
Sigma 是阿⾥巴巴全集团范围的 Pouch 容器调度系统。2017年是 Sigma 正式上线以来第⼀次参与双11,在双11期间成功⽀撑了全集团所有容器(交易线中间件、数据库、⼴告等⼆⼗多业务)的调配,使双11IT成本降低50%,是阿⾥巴巴运维系统重要的底层基础设施。
Sigma 已经是阿里全网所有机房在线服务管控的核心角色,管控的宿主机资源达到几十万量级,重要程度不言而喻,其算法的优劣程度影响了集团整体的业务稳定性,资源利用率。
Sigma-cerebro 系统是 Sigma 系统的调度模拟系统,可以在无真实宿主机的情况下,以最小成本,最快速度模拟线上1:1机器资源和请求要求的调度需求完成情况,从各个角度进行扩缩容算法的评测。在对抗系统资源碎片化,在有限资源条件下大批量扩缩容,预期外超卖等问题的过程中,系统一步步发展成现在的样子。
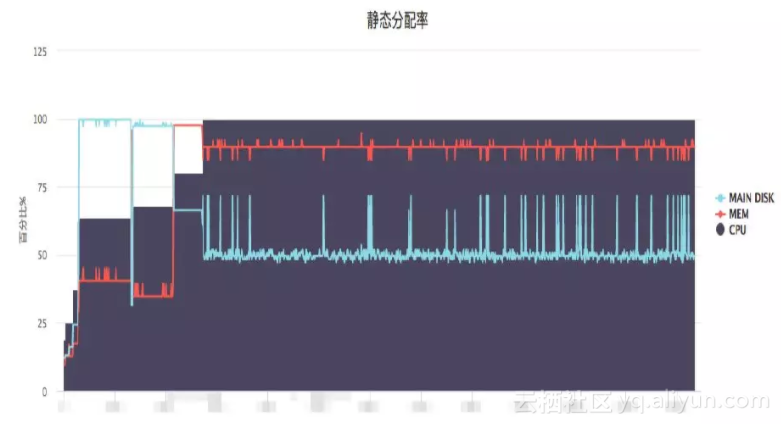
在2017年双11中,依靠 cerebro 进行预处理,Sigma 成功完成了双11一键建站,30分钟内完成建站任务,且系统静态分配率从66%提升到95%,大大提升了资源利用的有效性。
什么是好的调度?最理想的情况如何?
我认为在满足容器的资源运行时,最小化互相干扰的前提下,越能够节省集群整体资源,提高利用率,在固定时间内完成分配的调度系统,较符合理想的调度系统。
那么一个调度算法仿真评测的系统,要做到什么程度?
- 要能够真实模拟生产的大规模环境和复杂需求;
- 要尽量节省模拟的开销,避免模拟的风险;
- 从静态和动态的角度都能够给第一个问题以定性定量的回答。
在这个基础上,我们来看看 Sigma 的副产品,Sigma-cerebro 调度模拟器。
Sigma-cerebro 调度模拟器
调度模拟器设计
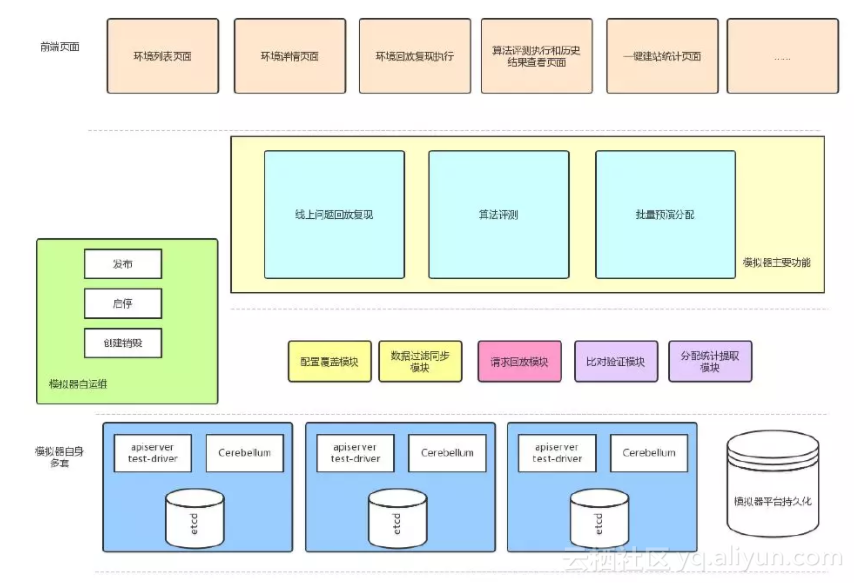
总的来说,目前的模拟器是一个使用1:1生产环境数据来进行调度分配仿真的工具平台。
该仿真目前是纯数据层面的,动态预测也是基于静态数据的。原因是要1:1模拟线上,而线上动辄万台宿主,是不可能真的动用这么多资源的。另外后续也计划搞小规模的池子进行全动态的 runtime 仿真和评测。
模拟器需要同时满足很多需求,因此分成了多套环境,有一个环境池。每个环境池,仅需要3个容器即可完成全套任务。
背景数据是存放在OSS中的,因为一套背景数据可能非常大,另外解耦和线上的依赖将风险降到最低,因此仿真时仅需要从OSS取数据即可。在各种仿真下,用户需要的服务是不同的,因此模拟器设计了几个不同的模式来进行支持。这些模式即可对应前面的4 个需求。
目前已有的模式包括:扩、缩容算法评测模式,预分配模式,问题复现模式。
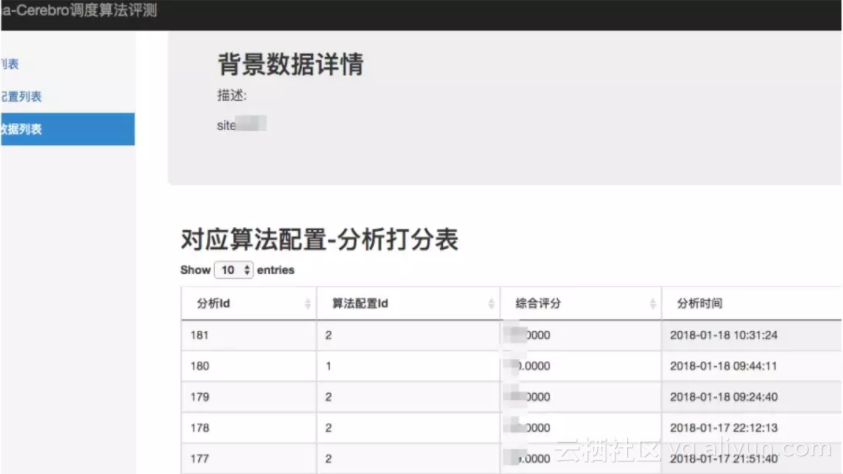
对于如何衡量调度分配结果的优劣问题来说,模拟器支持将算法配置透出,支持用户自定义水位配置和调度器,模拟器会负责将一套线上1:1宿主机数据,应用要求配置等写入该环境,并将用户的算法配置写入,然后将每次相同的请求发送到该环境,待结束后用同样的方式进行打分。
针对同样的一份背景数据,不同的算法配置和版本会产生不同的打分,我们就可以观察他们之间的优劣。如下图:
另外,可以快速在模拟器环境下进行资源的预分配,之后精准按照本次预分配,预热少量镜像到宿主机,使用亲和标的方式,解决如何在宿主机IO有限情况下应对快速扩容多种容器的需求问题。
为什么需要调度模拟器?
容器调度中有如下几个业务问题:
1. 如何衡量调度分配结果的优劣?
2. 大批量应用一键建站时,如何克服镜像拉取慢的问题?
3. 大批量应用同时一次性建站分配时,如何准确进行资源评估?
4. 如何在测试环境复现线上的调度问题?
Sigma 调度模拟器以最低的成本和风险引入即可给上述问题一个可行的解答。
下面将针对每个业务问题进行阐述。
1.1 如何衡量调度分配结果的优劣
首先,容器的调度过程一定会存在一定的碎片化情况。
让我们先从单维度的CPU 核分配谈起。想象如下最简化的场景:我们的某个总资源池仅仅有2台宿主机,每台宿主机各自有4个空闲的CPU可分配。示意图如下:
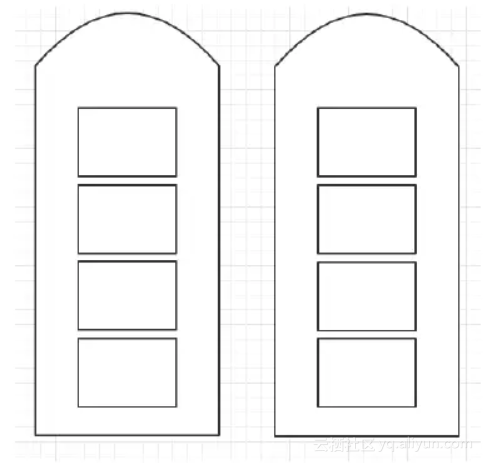
我们要分配给3个容器:2核容器A,2核容器B,4核容器C。
设想A和B的请求先至,如果我们的分配算法不够优秀,那么可能出现如下分配场景。可以很明显看出,应用C无法获得相应资源,而整个系统的静态分配率仅有50%,浪费较大。
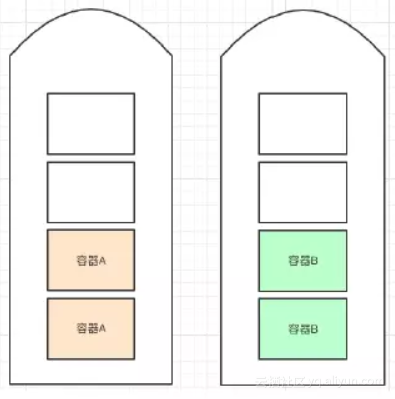
理想的分配结果当然是如下图:3 个容器全部被分配成功,总的静态分配率为100%。如果容器的资源本身需求是合理的话,那么浪费会很小。
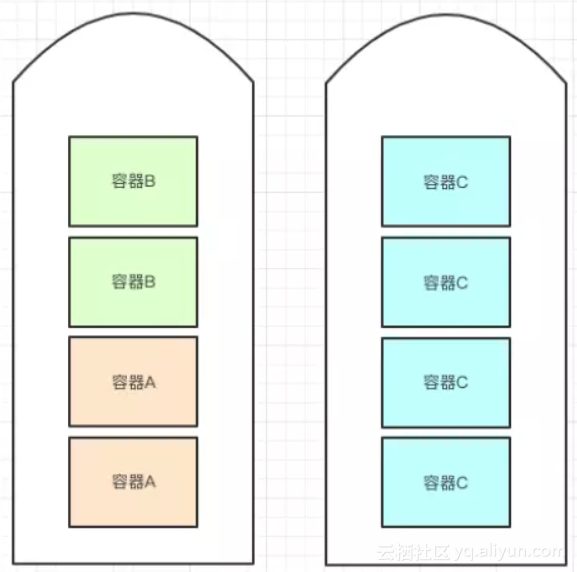
当然,大家知道上面举的例子仅仅是个最简单的背包问题。
我们现在把这个场景复杂化一步。
系统要调配的资源不止 CPU 一种,Sigma 配合的 Pouch 能够支持多种资源隔离,包括内存等。多种资源给背包问题增加了一个可能的错误解法如下图:
上图中可以看出,部分宿主机的 CPU 资源已经被耗尽,虽然内存和磁盘资源还有剩余,但也无法再被分配了。而另外有一些宿主机的 CPU 资源还颇有剩余,但是却由于内存或硬盘资源的不足,而无法被利用了。可以看出其中必定存在着调配的不合理之处,造成相当的资源浪费。
让我们将这个场景再复杂化一步。
为了保证被调度容器中服务的容灾以及其他运行时状态需求,调度系统在进行调度时,允许业务应用分类设置自己独特的机型要求,独占要求,互斥和亲和要求等。这些强弱规则无疑将这个背包问题又复杂化了一些。
让我们将这个场景再复杂化一步。
在线和离线任务混布,如果在线任务决定根据当前业务服务需求,可以下掉一部分容器释放资源给离线任务运行,那么缩容哪些实例是更为合理的,是最优的?缩容当然需要考虑,那么扩容分配的时候是否需要考虑到这个情况?
再复杂化一步。
在满足前面所述条件的前提下,分配是有时间限制的,虽然不是非常 critical。一般每个请求至多180s内每个需求要得到返回,同时管控的宿主机规模在万级别。
同时要考虑请求的并发程度,可能较高。
使用 Sigma 调度模拟器,提供了拟真的生产背景环境数据和需求请求,对静态资源的调配,可进行一个比较清晰的评估。
1.2 如何在宿主机IO有限情况下应对快速扩容多种容器的需求
在历史的性能测试和生产数据中分析可知,最最耗费容器创建时间的,可能是宿主机层面的 Docker 镜像下载和解压时间,根据历史经验,可能占到一半以上的耗时,如果出现极端长的耗时,一般是这个阶段卡住导致。
- 在一键建站场景下,要求30分钟内完成1.6w个容器的创建;
- 快上快下场景下,要求5分钟内完成5k个容器的创建。
阿里的 Pouch 使用了基于 P2P 技术的蜻蜓来进行镜像分发,因此在大规模镜像下载时是很有优势的。除此之外也有镜像的预加载手段能够缩短实际容器创建时的对应时间。
但是某些时候宿主机的磁盘容量较小,而阿里的富容器镜像又比较大,当一次一键建站应用种类过多时,如果全部镜像种类都预热到对应机器上,那么磁盘是不够用的。
另有部分宿主机,磁盘IO能力较弱,即使蜻蜓超级节点预热充分,解决了网络IO时间长的问题,但是到宿主机磁盘层面,仍然会卡较久,甚至到 timeout 也无法完成。
因此如果能够预先精准地知道宿主机上究竟会用到哪些容器,就可以针对性精准预热少量容器,从而解决如上问题。通过模拟器的预分配,可解决该问题。
当然还有另外的更优雅的解决方案,这里不赘述。
1.3 如何进行资源需求预算预估
前面1.1介绍了资源的碎片化情况,在算法未经充分优化的情况下,碎片率可能是很高的。因此一次建站是否需要增加宿主机,需要增加多少宿主机,就不是一个直接资源叠加的简单问题了。如果估算过多可能浪费预算,如果估算过少又影响使用,如何适量估计是个问题。
1.4 如何在测试环境复现线上的调度问题
生产环境场景比较丰富,可能出现一些在测试环境下未曾预测到的场景,出现一些预期外的问题。要稳定而无生产影响地复现生产环境的问题,就可以给问题修复一个比较清晰的指引。
后续计划
前面已经讲过,目前的全部模拟都是静态的。这里还有两个问题:
1. 如果静态需求满足了,各种微服务就一定能够和谐相处,运行到最佳吗?怎样的应用组合是最有效的?
2. 通过 cpushare 等方式,是否更能削峰填谷,有效利用资源?
这些问题都不是目前的静态模拟能够回答的。因此,后续计划进行理想化正交动态模拟的方式做一些尝试和静态互补,推动调度算法的发展。
未来这样具有混部能力的混合云弹性能力将通过阿里云开放,让用户以更低的成本获得更强的计算能力,进而帮助整个社会提高资源效率。
原文发布时间为:2018-03-6
本文作者:何颖
