人脑是一个令人难以置信的复杂器官,由100亿个相互关联的神经细胞组成。即使在最强大的超级计算机帮助下,目前也不可能在这种尺寸的网络中模拟神经元信号的交换。
不过,近日,一个国际研究小组已在实现E级超级计算机上模拟大脑网络迈出了决定性的一步,该项研究允许使用相同数量的计算机内存来代表人脑中较大的部分,新算法显著加速了现有超级计算机上的大脑模拟效果。这项研究发表在Frontiers in Neuroinformatics上。
“自2014年以来,我们的软件可以模拟人脑中大约百分之一的神经元之间的联系”德国于利希神经科学和医学研究所(INM-6)主任Markus Diesmann说。为了实现这一壮举,该软件运行需要千兆超级计算机,例如神户的K计算机和于利希的超级计算机JUQUEEN。
Diesmann研究模拟软件NEST已经20多年。NEST是一个免费、开源模拟代码,被神经科学界广泛使用,同时也是欧洲类脑计划的核心模拟器。而Diesmann本人在欧洲类脑计划中领导理论神经科学和高性能分析与计算平台领域的项目。
使用NEST,网络中每个神经元的行为都由一些数学方程来表示。未来的E级计算机,比如计划在神户建设的Post-K计算机和于利希建设的JUWELS计算机,它们的性能将超过当今高端超级计算机10到100倍。而这将是研究人员第一次拥有模拟人类大脑这样大规模神经网络的计算机能力。
看起来是死路一条:模拟人脑规模,处理器的内存要比超级计算机大100倍
尽管目前的仿真技术使研究人员有能力开始研究大型神经网络,但它也代表了E级技术发展的终点。目前的超级计算机由大约10万台称为节点的小型计算机组成,每台计算机都配备了多个进行实际计算的处理器。
“在进行神经元网络模拟之前,需要虚拟地创建神经元及其之间的连接,这意味着它们需要在节点的存储器中实例化。在模拟过程中,神经元不知道其目标神经元在哪一个节点。因此,它的短电脉冲需要发送给所有节点,然后每个节点再检查这些电脉冲中的哪一个与该节点上存在的虚拟神经元相关。”斯德哥尔摩KTH皇家理工学院的Susanne Kunkel解释说
对于现阶段来说,这种网络创建的算法是有效的,因为所有节点同时构建其网络的特定部分。但是,将所有电脉冲发送到所有节点并不适合在E级系统上进行仿真。
“为了有效地检查每个电脉冲的相关性,需要整个网络中每个神经元的每个处理器都有一个信息位。对于一个有10亿个神经元的网络来说,每个节点的大部分内存都将被神经元的这一个信息位所消耗。”Diesmann补充到。
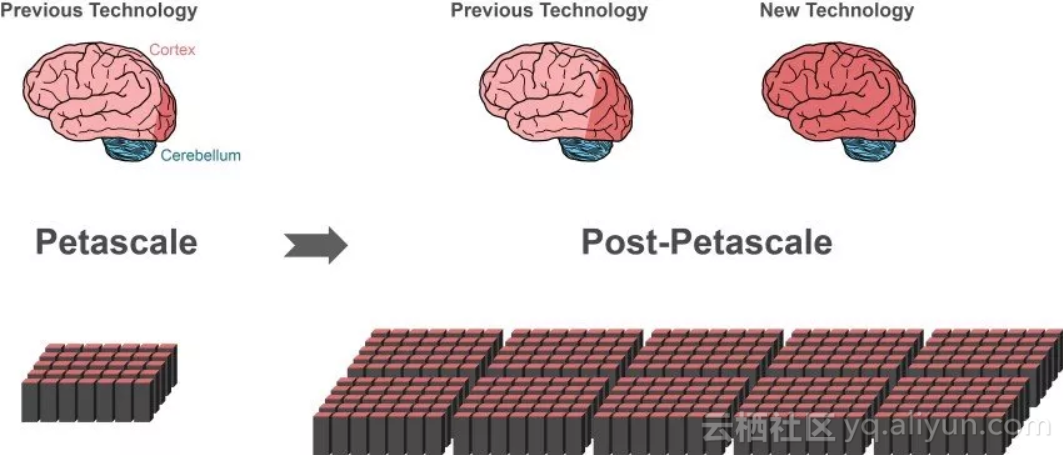
使用千万亿次超级计算机(左下),以前的模拟技术可以模拟人脑中大约1%的神经细胞(神经元)(图片左侧大脑暗红色区域)。尽管下一代超级计算机的性能超过当今超级计算机的性能10到100倍,应用以前的模拟技术在大脑的模拟上也只能有很小的进展(图片中间大脑暗红色区域)。使用相同数量的计算机内存(右下角),可以用该研究提出的新技术模拟人类大脑的更多部分。我们大脑的10%约等于整个大脑皮层的大小(图片右侧大脑的深红色区域),高达140亿个神经细胞,这是更高级的处理必不可少的。另一部分神经元位于小脑(蓝色部分)。图片来自Forschungszentrum Jülich
这就是模拟更大网络时遇到的主要问题:每个处理器所需的计算机内存量随着神经元网络的增大而增加。如果要模拟人脑的规模,这就要求每个处理器的可用内存比现在的超级计算机大100倍。但是,这在下一代超级计算机中并不太可能出现,下一代计算机中每个计算节点的处理器数量或许会增加,但每个处理器的内存和计算节点的数量将保持不变。
新算法的突破:节点间的神经元活动数据交换有条理,不必为神经元增加比特
神经信息学前沿的突破性成果是创建了超级计算机神经元网络的一种新算法。由于这个算法,每个节点上所需的内存不再随着网络增大而增加。
在模拟开始时,新技术允许节点交换关于谁需要发送神经元活动数据的信息给谁。一旦获得了这一知识,节点间的神经元活动数据交换就是有条理的,如此各节点只接收它需要的信息,而不必再为网络中的每个神经元添加一个比特。
有益的另一面:使现有的超级计算机模拟速度更快
在测试新算法的时,科学家们提出了另一有益的发现,Susanne Kunkel说:“当分析新算法时,我们意识到这项新技术不仅能完成E级系统的模拟,同时还会使现有的超级计算机模拟速度更快。”
事实上,随着内存消耗得到控制,模拟的速度成为技术进一步发展的主要焦点。例如,在于利希的超级计算机JUQUEEN上运行的由5.8万亿突触连接的大型模拟神经网络需要28.5分钟来计算一秒钟的生物时间。随着仿真的数据结构改进,时间减少到了5.2分钟。
利用这项新技术,我们可以比以前更好地利用现代微处理器的并行性,这在E级计算机中将变得更加重要。”该项研究的主要作者Jakob Jordan评论道。
E级硬件和相应软件的结合促进了对大脑基本功能的研究,比如可塑性和如何快速学习。”Markus Diesmann说。
在模拟软件Nest的下一个版本中,研究人员将把他们的成果作为开源资源免费提供给社区。
“我们一直在K计算机上使用NEST来模拟健康的人和帕金森病人的大脑基底核回路的复杂动态。我们很高兴听到关于新一代NEST的消息,这将使我们能够在Post-K计算机上运行全脑模拟来阐明运动控制和心理功能的神经机制。”冲绳科学技术研究院(OIST)的Kenji Doya说。
“这项研究将是构建E级计算机国际合作一个很好的例子。重要的是,我们已经准备好应用程序,在这些超级计算机建设出来的第一天就能使用。”神户理化学研究所的Mitsuhisa Sato最后总结道。
原文发布时间为:2018-03-7
本文作者:谢永芬
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号