信息检索的概念
信息检索(Information Retrieval)是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。狭义的信息检索就是信息检索过程的后半部分,即从 信息集合中找出所需要的信息的过程,也就是我们常说的信息查寻(Information Search 或Information Seek)。
我们在下边研究的lucene就是对信息做全文检索的一种手段,或者说是一项比较流行的技术,跟google、baidu等专业的搜索引擎比起来会有一定的差距,但是对于普通的企业级应用已经是足够了。
什么是lucene
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的 查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中 实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
现在最新的稳定版本是3.6,而且4.0alpha版本也已经推出。
lucene能做什么
首先要明确一点,lucene只是一个软件类库,或者一个工具箱,而并不是一个完整的搜索程序。但是它的API非常简单,可以让你不用了解复杂的索引和搜索实现的情况下,通过它提供的API,来完成非常复杂的事务处理。
你可以把站内新闻都索引了,做个资料库;你可以把一个数据库表的若干个字段索引起来,那就不用再担心因为“%like%”而锁表了;你也可以写个自己的搜索引擎……
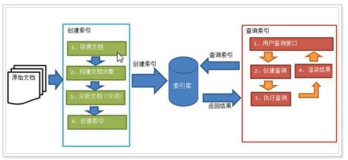
应用程序和lucene之间的关系
lucene的工作过程是首先建立索引,将索引保存,然后对索引进行搜索,并且根据搜索的结果找到对应的数据的过程。
关系结构如下:

图:应用程序和lucene之间的关系
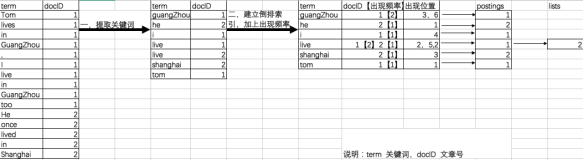
lucene中的几大组件
一、索引组件
创建索引的过程就是首先“获取内容”,然后根据获取的内容“建立文档”,对文档进行“文档分析”,最后对文档建立“文档索引”的过程。
1、获取内容
获取内容的手段很多,可以从上图的输入渠道中看到,包括数据库、文件系统、网络等多种渠道。
在有些情况下,获取内容的工作很简单,比如索引指定目录下的文件、将数据库中的内容读出并进行索引等。
但是有些情况下,获取内容的工作会很复杂,如操作文件系统、内容管理、各种web站点的数据等。
内容获取完全可以通过下面提供的开源软件进行获取,当然这里只是列出了其中的一部分:
- solr:Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
- nutch:Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎。
- grub:Grub Next Generation 是一个分布式的网页爬虫系统,包含客户端和服务器可以用来维护网页的索引。
- Heritrix:Heritrix是一个开源,可扩展的web爬虫项目。Heritrix设计成严格按照robots.txt文件的排除指示和META robots标签。
- Aperture:Aperture这个Java框架能够从各种各样的资料系统(如:文件系统、Web站点、IMAP和Outlook邮箱)或存在这些系统中的文件(如:文档、图片)爬取和搜索其中的全文本内容与元数据。
- jcrawl:jcrawl是一款小巧性能优良的的web爬虫,它可以从网页抓取各种类型的文件,基于用户定义的符号,比如email,qq。
2、建立文档
文档是lucene中建立的小数据块,也就是说,必须先将这些获得的内容转换成文档,文档中几个带值的域主要包括:标题、正文、摘要、作者和链接等。
lucene提供了API来建立域和文档,但不提供任何建立它们的程序逻辑。
有一些应用可以很好的完成这些工作,下面也列出其中一部分,仅供参考:
- Tika:Tika是一个内容抽取的工具集合(a toolkit for text extracting)。它集成了POI, Pdfbox 并且为文本抽取工作提供了一个统一的界面。其次,Tika也提供了便利的扩展API,用来丰富其对第三方文件格式的支持。
- DBSight:DBSight是一个J2EE的搜索平台,可扩展的即时全文搜索任何关系型数据库,对初学者和专家。它具有内置的数据库抓取以下用户定义的SQL ,增量索引,配置的结果排名,突出显示的搜索结果(如谷歌) ,计数和分类结果(如亚马逊) 。脚手架支持标签云, AJAX搜索建议,以及拼写检查。它可以轻松地实现与其他语言的使用XML /简称JSON / HTML格式。有一个用户界面的所有业务,因此没有Java的编码是必要的。删除或更新记录的数据库可以同步。内容以外的数据库还可以进行搜查。
- Hibernate Search:Hibernate Search的作用是对数据库中的数据进行检索的。它是hibernate对著名的全文检索系统Lucene的一个集成方案,作用在于对数据表中某些内容庞大的字段(如声明为text的字段)建立全文索引,这样通过hibernate search就可以对这些字段进行全文检索后获得相应的POJO,从而加快了对内容庞大字段进行模糊搜索的速度(sql语句中like匹配)。
- Compass:Compass是一个强大的,事务的,高性能的对象/搜索引擎映射(OSEM:object/search engine mapping)与一个Java持久层框架.
3、文档分析
就是分析如何建立索引,怎样规划,lucene中提供了大量内嵌的分析器能让你轻松控制这些操作。
4、文档索引
也就是建立索引的过程,并且通过一个异常简单的API来完成索引操作。
二、搜索组件
搜索处理的过程就是用户根据“用户搜索界面”,“建立查询”,并且根据“搜索查询”,得到“展现结果”的过程。
1、用户搜索界面
我们最熟悉的当然就是baidu和google了。

图:baidu搜索界面
2、建立查询
根据提交过来的搜索请求,将查询的条件组合起来并且交给lucene的查询解析器中,并且对查询的内容进行分析处理的过程。
3、搜索查询
根据查询解析器组合的查询条件,查询检索索引并返回与查询语句匹配的文档的过程。
4、展现结果
一旦获得匹配的文档就将结果展现出来的过程,类似于我们日常用到的搜索后的列表。

图:baidu展现结果页面
三、其它组件
1、管理组件
如爬虫要爬取时的规则的规则、时间等需要在管理界面进行统一的设置,对于搜索日志的管理等。
2、分析组件
对于某些关键詷搜索的频率,次数及搜索的习惯等进行分析的部分。
3、搜索范围
即搜索的范围是本机的,还是在分布式环境下的,还是基于其它系统的,也就是一个范围的划分和界定。