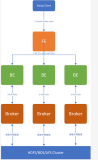
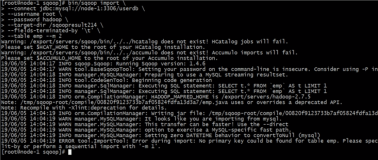
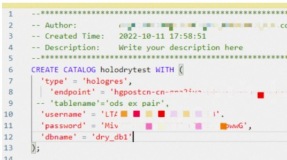
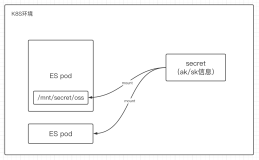
{
"job": {
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [{
"querySql": ["SELECT id, UserID, Ip, CreatTime FROM BWSimpleAdmin_Login_Log"],
"jdbcUrl": ["jdbc:mysql://10.10.59.12:3306/bw_simple_v2"]
}],
"password": "ba8Agx8aB00s#ffR",
"username": "zdp_read"
}
},
"writer": {
"name": "txtfilewriter",
"parameter": {
"fieldDelimiter": "\t",
"fileName": "BWSimpleAdmin_Login_Log ",
"path": "/data/BWSimpleAdmin_Login_Log",
"writeMode": "truncate"
}
}
}],
"setting": {
"speed": {
"record": "1000"
}
}
},
"core": {
"transport": {
"channel": {
"speed": {
"record": "1000"
}
}
}
}
"job": {
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [{
"querySql": ["SELECT id, UserID, Ip, CreatTime FROM BWSimpleAdmin_Login_Log"],
"jdbcUrl": ["jdbc:mysql://10.10.59.12:3306/bw_simple_v2"]
}],
"password": "ba8Agx8aB00s#ffR",
"username": "zdp_read"
}
},
"writer": {
"name": "txtfilewriter",
"parameter": {
"fieldDelimiter": "\t",
"fileName": "BWSimpleAdmin_Login_Log ",
"path": "/data/BWSimpleAdmin_Login_Log",
"writeMode": "truncate"
}
}
}],
"setting": {
"speed": {
"record": "1000"
}
}
},
"core": {
"transport": {
"channel": {
"speed": {
"record": "1000"
}
}
}
}
}
本文转自巧克力黒 51CTO博客,原文链接:http://blog.51cto.com/10120275/1783506,如需转载请自行联系原作者