
Loaded ASM Library - Generic Linux, version 2.0.4 (KABI_V2) library for asmlib interface
Fri Dec 18 12:23:56 2009
SUCCESS: diskgroup LLPWDB was mounted
Fri Dec 18 12:24:00 2009
Setting recovery target incarnation to 2
Fri Dec 18 12:24:00 2009
Successful mount of redo thread 2, with mount id 411672069
Fri Dec 18 12:24:00 2009
Database mounted in Shared Mode (CLUSTER_DATABASE=TRUE)
Completed: ALTER DATABASE MOUNT
Fri Dec 18 12:24:01 2009
ALTER DATABASE OPEN
Picked broadcast on commit scheme to generate SCNs
Fri Dec 18 12:24:03 2009
LGWR: STARTING ARCH PROCESSES
ARC0 started with pid=25, OS id=30257
ARC1 started with pid=26, OS id=30270
ARC2 started with pid=27, OS id=30272
Fri Dec 18 12:24:03 2009
ARC0: Archival started
ARC1: Archival started
ARC2: Archival started
ARC3: Archival started
LGWR: STARTING ARCH PROCESSES COMPLETE
ARC3 started with pid=28, OS id=30274
Fri Dec 18 12:24:04 2009
Thread 2 opened at log sequence 505
Current log# 7 seq# 505 mem# 0: +LLPWDB/racdbidc/onlinelog/loggroup7-1
Current log# 7 seq# 505 mem# 1: +LLPWDB/racdbidc/onlinelog/loggroup7-2
Successful open of redo thread 2
Fri Dec 18 12:24:04 2009
MTTR advisory is disabled because FAST_START_MTTR_TARGET is not set
Fri Dec 18 12:24:04 2009
ARC1: STARTING ARCH PROCESSES
Fri Dec 18 12:24:04 2009
ARC2: Becoming the 'no FAL' ARCH
ARC2: Becoming the 'no SRL' ARCH
Fri Dec 18 12:24:04 2009
ARC3: Becoming the heartbeat ARCH
Fri Dec 18 12:24:04 2009
SMON: enabling cache recovery
Fri Dec 18 12:24:04 2009
ARC4: Archival started
ARC1: STARTING ARCH PROCESSES COMPLETE
ARC4 started with pid=29, OS id=30315
Fri Dec 18 12:24:05 2009
Successfully onlined Undo Tablespace 5.
Fri Dec 18 12:24:05 2009
SMON: enabling tx recovery
Fri Dec 18 12:24:05 2009
Database Characterset is AL32UTF8
replication_dependency_tracking turned off (no async multimaster replication found)
Starting background process QMNC
QMNC started with pid=37, OS id=30433
Fri Dec 18 12:24:10 2009
Completed: ALTER DATABASE OPEN
Fri Dec 18 12:29:44 2009
Reconfiguration started (old inc 28, new inc 32)
List of nodes:
0 1
Global Resource Directory frozen
* dead instance detected - domain 0 invalid = TRUE
Communication channels reestablished
* domain 0 valid = 0 according to instance 0
Fri Dec 18 12:29:45 2009
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Fri Dec 18 12:29:45 2009
LMS 1: 1 GCS shadows cancelled, 0 closed
Fri Dec 18 12:29:45 2009
LMS 0: 1 GCS shadows cancelled, 1 closed
Set master node info
Submitted all remote-enqueue requests
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
Fri Dec 18 12:29:45 2009
LMS 0: 2997 GCS shadows traversed, 978 replayed
Fri Dec 18 12:29:45 2009
LMS 1: 3178 GCS shadows traversed, 927 replayed
Fri Dec 18 12:29:45 2009
Submitted all GCS remote-cache requests
Fix write in gcs resources
Fri Dec 18 12:29:45 2009
Instance recovery: looking for dead threads
Reconfiguration complete
Fri Dec 18 12:29:45 2009
Beginning instance recovery of 1 threads
parallel recovery started with 7 processes
Fri Dec 18 12:29:46 2009
Started redo scan
Fri Dec 18 12:29:46 2009
Completed redo scan
848 redo blocks read, 96 data blocks need recovery
Fri Dec 18 12:29:47 2009
Started redo application at
Thread 1: logseq 298, block 31520
Fri Dec 18 12:29:47 2009
Recovery of Online Redo Log: Thread 1 Group 9 Seq 298 Reading mem 0
Mem# 0 errs 0: +LLPWDB/racdbidc/onlinelog/loggroup9-1
Mem# 1 errs 0: +LLPWDB/racdbidc/onlinelog/loggroup9-2
Fri Dec 18 12:29:47 2009
Completed redo application
Fri Dec 18 12:29:47 2009
Completed instance recovery at
Thread 1: logseq 298, block 32368, scn 14861724
91 data blocks read, 93 data blocks written, 848 redo blocks read
Switch log for thread 1 to sequence 299
Fri Dec 18 12:29:48 2009
Shutting down archive processes
Fri Dec 18 12:29:53 2009
ARCH shutting down
ARC4: Archival stopped
Fri Dec 18 12:38:48 2009
db_recovery_file_dest_size of 81920 MB is 0.27% used. This is a
user-specified limit on the amount of space that will be used by this
database for recovery-related files, and does not reflect the amount of
space available in the underlying filesystem or ASM diskgroup.
Shutting down instance (abort)
License high water mark = 22
Instance terminated by USER, pid = 29537
Fri Dec 18 12:23:41 2009
Starting ORACLE instance (normal)
LICENSE_MAX_SESSION = 0
LICENSE_SESSIONS_WARNING = 0
Interface type 1 eth1 172.16.1.0 configured from OCR for use as a cluster interconnect
Interface type 1 eth0 192.168.1.0 configured from OCR for use as a public interface
Picked latch-free SCN scheme 1
WARNING: db_recovery_file_dest is same as db_create_file_dest
Autotune of undo retention is turned on.
LICENSE_MAX_USERS = 0
SYS auditing is disabled
ksdpec: called for event 13740 prior to event group initialization
Starting up ORACLE RDBMS Version: 10.2.0.1.0.
System parameters with non-default values:
processes = 300
sessions = 335
__shared_pool_size = 1073741824
__large_pool_size = 16777216
__java_pool_size = 16777216
__streams_pool_size = 0
spfile = /u01/app/oracle/product/10.2.0/db_1/dbs/spfileracdbidc2.ora
sga_target = 2483027968
control_files = +LLPWDB/racdbidc/controlfile/current.261.703277161, +LLPWDB/racdbidc/controlfile/current.260.703277163
db_block_size = 8192
__db_cache_size = 1358954496
compatible = 10.2.0.1.0
log_archive_dest_1 = location=/logstore/archlog
log_archive_max_processes= 4
db_file_multiblock_read_count= 16
cluster_database = TRUE
cluster_database_instances= 2
db_create_file_dest = +LLPWDB
db_recovery_file_dest = +LLPWDB
db_recovery_file_dest_size= 85899345920
thread = 2
instance_number = 2
undo_management = AUTO
undo_tablespace = UNDOTBS2
remote_login_passwordfile= EXCLUSIVE
db_domain =
dispatchers = (PROTOCOL=TCP) (SERVICE=racdbidcXDB)
remote_listener = LISTENERS_RACDBIDC
job_queue_processes = 10
background_dump_dest = /u01/app/oracle/admin/racdbidc/bdump
user_dump_dest = /u01/app/oracle/admin/racdbidc/udump
core_dump_dest = /u01/app/oracle/admin/racdbidc/cdump
audit_file_dest = /u01/app/oracle/admin/racdbidc/adump
db_name = racdbidc
open_cursors = 300
pga_aggregate_target = 824180736
Cluster communication is configured to use the following interface(s) for this instance
172.16.1.216
Fri Dec 18 12:23:42 2009
cluster interconnect IPC version:Oracle UDP/IP
IPC Vendor 1 proto 2
PMON started with pid=2, OS id=29645
DIAG started with pid=3, OS id=29647
PSP0 started with pid=4, OS id=29649
LMON started with pid=5, OS id=29651
LMD0 started with pid=6, OS id=29653
LMS0 started with pid=7, OS id=29655
LMS1 started with pid=8, OS id=29659
MMAN started with pid=9, OS id=29663
DBW0 started with pid=10, OS id=29665
LGWR started with pid=11, OS id=29667
CKPT started with pid=12, OS id=29669
SMON started with pid=13, OS id=29671
RECO started with pid=14, OS id=29673
CJQ0 started with pid=15, OS id=29675
MMON started with pid=16, OS id=29677
Fri Dec 18 12:23:42 2009
starting up 1 dispatcher(s) for network address '(ADDRESS=(PARTIAL=YES)(PROTOCOL=TCP))'...
MMNL started with pid=17, OS id=29679
Fri Dec 18 12:23:42 2009
starting up 1 shared server(s) ...
Fri Dec 18 12:23:42 2009
lmon registered with NM - instance id 2 (internal mem no 1)
Fri Dec 18 12:23:46 2009
Reconfiguration started (old inc 0, new inc 28)
pseudo shared rm latch used
List of nodes:
0 1
Global Resource Directory frozen
* allocate domain 0, invalid = TRUE
Communication channels reestablished
* domain 0 valid = 0 according to instance 0
Fri Dec 18 12:23:47 2009
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Fri Dec 18 12:23:47 2009
LMS 0: 0 GCS shadows cancelled, 0 closed
Fri Dec 18 12:23:47 2009
LMS 1: 0 GCS shadows cancelled, 0 closed
Set master node info
Submitted all remote-enqueue requests
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
Fri Dec 18 12:23:47 2009
LMS 0: 0 GCS shadows traversed, 0 replayed
Fri Dec 18 12:23:47 2009
LMS 1: 0 GCS shadows traversed, 0 replayed
Fri Dec 18 12:23:47 2009
Submitted all GCS remote-cache requests
Fix write in gcs resources
Reconfiguration complete
LCK0 started with pid=20, OS id=29817
Fri Dec 18 12:23:48 2009
ALTER DATABASE MOUNT
Fri Dec 18 12:23:48 2009
Starting background process ASMB
ASMB started with pid=22, OS id=29847
Starting background process RBAL
RBAL started with pid=23, OS id=29851
Loaded ASM Library - Generic Linux, version 2.0.4 (KABI_V2) library for asmlib interface
Fri Dec 18 12:23:56 2009
SUCCESS: diskgroup LLPWDB was mounted
Fri Dec 18 12:24:00 2009
Setting recovery target incarnation to 2
Fri Dec 18 12:24:00 2009
Successful mount of redo thread 2, with mount id 411672069
Fri Dec 18 12:24:00 2009
Database mounted in Shared Mode (CLUSTER_DATABASE=TRUE)
Completed: ALTER DATABASE MOUNT
Fri Dec 18 12:24:01 2009
ALTER DATABASE OPEN
Picked broadcast on commit scheme to generate SCNs
Fri Dec 18 12:24:03 2009
LGWR: STARTING ARCH PROCESSES
ARC0 started with pid=25, OS id=30257
ARC1 started with pid=26, OS id=30270
ARC2 started with pid=27, OS id=30272
Fri Dec 18 12:24:03 2009
ARC0: Archival started
ARC1: Archival started
ARC2: Archival started
ARC3: Archival started
LGWR: STARTING ARCH PROCESSES COMPLETE
ARC3 started with pid=28, OS id=30274
Fri Dec 18 12:24:04 2009
Thread 2 opened at log sequence 505
Current log# 7 seq# 505 mem# 0: +LLPWDB/racdbidc/onlinelog/loggroup7-1
Current log# 7 seq# 505 mem# 1: +LLPWDB/racdbidc/onlinelog/loggroup7-2
Successful open of redo thread 2
Fri Dec 18 12:24:04 2009
MTTR advisory is disabled because FAST_START_MTTR_TARGET is not set
Fri Dec 18 12:24:04 2009
ARC1: STARTING ARCH PROCESSES
Fri Dec 18 12:24:04 2009
ARC2: Becoming the 'no FAL' ARCH
ARC2: Becoming the 'no SRL' ARCH
Fri Dec 18 12:24:04 2009
ARC3: Becoming the heartbeat ARCH
Fri Dec 18 12:24:04 2009
SMON: enabling cache recovery
Fri Dec 18 12:24:04 2009
ARC4: Archival started
ARC1: STARTING ARCH PROCESSES COMPLETE
ARC4 started with pid=29, OS id=30315
Fri Dec 18 12:24:05 2009
Successfully onlined Undo Tablespace 5.
Fri Dec 18 12:24:05 2009
SMON: enabling tx recovery
Fri Dec 18 12:24:05 2009
Database Characterset is AL32UTF8
replication_dependency_tracking turned off (no async multimaster replication found)
Starting background process QMNC
QMNC started with pid=37, OS id=30433
Fri Dec 18 12:24:10 2009
Completed: ALTER DATABASE OPEN
Fri Dec 18 12:29:44 2009
Reconfiguration started (old inc 28, new inc 32)
List of nodes:
0 1
Global Resource Directory frozen
* dead instance detected - domain 0 invalid = TRUE
Communication channels reestablished
* domain 0 valid = 0 according to instance 0
Fri Dec 18 12:29:45 2009
Master broadcasted resource hash value bitmaps
Non-local Process blocks cleaned out
Fri Dec 18 12:29:45 2009
LMS 1: 1 GCS shadows cancelled, 0 closed
Fri Dec 18 12:29:45 2009
LMS 0: 1 GCS shadows cancelled, 1 closed
Set master node info
Submitted all remote-enqueue requests
Dwn-cvts replayed, VALBLKs dubious
All grantable enqueues granted
Fri Dec 18 12:29:45 2009
LMS 0: 2997 GCS shadows traversed, 978 replayed
Fri Dec 18 12:29:45 2009
LMS 1: 3178 GCS shadows traversed, 927 replayed
Fri Dec 18 12:29:45 2009
Submitted all GCS remote-cache requests
Fix write in gcs resources
Fri Dec 18 12:29:45 2009
Instance recovery: looking for dead threads
Reconfiguration complete
Fri Dec 18 12:29:45 2009
Beginning instance recovery of 1 threads
parallel recovery started with 7 processes
Fri Dec 18 12:29:46 2009
Started redo scan
Fri Dec 18 12:29:46 2009
Completed redo scan
848 redo blocks read, 96 data blocks need recovery
Fri Dec 18 12:29:47 2009
Started redo application at
Thread 1: logseq 298, block 31520
Fri Dec 18 12:29:47 2009
Recovery of Online Redo Log: Thread 1 Group 9 Seq 298 Reading mem 0
Mem# 0 errs 0: +LLPWDB/racdbidc/onlinelog/loggroup9-1
Mem# 1 errs 0: +LLPWDB/racdbidc/onlinelog/loggroup9-2
Fri Dec 18 12:29:47 2009
Completed redo application
Fri Dec 18 12:29:47 2009
Completed instance recovery at
Thread 1: logseq 298, block 32368, scn 14861724
91 data blocks read, 93 data blocks written, 848 redo blocks read
Switch log for thread 1 to sequence 299
Fri Dec 18 12:29:48 2009
Shutting down archive processes
Fri Dec 18 12:29:53 2009
ARCH shutting down
ARC4: Archival stopped
Fri Dec 18 12:38:48 2009
db_recovery_file_dest_size of 81920 MB is 0.27% used. This is a
user-specified limit on the amount of space that will be used by this
database for recovery-related files, and does not reflect the amount of
space available in the underlying filesystem or ASM diskgroup.
本文转自 jxwpx 51CTO博客,原文链接:http://blog.51cto.com/jxwpx/245284,如需转载请自行联系原作者