1、果断先上结论
1.如果想增加map个数,则设置mapred.map.tasks 为一个较大的值。
2.如果想减小map个数,则设置mapred.min.split.size 为一个较大的值。
3.如果输入中有很多小文件,依然想减少map个数,则需要将小文件merger为大文件,然后使用准则2。
2、原理与分析过程
看了很多博客,感觉没有一个说的很清楚,所以我来整理一下。
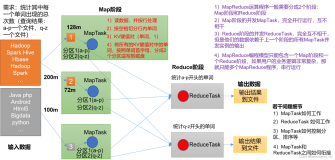
先看一下这个图

输入分片(Input Split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
Hadoop 2.x默认的block大小是128MB,Hadoop 1.x默认的block大小是64MB,可以在hdfs-site.xml中设置dfs.block.size,注意单位是byte。
分片大小范围可以在mapred-site.xml中设置,mapred.min.split.size mapred.max.split.size,minSplitSize大小默认为1B,maxSplitSize大小默认为Long.MAX_VALUE = 9223372036854775807
那么分片到底是多大呢?
minSize=max{minSplitSize,mapred.min.split.size}
maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
我们再来看一下源码

所以在我们没有设置分片的范围的时候,分片大小是由block块大小决定的,和它的大小一样。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。我又发现了另一个问题,第三个block块里存的文件大小只有2MB,而它的block块大小是128MB,那它实际占用Linux file system的多大空间?
答案是实际的文件大小,而非一个块的大小。
有大神已经验证这个答案了:http://blog.csdn.net/samhacker/article/details/23089157
1、往hdfs里面添加新文件前,hadoop在linux上面所占的空间为 464 MB:

2、往hdfs里面添加大小为2673375 byte(大概2.5 MB)的文件:
2673375 derby.jar
3、此时,hadoop在linux上面所占的空间为 467 MB——增加了一个实际文件大小(2.5 MB)的空间,而非一个block size(128 MB):

4、使用hadoop dfs -stat查看文件信息:

这里就很清楚地反映出: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
5、通过NameNode的web console来查看文件信息:

结果是一样的: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
6、不过使用‘hadoop fsck’查看文件信息,看出了一些不一样的内容—— ‘1(avg.block size 2673375 B)’:

值得注意的是,结果中有一个 ‘1(avg.block size 2673375 B)’的字样。这里的 'block size' 并不是指平常说的文件块大小(Block Size)—— 后者是一个元数据的概念,相反它反映的是文件的实际大小(file size)。以下是Hadoop Community的专家给我的回复:
“The fsck is showing you an "average blocksize", not the block size metadata attribute of the file like stat shows. In this specific case, the average is just the length of your file, which is lesser than one whole block.”
最后一个问题是: 如果hdfs占用Linux file system的磁盘空间按实际文件大小算,那么这个”块大小“有必要存在吗?
其实块大小还是必要的,一个显而易见的作用就是当文件通过append操作不断增长的过程中,可以通过来block size决定何时split文件。以下是Hadoop Community的专家给我的回复:
“The block size is a meta attribute. If you append tothe file later, it still needs to know when to split further - so it keeps that value as a mere metadata it can use to advise itself on write boundaries.”
补充:我还查到这样一段话
原文地址:http://blog.csdn.net/lylcore/article/details/9136555
一个split的大小是由goalSize, minSize, blockSize这三个值决定的。computeSplitSize的逻辑是,先从goalSize和blockSize两个值中选出最小的那个(比如一般不设置map数,这时blockSize为当前文件的块size,而goalSize是文件大小除以用户设置的map数得到的,如果没设置的话,默认是1)。
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map的个数,还取决于其他的因素。
为了方便介绍,先来看几个名词:
block_size : hdfs的文件块大小,默认为64M,可以通过参数dfs.block.size设置
total_size : 输入文件整体的大小
input_file_num : 输入文件的个数
(1)默认map个数
如果不进行任何设置,默认的map个数是和blcok_size相关的。
default_num = total_size / block_size;
(2)期望大小
可以通过参数mapred.map.tasks来设置程序员期望的map个数,但是这个个数只有在大于default_num的时候,才会生效。
goal_num = mapred.map.tasks;
(3)设置处理的文件大小
可以通过mapred.min.split.size 设置每个task处理的文件大小,但是这个大小只有在大于block_size的时候才会生效。
split_size = max(mapred.min.split.size, block_size);
split_num = total_size / split_size;
(4)计算的map个数
compute_map_num = min(split_num, max(default_num, goal_num))
除了这些配置以外,mapreduce还要遵循一些原则。 mapreduce的每一个map处理的数据是不能跨越文件的,也就是说min_map_num >= input_file_num。 所以,最终的map个数应该为:
final_map_num = max(compute_map_num, input_file_num)
经过以上的分析,在设置map个数的时候,可以简单的总结为以下几点:
(1)如果想增加map个数,则设置mapred.map.tasks 为一个较大的值。
(2)如果想减小map个数,则设置mapred.min.split.size 为一个较大的值。
(3)如果输入中有很多小文件,依然想减少map个数,则需要将小文件merger为大文件,然后使用准则2。
参考资料:
http://blog.csdn.net/dr_guo/article/details/51150278