|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
|
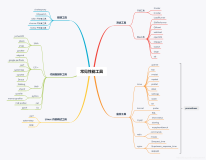
一、概述
二、什么是性能调优?(what)
三、为什么需要性能调优?(why)
四、什么时候需要性能调优?(when)
五、什么地方需要性能调优?(where)
六、什么人来进行性能调优?(who)
七、怎么样进行性能调优?(How)
http:
/
/
freeloda.blog.
51cto
.com
/
2033581
/
1438052
,非常有用
服务器选型都有讲到
有的硬件不能满足业务需求,所我们这时需要更换更好的CPU、更大的内存和更快的磁盘。
至于如何找出硬件是性能瓶颈
操作系统优化包括哪些:
操作系统安装优化
系统初始化
进程调优
内存调优
IO 调优
文件系统调优
网络调化
运维应该特别注意,项目上线后,要紧紧盯住监控
性能指标 –> 确认衡量标准
性能测试 –> 验证性能指标
性能分析 –> 找出性能瓶颈
性能调优 –> 解决性能问题
性能监控 –> 检验调优效果
1.
性能指标
上面我们说了,我们优化的目的是为了获得更好的性能,那么性能指标是什么呢?我们怎么样来衡量,一般衡量一个项目(这里指的网站)的指标有三个:
吞吐量 –> 是单位时间内完成的用户或系统的请求数量。
并发数 –> 同时能接受多少用户的访问请求
响应时间 –> 用户发出请求到收到响应的时间间隔。
磁盘性能指标
-
-
IOPS、吞吐量及测试
http:
/
/
wushank.blog.
51cto
.com
/
3489095
/
1708168
2.
性能测试
我们做产品或者说项目(更直白的说是网站)目的是为了让用户使用,我们得先站在用户的角度分析一下,用户需要关注哪些性能,对于用户来说,当点击一个按钮、链接或发出一个操作指令,到系统把请求处理好发给用户并用网页的形式展现出来为止,这个过程中所消耗的时间是用户对这个网站性能的直观印象。也就是我们所说的响应时间,当响应时间较小时,用户体验相对来说就会好,当然用户体验的响应时间包括个人主观因素和客观响应时间。在网站开发与搭建时,我们就需要考虑到如何更好地结合这两部分达到用户最佳的体验。用户关注的是用户操作的相应时间。其次,我们站在运维的角度考虑需要关注的性能点。再次,我们得站在开发(设计)人员角度去考虑网站性能。最后,由QA测试与反馈我们网站性能。 经过上述的说明,我们来测试系统的性能,需要我们收集系统的吞吐量、并发数、响应时间这三个重要的指标。具体步骤是:
确认吞吐量、并发数、响应时间这三个值
找到或开发相应的性能测试工具
进行性能测试
反馈结果并提交测试报告
结果,有两个一种是达到我们预期的性能目标,这样我们就不需要性能优化任务完成可以交给运维上线,只需要进行相关的性能监控,方便上线后进行性能优化。另一种是没有达到我们预期的目标,我们要查找性能瓶颈并进行性能优化。
3.
性能分析
通过上面的性能测试,我们发现网站没有达到我们预期定义的性能目标,这时我们需要做的就是对现有的系统(服务器)进行监控,包括硬件与软件监控,为性能调优提供有效的性能监控数据。下面我们重点来说一下,用什么工具能找出性能瓶颈:
硬件:
用vmstat、sar、iostat检测是否是CPU瓶颈
用free、vmstat检测是否是内存瓶颈
用iostat检测是否是磁盘I
/
O瓶颈
用netstat检测是否是网络带宽瓶
……
操作系统:
进程
文件系统
SWAP 分区
内核参数调整
……
应用程序(MySQL等):
mysqlreport 性能分析报告
mysqlsla 慢查询日志分析
……
4.
性能调优
确定调优目标
具体调优步骤
检测调优结果
(
1
). 确定调优目标
我们性能优化的目标是网站性能提高
10
%
还是
20
%
,不能老大说今天你给我优化一下网站性能,你就能使用网站性能翻一倍。首先,你要问他我们需要达到一个怎么的目标。然后,我们要了解一下整个环境(架构)包括代码(当然你需要了解一下业务逻辑,大致了解一下,肯定没坏处),有时间多和开发沟通一下,问问代码中有多少坑要填,这很重要。往往他们优一下代码中的SQL查询,比你优化系统多少天都来的有效果,哈哈。
(
2
). 具体调优步骤
如果你不懂系统的参数,你千万不要对系统的参数进行随意的改动,不然你会后悔。
每次只对一种系统资源进行系统调试,如CPU、或内存、磁盘。
每次改动尽量少的参数设置,推荐每次修改一个设置。
分析一项系统资源时,使用多种工具,往往有意想不到的结果。
不及胜于过之(宁愿少做一点,不要做过头了,性能已达到要求就不要随意乱动,做好你的监控)。
(
3
). 检测调优结果
每次性能调优后必须对性能进程检测,如Web服务器的ab工具,就是一个很好的检测工具,每次调优后都能看到具体的变化。
5.
性能监控
性能监控这个很重要,具体包括服务器性能监控和具体服务的性能监控。下面我们说一说具体有哪些性能监控指标:
(
1
).服务器的性能监控
CPU 使用率
CPU负载
内存使用率
磁盘I
/
O
网络流量
磁盘空间
系统进程
性能监控的指标,性能监控无非就是从I
/
O,内存,CPU,TCP连接数,网络,进程或者线程来出发,
使用到的命令有iostat,vmstat,sar,mpstat,netstat,ss,iftop,free,pstree
/
ps,pidstat,top,uptime
1.vmstat
r b swpd free buff cache si so bi bo
in
cs us sy
id
wa st
如果r大于
3
或
4
,且
id
小于
%
50
,则CPU是瓶颈。
wa经常不等于
0
,b中的队列较大,则IO是瓶颈。
如bi bo长期不等于
0
,则内存较小
vmstat
2
3
如果si和so长期不为
0
,表示系统内存不足;而如果swpd的值长期不为
0
,但si和so的值长期为
0
,则无需担心
in
和cs的值越大,内核消耗cpu时间越大
2.iostat
iostat [
-
c |
-
d] [
-
k ] [
-
t ] [
-
x [device] ] [ <interval> [ <count> ] ]
Device: rrqm
/
s wrqm
/
s r
/
s w
/
s rsec
/
s wsec
/
s avgrq
-
sz avgqu
-
sz await svctm
%
util
avgrq
-
sz:平均每次IO操作的数据大小(扇区),即(rsec
/
s
+
wsec
/
s)
/
(r
/
s
+
w
/
s)
%
util:一秒中有百分之多少的时间用于IO操作,即(r
/
s
+
w
/
s)
*
(svctm
/
1000
)
iostat
-
xk
1
每一秒打印磁盘相关情况。
几个比较重要的参数做解释:
r
/
s:每秒读次数
w
/
s:每秒写操作
rkB
/
s:每秒读kB大小
wkB
/
s:每秒写kB大小
wait:平均每次设备I
/
O操作的时间
%
util:一秒中有百分之多少的时间用于 I
/
O 操作,即被io消耗的cpu百分比
如果util达到
100
%
说明已经达到磁盘的I
/
O瓶颈,需要优化,或者换成SSD
如果
%
util较大代表IO请求太多,硬盘可能存在瓶颈。
如果avctm比较接近await,说明IO几乎没等待时间。
如果await远大于avctm,说明IO队列太长,应用响应时间也变长。
avgqu
-
sz队列长度也可衡量IO负荷的指标,avgqu
-
sz是单位时间内的平均值。
其它还可参考vmstat结果b参数(等待资源的进程数)和wa参数(IO等待所占用CPU时间百分比)
如果svctm值和await值很接近,则表示I
/
O几乎没有等待,如果await的值远高于svctm的值,
则表示I
/
O队列等待太长
如果是多磁盘,即使
%
util是
100
%
,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈
iostat
-
d
and
iostat
-
c
查看哪一块磁盘占用的磁盘I
/
O比较高iostat
iostat
-
xk
1
sar
-
u
1
3
统计cpu
sar
-
P
0
1
2
第一个cpu
sar
-
d
1
3
io
sar
-
r
1
3
内存
sar
-
n DEV
1
eth0网卡设备,吞吐率大概在
22
Mbytes
/
s,既
176
Mbits
/
sec,没有达到
1Gbit
/
sec的硬件上限
sar
-
n TCP,ETCP
1
sar命令在这里用于查看TCP连接状态,其中包括:
active
/
s:每秒本地发起的TCP连接数,既通过connect调用创建的TCP连接;
passive
/
s:每秒远程发起的TCP连接数,即通过accept调用创建的TCP连接;
retrans
/
s:每秒TCP重传数量;
TCP连接数可以用来判断性能问题是否由于建立了过多的连接,进一步可以判断是主动发起的连接,
还是被动接受的连接。TCP重传可能是因为网络环境恶劣,或者服务器压力过大导致丢包。
uptime
load average的三个输出值如果大于系统逻辑cpu数量时,表示cpu繁忙,会影响系统性能
CPU(dstat,mpstat)
dstat
2
10
cpu:hiq、siq分别为硬中断和软中断次数
system:
int
、csw分别为系统的中断次数(interrupt)和上下文切换次数(context switch)。
-
c:表示只显示我们的CPU信息
-
m:表示只显示我们的内存信息
-
p:表示只显示我们的进程信息
-
n:表示只显示我们的网络信息
我们想以什么为什么优先顺序查看,可以在后面加下列参数,非常有用
-
-
top
-
bio
mpstat
%
user 在internal时间段里,用户态的CPU时间(
%
),不包含nice值为负进程 (usr
/
total)
*
100
%
nice 在internal时间段里,nice值为负进程的CPU时间(
%
) (nice
/
total)
*
100
%
sys 在internal时间段里,内核时间(
%
) (system
/
total)
*
100
%
iowait 在internal时间段里,硬盘IO等待时间(
%
) (iowait
/
total)
*
100
%
irq 在internal时间段里,硬中断时间(
%
) (irq
/
total)
*
100
%
soft 在internal时间段里,软中断时间(
%
) (softirq
/
total)
*
100
%
idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(
%
) (idle
/
total)
*
100
TCP连接数(ss,netstat)
网络(iftop)
iftop
-
i eth0
时时流量查看工具
-
ifsta,nload,iftop
nload 快速查看总带宽使用情况,无需每个进程的详细情况
bmon(带宽监控器)是一款类似nload的工具,它可以显示系统上所有网络接口的流量负载
iftop 可测量通过每一个套接字连接传输的数据
虽然iftop报告每个连接所使用的带宽,但它无法报告参与某个套按字连接的进程名称
/
编号(
ID
)
iftop
-
n
iptraf是一款交互式、色彩鲜艳的IP局域网监控工具。它可以显示每个连接以及主机之间传输的数据量
nethogs是一款小巧的
"net top"
工具,可以显示每个进程所使用的带宽,并对列表排序,将耗用带宽最多的进程排在最上面
pktstat可以实时显示所有活动连接,并显示哪些数据通过这些活动连接传输的速度。它还可以显示连接类型,比如TCP连接或UDP连接
pidstat
pidstat来查看每一个进程的pid的状态信息,以及他所占的CPU信息
http:
/
/
lizhenliang.blog.
51cto
.com
/
7876557
/
1687612
df
-
i |awk
'/^\/dev/{print int($5)}'
#占用CPU高的前10个进程
ps aux |awk
'{if($3>0.1){{printf "PID: "$2" CPU: "$3"% --> "}for(i=11;i<=NF;i++)if(i==NF)printf $i"\n";else printf $i}}'
|sort
-
k4
-
nr |head
-
10
#占用内存高的前10个进程
ps aux |awk
'{if($4>0.1){{printf "PID: "$2" Memory: "$3"% --> "}for(i=11;i<=NF;i++)if(i==NF)printf $i"\n";else printf $i}}'
|sort
-
k4
-
nr |head
-
10
ps
-
p
25063
-
o
%
cpu|sed
-
n
2p
ps aux|grep
-
v PID|sort
-
rn
-
k
+
3
|head
-
n
1
,看到的结果与top看到不一样,命令对不
3.free
清空内存缓存
sync
#先将缓存写入磁盘
echo
1
>
/
proc
/
sys
/
vm
/
drop_caches
#释放buffer cache
echo
2
>
/
proc
/
sys
/
vm
/
drop_caches
#释放page cache
echo
3
>
/
proc
/
sys
/
vm
/
drop_caches
#释放buffer cache和page cache
内存
=
free memory
+
buffers
+
cached
4.
统计当前占用IO最高的
10
个进程
sysctl vm.block_dump
=
1
或echo
1
>
/
proc
/
sys
/
vm
/
block_dump
dmesg |awk
-
F:
'{print $1}'
|sort|uniq
-
c|sort
-
rn|head
-
n
10
查看哪个进程占用的I
/
O过高,使用iotop,ps,lsof
iotop
ps
-
eo state,pid,cmd
for
x
in
`seq
1
1
10
`;do ps
-
eo state,pid,cmd | grep
"^D"
;echo
"-------"
;sleep
1
;done
通过man ps可以查到
D Uninterruptible sleep (usually IO)
R Running
or
runnable (on run queue)
S Interruptible sleep (waiting
for
an event to complete)
T Stopped, either by a job control signal
or
because it
is
being traced.
W paging (
not
valid since the
2.6
.xx kernel)
X dead (should never be seen)
Z Defunct (
"zombie"
) process, terminated but
not
reaped by its parent.
D的状态一般是I
/
O出现了问题,说明进程在等待I
/
O,可以是磁盘I
/
O,网络I
/
O或者其他,详细:
https:
/
/
blog.xupeng.me
/
2009
/
07
/
09
/
linux
-
uninterruptible
-
sleep
-
state
/
lsof
-
p 进程号
为了查看此进程在读哪个文件,或者在写入哪个文件
ps(top) cheatsheet
http:
/
/
jaseywang.me
/
2014
/
12
/
11
/
pstop
-
cheatsheet
/
展开 tid
htop
-
> F2
ps
-
p PID
-
L
-
o pid,tid,psr,pcpu
特定的 pid, tid 跑在哪些 core 上
1.
top
-
H
-
p {PID}
-
> f
-
> j
2.
/
proc
/
{PID}
/
stat
-
> 第三列: running
/
stop,倒数第六列: core
通过
-
o 指定需要获取的条目:
ps
-
eLf
/
ps aux
-
L
ps
-
eLo pid,ppid,lwp,nlwp,osz,rss,ruser,pcpu,stime,etime,args | more
ps
-
eLo pcpu,args | grep java | sort
-
k1
-
r | awk
'{print $1}'
| head
-
n
1
ps ax –no
-
headings
-
o user,pid,
%
cpu,
%
mem,vsz,sgi_rss
ps axo
"user=%u, pid=%p, command line args=%a, elapsed time=%t"
ps axo "Application:
%
c | CommandlineArgs:
%
a | PercentageCpu:
%
C | User:
%
U |
VirtualMemory:
%
z" –sort vsize | tail
上面的说了这么多,其实是为了解决下面这个问题,找出 java 中最耗 cpu 的 tid,jstack 追踪。
要找出这 tid 方式也有很多种,top,ps 都可以实现。
top
-
H |head
-
n
10
|grep java|awk
'{print $1}'
|head
-
n
1
|sed
-
r
's/[^0-9].*m//g'
主要注意的是 top
-
H 直接 grep 出来的有乱码,所以需要通过 sed 处理下,
为了这个问题还花了点时间,最后把结果 pipe 到文件,vim 打开才发现了问题。
ps
-
eLo pcpu,args | grep java | sort
-
k1
-
r | awk
'{print $1}'
| head
-
n
1
ps p {PID}
-
L
-
o time,pid,tid,pcpu,tname,stat,psr | sort
-
n
-
k1 –r
ps 做法会好的多处理起来也更漂亮。
http:
/
/
stackoverflow.com
/
questions
/
1519196
/
finding
-
usage
-
of
-
resources
-
cpu
-
and
-
memory
-
by
-
threads
-
of
-
a
-
process
-
in
-
unix
-
sol
http:
/
/
stackoverflow.com
/
questions
/
8032372
/
how
-
can
-
i
-
see
-
which
-
cpu
-
core
-
a
-
thread
-
is
-
running
-
in
http:
/
/
stackoverflow.com
/
questions
/
3342889
/
how
-
to
-
measure
-
separate
-
cpu
-
core
-
usage
-
for
-
a
-
process
http:
/
/
stackoverflow.com
/
questions
/
8032372
/
how
-
can
-
i
-
see
-
which
-
cpu
-
core
-
a
-
thread
-
is
-
running
-
in
5.htop
wget http:
/
/
ftp.gnu.org
/
pub
/
gnu
/
ncurses
/
ncurses
-
5.9
.tar.gz
tar xvfz ncurses
-
5.9
.tar.gz
cd ncurses
-
5.9
.
/
configure
make
make install
wget http:
/
/
sourceforge.net
/
projects
/
htop
/
files
/
htop
/
0.9
/
htop
-
0.9
.tar.gz
tar zxvf htop
-
0.9
.tar.gz
cd htop
-
0.9
.
/
configure
make
make install
6.
修改最大文件数限制
cat >>
/
etc
/
security
/
limits.conf<<EOF
*
soft nproc
65535
*
hard nproc
65535
*
soft nofile
65535
*
hard nofile
65535
EOF
cat >>
/
etc
/
pam.d
/
login <<EOF
session required
/
lib
/
security
/
pam_limits.so
EOF
查看特定进程限制
cat
/
proc
/
1526
/
limits
7.Linux
禁止atime提高IO性能
cat
/
etc
/
fstab
/
dev
/
VolGroup00
/
LogVol00
/
ext3 defaults,noatime,nodiratime
1
1
mount
-
o remount
/
mount
/
dev
/
mapper
/
VolGroup00
-
LogVol00 on
/
type
ext3 (rw,noatime,nodiratime)
8.Linux
服务器内核网络参数优化
net.ipv4.tcp_syncookies
=
1
#启用syncookies
net.ipv4.tcp_max_syn_backlog
=
8192
#SYN队列长度
net.ipv4.tcp_synack_retries
=
2
#SYN ACK重试次数
net.ipv4.tcp_fin_timeout
=
30
#主动关闭方FIN-WAIT-2超时时间
net.ipv4.tcp_keepalive_time
=
1200
#TCP发送keepalive消息的频度
net.ipv4.tcp_tw_reuse
=
1
#开启TIME-WAIT重用
net.ipv4.tcp_tw_recycle
=
1
#开启TIME-WAIT快速回收
net.ipv4.ip_local_port_range
=
1024
65000
#向外连接的端口范围
net.ipv4.tcp_max_tw_buckets
=
5000
#最大TIME-WAIT数量,超过立即清除
net.ipv4.tcp_syn_retries
=
2
#SYN重试次数
net.ipv4.tcp_rmem
=
4096
87380
4194304
#TCP接收缓冲大小,对应最小、默认、最大
net.ipv4.tcp_wmem
=
4096
16384
4194304
#TCP发送缓冲大小,对应最小、默认、最大
net.core.rmem_max
=
16777216
#最大发送套接字缓冲区大小
net.core.wmem_max
=
16777216
#最大接收套接字缓冲区大小
net.core.netdev_max_backlog
=
262144
#当网络接口接收速率比内核处理快时允许发到队列的数据包数目
net.core.somaxconn
=
262144
#最大连接队列,超过导致连接超时或重传
|
案例
linux性能异常定位之进程级别
http://h2ofly.blog.51cto.com/6834926/1621481
top:综合,偏cpu,内存
dstat:综合、磁盘
iostat:磁盘io,全局
iotop:磁盘io,精确到进程,(类似工具还有pidstat)
iftop:网络、实时刷新(类似工具还有nload,ifstat)
nethogs:进程级别的流量
ss:网络、快、消耗资源低(替代netstat)
pidstat:综合的
free:额,内存。。。
top各行结果我就不详细介绍了,是用起来也比较简单。对于排查cpu是用率过高,比较关键的指令是P和T。
输入了P(冒号P)之后:按照cpu排序
输入T(冒号T):根据时间、累计时间排序,可查看哪些进程消耗历史消耗多
另外:还可以输入以下便捷指令
1:多核
m:是否显示内存信息
M:根据内存排序
H:shift+h,打开线程模式
x:列的高亮(先要按b)
shift+<或者shift+>改变排序的行
这里用来找到cpu暂用率最高的参数如下
dstat -lcm --top-cpu
下图可以看到,ntpd(时间服务)和zabbix的agent消耗cpu多点(其实也不多,才0.x%)
pidstat
直接输入pidstat(或者pidstat -l,会把命令的绝对路径输出)就可以看到进程使用cpu相关数据
查看哪个进程消耗了最多的内存
输入dstat lcmd -top-mem
看到,就puppet消耗了最多的内存59m(正常)
top
输入top之后,输入b,再输入x,再输入shift+’>’或者shif+’<‘调整排序的列到mem,就看到到内存消耗的排序了
一般我们对磁盘关注几个指标:
(1)读写的量/秒:dstat和iostat(全局),iotop或者pidstat(进程级别)
(2)每次读写磁盘的延迟时间:iostat(全局)
dstat,iostat用于查看全局的io情况,要精确到进程用iotop或者pidstat
dstat:可以看到磁盘每秒的读、写取量(单位还整理过,所以一般我看磁盘的读写量都会用这个工具)
iostat就可以看到:磁盘的磁盘每秒的读、写取量并且还可以看到io的延迟效果(一般我看io的延迟会用这个工具)
1、dstat
dstat可以看到每秒读写多少B、K、M的数据
dstat其他参数和常用使用还有:
dstat -g -l -m -s --top-mem
dstat -c -y -l --proc-count --top-cpu
2、iostat
也可以看到类似的效果,而且更加丰富
svctm < await (同时等待的请求的等待时间被重复计算),
如果 svctm 比较接近 await,说明I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明 I/O 队列太长
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒):会将await也计算在内
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
iotop
通过iotop直接看得到io占用最高的进程,直接输入iotop命令
pidstat
通过pidstat -d也可以看到读写磁盘数据多的进程,pidstat -d效果如下
一般网络主要关注性能指标:
(1)出入的流量
(2)连接状态:各个状态如established,timewait等
(3)本地监听,消耗的端口数量等
iftop命令相关参数介绍如下:
-i设定监测的网卡,如:# iftop -i eth1
-B 以bytes为单位显示流量(默认是bits),如:# iftop -B
-n使host信息默认直接都显示IP,如:# iftop -n
-N使端口信息默认直接都显示端口号,如: # iftop -N
-F显示特定网段的进出流量,如# iftop -F 10.10.1.0/24或# iftop -F 10.10.1.0/255.255.255.0
-h(display this message),帮助,显示参数信息
nethogs
nethogs能直接就看到进程级别的流量
直接输入nethogs em2(网卡)就可以看到本地的哪些端口和对端的哪些端口之间的流量,从而就知道哪些进程消耗了很多网络流量了
其他案例
GlusterFS性能调优说明
NVMe设备的性能有多高?
分布式存储系统的优化 Ceph架构及性能优化
高性能linux业务集群架构搭建&优化——index(持续更新)
http://benpaozhe.blog.51cto.com/10239098/1770051
性能调优之网络篇
Ntop性能提升方案
Nicstat 查看所有网卡流量信息
用ss命令替代netstat
性能测试中如何确定并发用户数
对于大型系统、业务量非常高、硬件配置足够多的情况下,5000 用户并发就足够了;对于中小型系统,1000用户并发就足够了
在评定服务器的性能时,应该结合TPS和并发用户数,以TPS为主,并发用户数为辅来衡量系统的性能
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
案例
1
:
iostat等命令看到的是系统级的统计,比如下例中我们看到
/
dev
/
sdb很忙,如果要追查是哪个进程导致的I
/
O繁忙,应该怎么办?
# iostat -xd
...
Device: rrqm
/
s wrqm
/
s r
/
s w
/
s rkB
/
s wkB
/
s avgrq
-
sz avgqu
-
sz await r_await w_await svctm
%
util
sda
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
sdb
0.00
0.00
6781.67
0.00
3390.83
0.00
1.00
0.85
0.13
0.13
0.00
0.13
85.03
dm
-
0
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
dm
-
1
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
dm
-
2
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
0.00
...
进程的内核数据结构中包含了I
/
O数量的统计:
struct task_struct {
...
struct task_io_accounting ioac;
...
};
可以直接在
/
proc
/
<pid>
/
io 中看到:
# cat /proc/3088/io
rchar:
125119
/
/
在read(),pread(),readv(),sendfile等系统调用中读取的字节数
wchar:
632
/
/
在write(),pwrite(),writev(),sendfile等系统调用中写入的字节数
syscr:
111
/
/
调用read(),pread(),readv(),sendfile等系统调用的次数
syscw:
79
/
/
调用write(),pwrite(),writev(),sendfile等系统调用的次数
read_bytes:
425984
/
/
进程读取的物理I
/
O字节数,包括mmap pagein,在submit_bio()中统计的
write_bytes:
0
/
/
进程写出的物理I
/
O字节数,包括mmap pageout,在submit_bio()中统计的
cancelled_write_bytes:
0
/
/
如果进程截短了cache中的文件,事实上就减少了原本要发生的写I
/
O
我们关心的是实际发生的物理I
/
O,从上面的注释可知,应该关注 read_bytes 和 write_bytes。请注意这都是历史累计值,从进程开始执行之初就一直累加。如果要观察动态变化情况,可以使用 pidstat 命令,它就是利用了
/
proc
/
<pid>
/
io 中的原始数据计算单位时间内的增量:
# pidstat -d 2 2
Linux
3.10
.
0
-
229.14
.
1.el7
.x86_64 (bj71s060)
11
/
16
/
2016
_x86_64_ (
2
CPU)
12
:
30
:
15
PM UID PID kB_rd
/
s kB_wr
/
s kB_ccwr
/
s Command
12
:
30
:
17
PM
0
14772
3362.25
0.00
0.00
dd
12
:
30
:
17
PM UID PID kB_rd
/
s kB_wr
/
s kB_ccwr
/
s Command
12
:
30
:
19
PM
0
14772
3371.25
0.00
0.00
dd
另外还有一个常用的命令 iotop 也可以观察进程的动态I
/
O:
Actual DISK READ:
3.31
M
/
s | Actual DISK WRITE:
0.00
B
/
s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
14772
be
/
4
root
3.31
M
/
s
0.00
B
/
s
0.00
%
61.99
%
dd
if
=
/
de~lag
=
direct
1
be
/
4
root
0.00
B
/
s
0.00
B
/
s
0.00
%
0.00
%
systemd
-
~rialize
24
2
be
/
4
root
0.00
B
/
s
0.00
B
/
s
0.00
%
0.00
%
[kthreadd]
...
pidstat 和 iotop 也有不足之处,它们无法具体到某个硬盘设备,如果系统中有很多硬盘设备,都在忙,而我们只想看某一个特定的硬盘的I
/
O来自哪些进程,这两个命令就帮不上忙了。怎么办呢?可以用上万能工具SystemTap。比如:我们希望找出访问
/
dev
/
sdb的进程,可以用下列脚本,它的原理是对submit_bio下探针:
#! /usr/bin/env stap
global
device_of_interest
probe begin {
device_of_interest
=
$
1
printf (
"device of interest: 0x%x\n"
, device_of_interest)
}
probe kernel.function(
"submit_bio"
)
{
dev
=
$bio
-
>bi_bdev
-
>bd_dev
if
(dev
=
=
device_of_interest)
printf (
"[%s](%d) dev:0x%x rw:%d size:%d\n"
,
execname(), pid(), dev, $rw, $bio
-
>bi_size)
}
这个脚本需要在命令行参数中指定需要监控的硬盘设备号,得到这个设备号的方法如下:
# ll /dev/sdb
brw
-
rw
-
-
-
-
.
1
root disk
8
,
16
Oct
24
15
:
52
/
dev
/
sdb
Major number(
12
-
bit):
8
i.e.
0x8
Minor number(
20
-
bit):
16
i.e.
0x00010
合在一起得到设备号:
0x800010
执行脚本,我们看到:
# ./dev_task_io.stp 0x800010
device of interest:
0x800010
[dd](
31202
) dev:
0x800010
rw:
0
size:
512
[dd](
31202
) dev:
0x800010
rw:
0
size:
512
[dd](
31202
) dev:
0x800010
rw:
0
size:
512
[dd](
31202
) dev:
0x800010
rw:
0
size:
512
结果很令人满意,我们看到是进程号为
31202
的dd命令在对
/
dev
/
sdb进行读操作
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
进程类的信息查看
【涉及工具】
top 综合,偏CPU和memory
dstat 综合, 偏磁盘
pidstat
iostat 磁盘io 全局
iotop 磁盘io 精确到进程
iftop 网络,事实刷新
ss 取代netstat 并且速度更快
【查看cpu状态
-
设计涉及指标】
1
cpu使用率: 用户 系统
2
cpu累计使用时长
3
中断 上下文切换等(使用不是很多)
CPU查看工具 top dstat
top
选项
-
bn1
-
c 查看全命令
top
-
bn1c 一次记录就结束并打印command的全命令
指令
1
完整的列出所有的cpu核心数
P 根据CPU高低排序
M 根据内存高低排序
T 根据运行时间排序
B 行的高亮显示
x 列的高亮显示
shift
+
<或者 > 改变高亮的排序列
h 帮助信息
dstat(python脚本)
dstat
-
lcm
-
-
top
-
cpu
【查看memory状态
-
设计涉及指标】
关注点:
是否使用交换内存
每个进程消耗了多少内存空间
top
free
dstat lcmd
-
-
top
-
mem
【查看磁盘状态
-
设计涉及指标】
提示: 磁盘的性能瓶颈是比较难以排除出来的,不想cpu和内存那样比较明显的看的出来。
关注指标
1
读写量
/
s dstat iotop pidstat 精确到进程
2
每次读写的延迟时间 iostat(全局)
看读写量 iostat
-
x
1
看延迟效果 一般使用dstat(单位比较人性 整理过)
查看那个进程使用io最高 iotop
Total DISK READ:
7.02
M
/
s | Total DISK WRITE:
3.12
M
/
s
iostat中的几个参考值:
svctm < await(同样等待的请求时间被重复计算)。如果svctm比较接近awati 说明IO几乎没有等待时间。 如果await远远大于svctm,说明IO队列太长。
await: 平均每次设备IO操作等待的时间(毫秒)。即 delta(ruse
+
wuse)
/
delta(rio
+
wio)
svcm:平均每次设备IO操作服务的时间(毫秒) 会将await计算在内
%
util 一秒中有百分之多少的时间用于IO操作或者说一秒中有多少时间IO队列是非空的。
|
新增:
查看全部内存都有谁在占用:
dstat -g -l -m -s --top-mem
显示一些关于CPU资源损耗的数据:
dstat -c -y -l --proc-count --top-cpu
如何输出一个csv文件
想输出一个csv格式的文件用于以后,可以通过下面的命令:
# dstat –output /tmp/sampleoutput.csv -cdn
第一步:
$
top
第二步:
按大写的O
第三步:
输入小写字母p
第四步:
回车
针对特定进程统计(-p)
pidstat -r -p 1 1
pidstat -u 1
pidstat -r 1
pidstat -d 1
iostat



具体某个磁盘的所有分区的IO情况


本文转自 liqius 51CTO博客,原文链接:http://blog.51cto.com/szgb17/1710428,如需转载请自行联系原作者