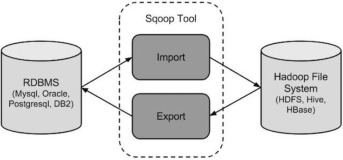
一、概述:
Sqoop是一款开源的工具,主要用于在Hadoop(如Hive、HDFS)与传统的数据库(mysql、Oracle ...)间进行数据的传递,可以将一个关系型数据库(如 MySQL ,Oracle...)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。其实质就是将导入导出命令转换成MapReduce程序来实现。
二、安装和配置
1、修改配置文件sqoop-env.sh:
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoop/app/hadoop-2.4.1
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoop/app/hadoop-2.4.1
#set the path to where bin/hbase is available
export HBASE_HOME=/home/hadoop/app/hbase-0.96.2-hadoop2
#Set the path to where bin/hive is available
export HIVE_HOME=/home/hadoop/app/hive-0.12.0-bin
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/home/hadoop/app/zookeeper-3.4.5/conf
2、将sqoop添加到环境变量。
3、将数据库连接驱动拷贝到$SQOOP_HOME/lib里。
三、导入导出:
1、数据库中的数据导入到HDFS上:
(1)、指定导入的字段:
sqoop import
--connect jdbc:mysql://192.168.1.10:3306/itcast
--username root --password 123
--table trade_detail
--columns 'id, account, income, expenses'
(2)、指定输出路径、指定数据分隔符:
sqoop import
--connect jdbc:mysql://192.168.1.10:3306/itcast
--username root --password 123
##要导入数据的表
--table trade_detail
##数据导入hdfs后所存放的目录
--target-dir '/sqoop/td'
##导入的数据字段之间的分隔符
--fields-terminated-by '\t'
(3)、指定Map数量 -m
sqoop import
--connect jdbc:mysql://192.168.1.10:3306/itcast
--username root --password 123
--table trade_detail
--target-dir '/sqoop/td1'
--fields-terminated-by '\t'
##指定做导入处理时的map 任务数
-m 2
(4)、增加where条件, 注意:条件必须用引号引起来
sqoop import
--connect jdbc:mysql://192.168.1.10:3306/itcast
--username root --password 123
--table trade_detail
--where 'id>3'
--target-dir '/sqoop/td2'
(5)、增加query语句(使用 \ 将语句换行)
sqoop import
--connect jdbc:mysql://192.168.1.10:3306/itcast
--username root --password 123
--query 'SELECT * FROM trade_detail where id > 2 AND $CONDITIONS'
--split-by trade_detail.id
--target-dir '/sqoop/td3'
注意:如果使用--query这个命令的时候,需要注意的是where后面的参数,AND $CONDITIONS这个参数必须加上
而且存在单引号与双引号的区别,如果--query后面使用的是双引号,那么需要在$CONDITIONS前加上\即\$CONDITIONS
如果设置map数量为1个时即-m 1,不用加上--split-by ${tablename.column},否则需要加上
2、将HDFS上的文件数据导出到数据库的表里面去:
sqoop export
--connect jdbc:mysql://192.168.8.120:3306/itcast
--username root --password 123
##你要导出的数据所在的目录
--export-dir '/td3'
##你要导往的目标关系表
--table td_bak
-m 1
##你要导出的文件的字段分隔符
--fields-termianted-by '\t'
四、用python导入导出表:
import os
from_table="rpt_daily"
to_table="rpt_daily"
sqoop1="sqoop import --connect jdbc:mysql://172.30.200.219/bi_warehouse --username root " \
"--password artisan --table "+from_table+" --fields-terminated-by '\\001' --target-dir /db/as_main/modifier/lzf/"+from_table+" --delete-target-dir --num-mappers 1 "
os.system(sqoop1)
sqoop2="sqoop export --connect \"jdbc:mysql://192.168.1.4/bi_warehouse?useUnicode=true&characterEncoding=utf-8\" --username root --password root --table "+to_table+" " \
"--export-dir /db/as_main/modifier/lzf/"+to_table+"/part-m-00000 --input-fields-terminated-by '\\001'"
os.system(sqoop2)
执行有2种方法:
方法1、在linux行,执行python ,进入python,然后将上面内容粘贴后回车即可
方法2、在linux行,执行python test2.py,即python调用文件(test2.py为上述内容保存的文件名称)