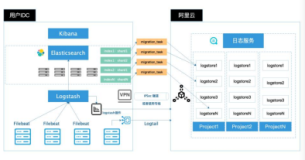
由于公司的elasticsearch集群只是用了两台服务器。只要一台服务器数据丢失elasticsearch将丢失一半数据。所以数据的备份恢复就相当重要。elasticsearch 快照和恢复模块可以创建单个索引或者整个集群的快照到远程的仓库实现数据的备份及恢复。
下面以备份恢复.kibana索引为例
数据备份及恢复
1、修改elasticsearch配置文件
vim elasticsearch.yml
添加 path.repo: ["/mnt/bak"]
#设置仓库路径
备注如果你有多台ealsticsearch服务器作为集群可以先关闭分片服务器只在master主节点服务器上更改。或者在创建库的之前设置创建共享文件夹
2、创建仓库
|
1
2
3
4
5
6
7
8
9
|
curl -XPUT http:
//192
.168.10.49:9200
/_snapshot/my_backup
-d '
{
"type"
:
"fs"
,
"settings"
: {
"location"
:
"/mnt/bak"
,
"compress"
:
true
}
}
'
|
运行上面的命令后返回结果{"acknowledged":true}
说明仓库创建成功。
compress 是否压缩
max_snapshot_bytes_per_sec 制作快照的速度默认20mb/s
max_restore_bytes_per_sec 快照恢复的速度默认20mb/s
查看仓库
|
1
2
|
curl -GET http:
//192
.168.10.49:9200
/_snapshot
{
"my_backup"
:{
"type"
:
"fs"
,
"settings"
:{
"compress"
:
"true"
,
"location"
:
"/mnt/bak"
}}}
|
3、备份数据
|
1
|
curl -XPUT http:
//192
.168.10.49:9200
/_snapshot/my_backup/snapshot_20161207
|
执行上面的命令会快照ealsticsearch上所有的索引。
如果需要快照指定的索引
|
1
2
3
4
5
|
curl -XPUT http:
//192
.168.10.49:9200
/_snapshot/my_backup/snapshot_20161207
-d '
{
"indices"
:
".kibana"
}
'
|
如果成功返回结果显示{"accepted":true}
4、查看备份
|
1
|
curl -XGET http:
//192
.168.10.49:9200
/_snapshot/my_backup/snapshot_20161207
|
此命令是查看快照的情况返回的数据会比较多
{"snapshots":[{"snapshot":"snapshot_20161207","version_id":2030599,"version":"2.3.5","indices":["es-index-
.........中间N行数据..........
{"total":71,"failed":0,"successful":37}}]}
也可以使用下面的命令查看快照的状态
|
1
2
|
curl -XGET http:
//192
.168.10.49:9200
/_snapshot/my_backup/snapshot_20161207/_status
{
"snapshots"
:[{
"snapshot"
:
"snapshot_20161207"
,
"repository"
:
"my_backup"
,
"state"
:
"SUCCESS"
,
"shards_stats"
:{
"initializing"
:0,
"started"
:0,
"finalizing"
:0,
"done"
:1,
"failed"
:0,
"total"
:1},
"stats"
:{
"number_of_files"
:14,
"processed_files"
:14,
"total_size_in_bytes"
:143273,
"processed_size_in_bytes"
:143273,
"start_time_in_millis"
:1481060674078,
"time_in_millis"
:50},
"indices"
:{
".kibana"
:{
"shards_stats"
:{
"initializing"
:0,
"started"
:0,
"finalizing"
:0,
"done"
:1,
"failed"
:0,
"total"
:1},
"stats"
:{
"number_of_files"
:14,
"processed_files"
:14,
"total_size_in_bytes"
:143273,
"processed_size_in_bytes"
:143273,
"start_time_in_millis"
:1481060674078,
"time_in_millis"
:50},
"shards"
:{
"0"
:{
"stage"
:
"DONE"
,
"stats"
:{
"number_of_files"
:14,
"processed_files"
:14,
"total_size_in_bytes"
:143273,
"processed_size_in_bytes"
:143273,
"start_time_in_millis"
:1481060674078,
"time_in_millis"
:50}}}}}}]}
|
5、取消备份
|
1
|
curl -XDELETE http:
//192
.168.10.49:9200
/_snapshot/my_backup/snapshot_20161207
|
6、恢复备份
|
1
|
curl -XPOST http:
//192
.168.10.49:9200
/_snapshot/my_backup/snapshot_20160812/_restore
|
如果你的是集群而且在创建仓库的时候没有配置共享文件夹那会报下面的错误
|
1
|
{
"error"
:
"RepositoryException[[my_backup] failed to create repository]; nested: CreationException[Guice creation errors:\n\n1) Error injecting constructor, org.elasticsearch.repositories.RepositoryException: [my_backup] location [/mnt/bak] doesn't match any of the locations specified by path.repo because this setting is empty\n at org.elasticsearch.repositories.fs.FsRepository.<init>(Unknown Source)\n while locating org.elasticsearch.repositories.fs.FsRepository\n while locating org.elasticsearch.repositories.Repository\n\n1 error]; nested: RepositoryException[[my_backup] location [/mnt/bak] doesn't match any of the locations specified by path.repo because this setting is empty]; "
,
"status"
:500}
|
解决方法关闭支点服务器elasticsearch服务重新执行即可成功。
如果已经存在.kibana索引可以先关闭掉。
成功恢复数据后只有主节点服务器存在.kibana索引。我们希望所有的节点服务器都存在此索引时执行下面的命令
|
1
2
3
4
5
6
|
curl -XPUT
'http://192.168.10.49:9200/.kibanna/_settings'
-d '
{
"index"
: {
"number_of_replicas"
: 1
}
}'
|

本文转自 irow10 51CTO博客,原文链接:http://blog.51cto.com/irow10/1880365,如需转载请自行联系原作者