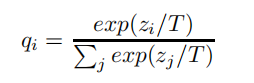热门
android检测网络连接是否存在(一)
Vue3 五天速成(上)
Android应用] 问题2:ERROR: unknown virtual device name:
怎样查找某个目录下内容含有某个字符串的文件
一些常见的ip代理协议的类型有哪些?以及它们的特点?
chapter 2 数列极限
面向对象——多态,抽象类,接口(二)-2
chapter 1 实数集与函数
AIX上如何正确挂载Linux 的nfs共享目录分享篇
前端进度条组件NProgress
面向对象——多态,抽象类,接口(二)-1
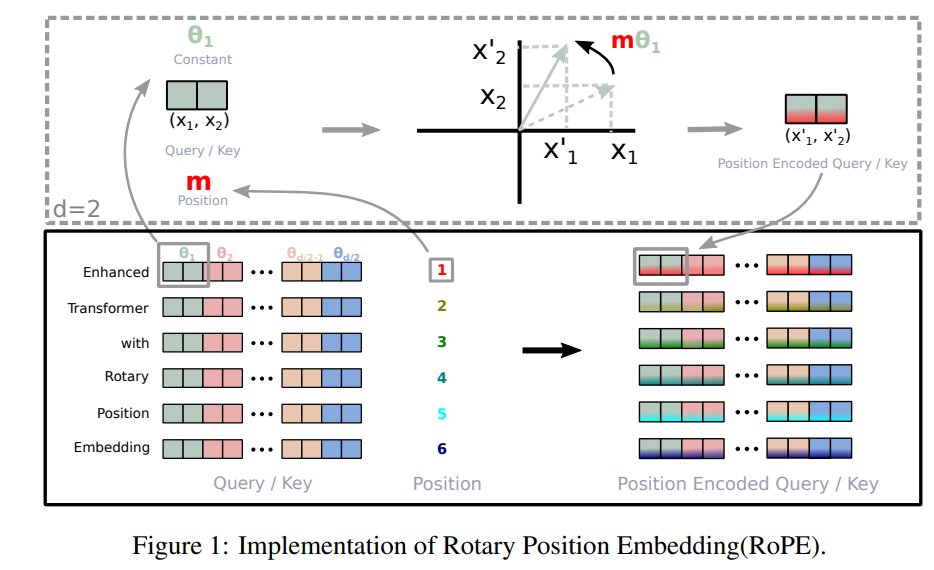
关于RoPE旋转位置编码的理解
Solaris中查看硬件信息常用命令
C语言:预处理
【RetNet】论文解读:Retentive Network: A Successor to Transformer for Large Language Models
int 和 String 互相转换的多种方法
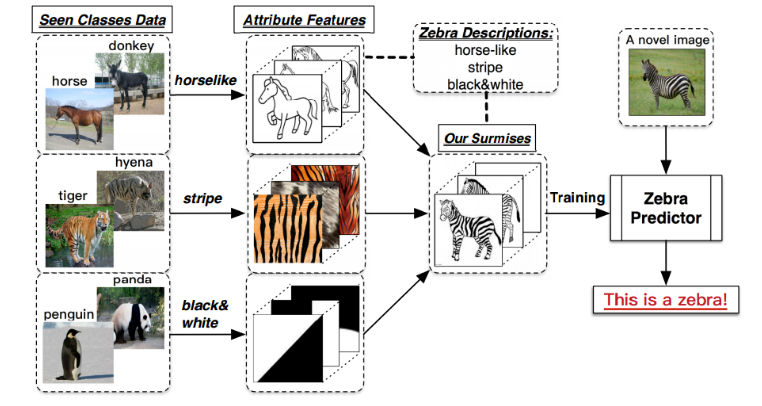
【ChatIE】论文解读:Zero-Shot Information Extraction via Chatting with ChatGPT
[GPT-2]论文解读:Language Models are Unsupervised Multitask Learners
[JS]百度地图设置城市
如何去除AIX operator&p560面板黄色指示灯的报警
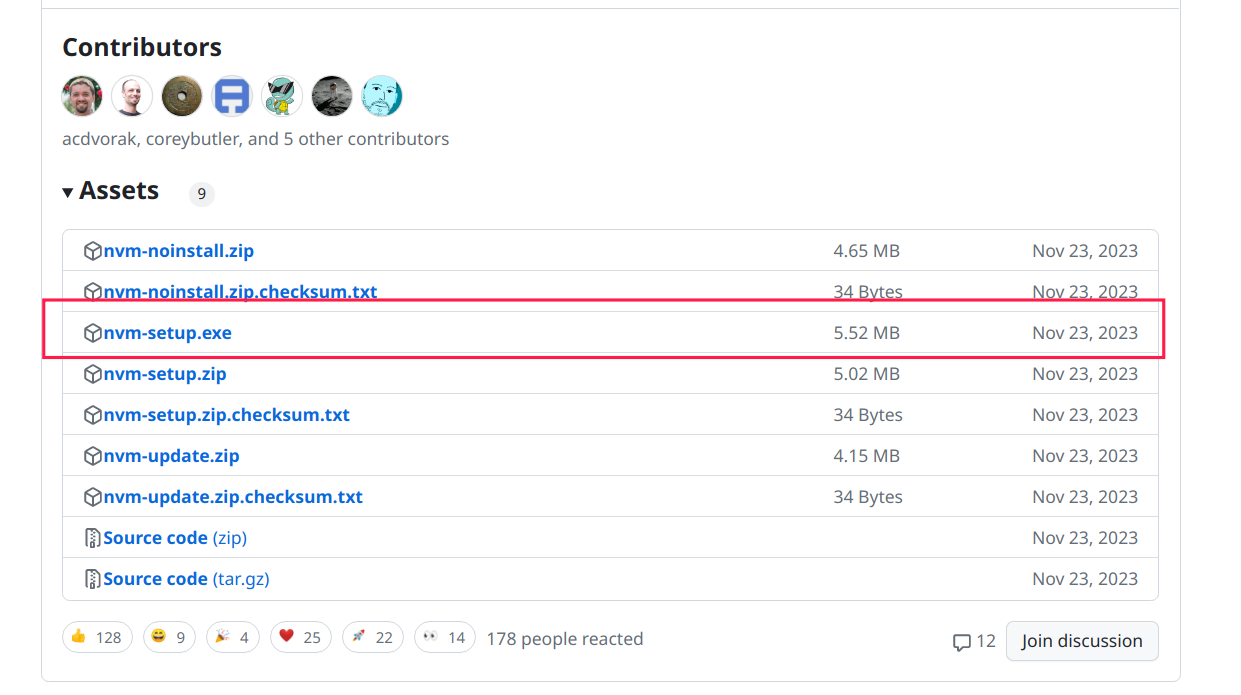
nvm, node.js, npm, yarn 安装配置
Android控件动态使用 (转)
自己总结的aix的常用命令
ES6 速通(下)
SAP CLIENT 数据配置文件的导出/导入
ES6 速通(中)
Android教程之Android 用户界面-表格视图(GridView)
Android如何显示音标
ES6 速通(上)
对于Android的http请求的容错管理
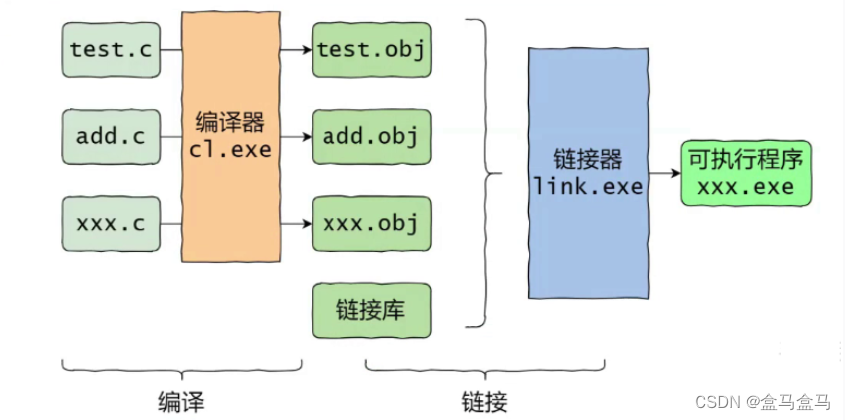
C语言:编译与链接
Android之日期及时间选择对话框
转Android上基于JSON的数据交互应用
Android五大布局对象---FrameLayout,LinearLayout ,Absolute
conda 安装, 配置以及使用
建立ubuntu下基于eclipse的android开发环境
前端效果 登入界面
vue前端展示【1】
Android Froyo基于32 bit ubuntu 10.10编译问题
nvm,npm,yarn相关指令,前端配置准备
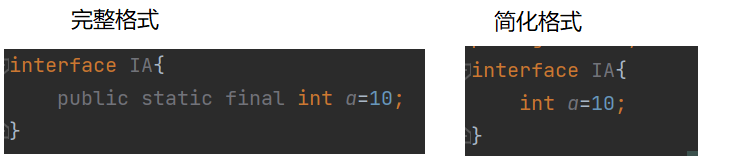
Java一分钟之-抽象类与接口的应用场景
[FNet]论文实现:FNet:Mixing Tokens with Fourier Transform
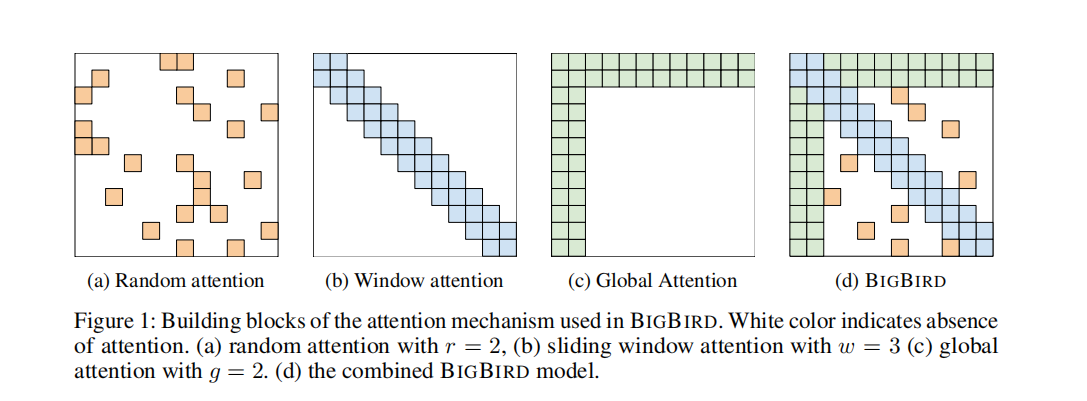
[Big Bird]论文解读:Big Bird: Transformers for Longer Sequences
[Knowledge Distillation]论文分析:Distilling the Knowledge in a Neural Network
修改windows server 2008 时间和日期格式
Java一分钟之-多态性:理解重写与接口
[Linformer]论文实现:Linformer: Self-Attention with Linear Complexity
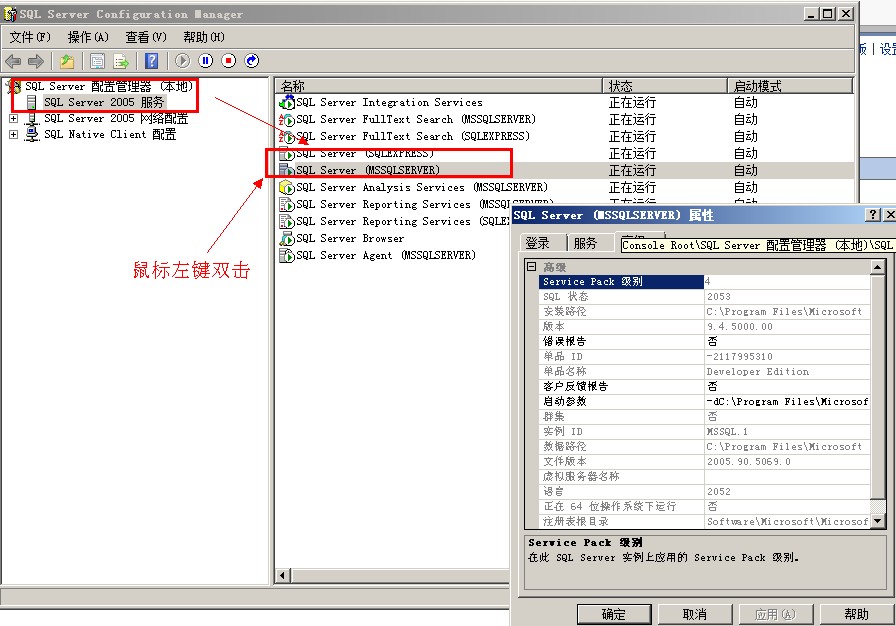
如何查看SQLSERVER的版本信息和SP补丁信息
[Longformer]论文实现:Longformer: The Long-Document Transformer
IIS6: IIS内存释放问题