【优化】COUNT(1)、COUNT(*)、COUNT(常量)、COUNT(主键)、COUNT(ROWID)、COUNT(非空列)、COUNT(允许为空列)、COUNT(DISTINCT 列名)
1.1 BLOG文档结构图

1.2 前言部分
1.2.1 导读和注意事项
各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,~O(∩_∩)O~:
① COUNT(1)和COUNT(*)的区别(重点)
② 10046和10053的使用
③ “SELECT COUNT(列)”和“SELECT 列”在选择索引方面的区别
④ COUNT计数的优化
Tips:
本文适合于Oracle初中级人员阅读,Oracle大师请略过本文。
本文若有错误或不完善的地方请大家多多指正,您的批评指正是我写作的最大动力。
1.2.2 本文简介
看了很多有关COUNT(1)和COUNT(*)的区别和效率,众说纷纭。最终还是决定自己动手实验一番。
第二章 实验部分
2.1 实验环境介绍
| 项目 |
source db |
| db 类型 |
RAC |
| db version |
11.2.0.3.0 |
| db 存储 |
ASM |
| OS版本及kernel版本 |
RHEL 6.5 |
2.2 实验目标
弄清楚COUNT(1)、COUNT(*)、COUNT(常量)、COUNT(主键)、COUNT(ROWID)、COUNT(非空列)、COUNT(允许为空列)、COUNT(DISTINCT 列名)之间的区别,以及它们之间的效率问题。
2.3 实验过程
2.3.1 实验脚本
| --创建1W行的表 DROP TABLE T_COUNT_LHR; CREATE TABLE T_COUNT_LHR AS SELECT OBJECT_ID, OBJECT_NAME, OWNER, DATA_OBJECT_ID, OBJECT_TYPE, LAST_DDL_TIME FROM DBA_OBJECTS D WHERE D.OBJECT_ID IS NOT NULL AND D.OBJECT_NAME IS NOT NULL AND ROWNUM <= 10000;
--更新空值, UPDATE T_COUNT_LHR t SET t.object_type='' WHERE Rownum<=5; UPDATE T_COUNT_LHR t SET t.LAST_DDL_TIME=T.LAST_DDL_TIME+ROWNUM; UPDATE T_COUNT_LHR t SET t.LAST_DDL_TIME='' WHERE Rownum<=1; COMMIT;
--添加主键、非空约束、唯一索引、普通索引 ALTER TABLE T_COUNT_LHR ADD CONSTRAINT PK_OBJECT_ID PRIMARY KEY(OBJECT_ID); ALTER TABLE T_COUNT_LHR MODIFY OBJECT_NAME NOT NULL; CREATE UNIQUE INDEX IDX_LDT ON T_COUNT_LHR(LAST_DDL_TIME); CREATE INDEX IDX_DATA_OBJECT_ID ON T_COUNT_LHR(DATA_OBJECT_ID); CREATE INDEX IDX_DATA_OWNER ON T_COUNT_LHR(OWNER); ALTER TABLE T_COUNT_LHR MODIFY OWNER NOT NULL;
--收集统计信息 EXEC dbms_stats.gather_table_stats(USER,'T_COUNT_LHR'); SELECT d.COLUMN_NAME,d.DATA_TYPE,d.NUM_NULLS,d.NUM_DISTINCT,d.LAST_ANALYZED FROM cols d WHERE d.TABLE_NAME='T_COUNT_LHR';
|

表的信息如下所示:
| 列名 |
是否主键 |
是否允许为空 |
是否有索引 |
数据类型 |
空值的行数 |
不同值的行数 |
总行数 |
| OBJECT_ID |
Y |
N |
唯一索引 |
NUMBER |
0 |
10000 |
10000 |
| OBJECT_NAME |
|
N |
无 |
VARCHAR2 |
0 |
8112 |
10000 |
| OWNER |
|
N |
普通索引(IDX_OWNER) |
VARCHAR2 |
0 |
5 |
10000 |
| DATA_OBJECT_ID |
|
Y |
普通索引(IDX_DATA_OBJECT_ID) |
NUMBER |
7645 |
2318 |
10000 |
| OBJECT_TYPE |
|
Y |
无 |
VARCHAR2 |
5 |
20 |
10000 |
| LAST_DDL_TIME |
|
Y |
唯一索引(IDX_LDT) |
DATE |
1 |
9999 |
10000 |
需要统计如下几种情况:
| SELECT COUNT(1) FROM T_COUNT_LHR;--走索引 SELECT COUNT(*) FROM T_COUNT_LHR;--走索引 SELECT COUNT(ROWID) FROM T_COUNT_LHR; --走索引 SELECT COUNT(OBJECT_ID) FROM T_COUNT_LHR; --走索引 SELECT COUNT(OBJECT_NAME) FROM T_COUNT_LHR;--走索引 SELECT COUNT(OWNER) FROM T_COUNT_LHR D;--走索引 SELECT COUNT(D.DATA_OBJECT_ID) FROM T_COUNT_LHR D; --走索引 SELECT COUNT(D.LAST_DDL_TIME) FROM T_COUNT_LHR D;--走索引 SELECT COUNT(D.LAST_DDL_TIME) FROM T_COUNT_LHR D WHERE D.LAST_DDL_TIME IS NOT NULL;--走索引 SELECT D.LAST_DDL_TIME FROM T_COUNT_LHR D; --不走索引 SELECT D.LAST_DDL_TIME FROM T_COUNT_LHR D WHERE D.LAST_DDL_TIME IS NOT NULL;--走索引 SELECT COUNT(DISTINCT DATA_OBJECT_ID) FROM T_COUNT_LHR D;--不走索引 SELECT COUNT(DISTINCT OWNER) FROM T_COUNT_LHR D;--走索引 SELECT COUNT(DISTINCT DATA_OBJECT_ID) FROM T_COUNT_LHR D WHERE DATA_OBJECT_ID IS NOT NULL ;--走索引
|
2.4 实验结论
COUNT()函数是Oracle中的聚合函数,用于统计结果集的行数。其语法形式如下所示:

| COUNT({ * | [ DISTINCT | ALL ] expr }) [ OVER (analytic_clause) ] |
COUNT returns the number of rows returned by the query. You can use it as an aggregate or analytic function.
If you specify DISTINCT, then you can specify only the query_partition_clause of the analytic_clause. The order_by_clause and windowing_clause are not allowed.
If you specify expr, then COUNT returns the number of rows where expr is not null. You can count either all rows, or only distinct values of expr.
If you specify the asterisk (*), then this function returns all rows, including duplicates and nulls. COUNT never returns null.
我们把COUNT的使用情况分为以下3类:
① COUNT(1)、COUNT(*)、COUNT(常量)、COUNT(主键)、COUNT(ROWID)、COUNT(非空列)
② COUNT(允许为空列)
③ COUNT(DISTINCT 列名)
下面分别从查询结果和效率方面做个比较:
(一)结果区别
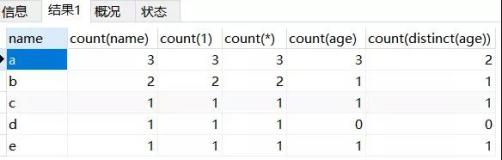
① COUNT(1)、COUNT(*)、COUNT(ROWID)、COUNT(常量)、COUNT(主键)、COUNT(非空列)这几种方式统计的行数是表中所有存在的行的总数,包括值为NULL的行和非空行。所以,这几种方式的执行结果相同。这里的常量可以为数字或字符串,例如,COUNT(2)、COUNT(333)、COUNT('x')、COUNT('xiaomaimiao')。需要注意的是:这里的COUNT(1)中的“1”并不表示表中的第一列,它其实是一个表达式,可以换成任意数字或字符或表达式。
② COUNT(允许为空列) 这种方式统计的行数不会包括字段值为NULL的行。
③ COUNT(DISTINCT 列名) 得到的结果是除去值为NULL和重复数据后的结果。
④ “SELECT COUNT(''),COUNT(NULL) FROM T_COUNT_LHR;”返回0行。
(二)效率、索引
① 如果存在主键或非空列上的索引,那么COUNT(1)、COUNT(*)、COUNT(ROWID)、COUNT(常量)、COUNT(主键)、COUNT(非空列)会首先选择主键上的索引快速全扫描(INDEX FAST FULL SCAN)。若主键不存在则会选择非空列上的索引。若非空列上没有索引则肯定走全表扫描(TABLE ACCESS FULL)。其中,COUNT(ROWID)在走索引的时候比其它几种方式要慢。通过10053事件可以看到这几种方式除了COUNT(ROWID)之外,其它最终都会转换成COUNT(*)的方式来执行。
② 对于COUNT(COL1)来说,只要列字段上有索引则会选择索引快速全扫描(INDEX FAST FULL SCAN)。而对于“SELECT COL1”来说,除非列上有NOT NULL约束,否则执行计划会选择全表扫描。
③ COUNT(DISTINCT 列名) 若列上有索引,且有非空约束或在WHERE子句中使用IS NOT NULL,则会选择索引快速全扫描。其余情况选择全表扫描。