pt-archiver
- 简介
把MySQL表中的部分行存档到另外的表或者文件中 -
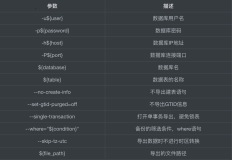
概要
1.用法:pt-archiver [可选项] --source DSN --where WHERE
2.详细介绍
本着在OLTP环境中可以尽量少影响查询性能的目的,我将这个工具设计可以在低性能影响,正向性
的情况下将数据小批量小批量的将旧数据取出并归档。
本工具依靠插件式的原理实现了可扩展性,各位可以对此工具进行增加更本地化的功能,例如扩展
更加复杂的规则,或者边抽取数据边创建数据仓库。
技巧:找到第一行,然后根据某些索引向后查找更多行的数据,包含在命令最后面的where段中的条件
应当可以依靠索引查找所满足的数据,而不是靠扫描整个表。
可以在--source声明中指定 i参数(index),这对于想要根据索引获取数据行的操作非常关键。
使用--dry-run声明此次工具执行后只生成对应的SQL语句,而不真正操作数据,接着对生成的
SQL语句进行explain操作,检查其索引使用情况。更进一步可以检查语句执行过程中的句柄操作类型
确保语句没有进行全表扫描(句柄操作类型:read,read_rnd_next,delete等等底层原子性操作) - 参数
注意:
至少要指定--dest,--file,或者--purge参数--ignore与--replace互斥--txn-size与--commit-each互斥--low-priority-insert与--delay-insert互斥--share-lock与--for-update互斥--analyze与--optimize互斥--no-ascend与--no-delete互斥
如果在COPY模式下,--dest的参数值默认继承--source参数的值--analyze
在传输完数据后,运行ANALYZE TABLE进行优化表的索引信息。
--analyze=d 优化dest表索引信息
--analyze=s 优化source表索引信息
--analyze=ds 优化源表与目标表的索引信息--no-ascend
不使用递增索引优化特性
默认情况下,pt-archiver工具使用递增索引特性优化批量重复的select操作,即:下一批数据归档时将
从上一批归档结束时索引的位置开始,不需要再从头扫描到自己需要归档的位置,但在多列复合索引
的情况下可能效果降低--ascend-first
仅使用复合索引的第一列进行递增优化,与上面的参数有关,在复合索引或者where条件复杂的情况
下,仅使用的复合索引的第一列进行递增优化,比上面的完全不使用递增索引优化特性方法更好--ask-pass
采用交互的方式输入密码,防止身后的开发与测试窥屏--buffer
禁用自动刷新缓存到--file参数指定的的文件,将结果集存在操作系统缓存中,提交的时候刷新缓存。
(原本是每行都会刷新一次到文件)。但使用操作系统缓存是个不可靠因素,可能会导致意外丢失
数据。
当--buffer在5-15%的左右时,可以提升本工具的性能--txn-size
指定一个事务处理多少行数据,默认1。设成0,不使用批量特性,自动提交事务。
当工具处理完设定行数的数据时,同时对源库和目标库进行事务提交,然后刷新到--file参数指定
的文件中这个参数对源库性能的影响比较大,对繁忙的线上OLTP服务器进行归档时,要兼顾数据
抽取性能和事务提交性能。提高本参数值可以提高数据抽取性能,但会导致行锁范围扩大,甚至
死锁。减小本参数值可以缓解以上情况,但是过小会导致事务提交量增大,对线上业务的提交性
能有影响。
作者亲测:在PC上,设置为500时,每1K行只用了2秒的时间,但设为0,自动提交时,则每1K行
花费了将近38秒。使用非事务型引擎,推荐设成0。--commit-each
每一组数据提交一次,并自动屏蔽--txn-size参数。可以使用--limit控制总的操作的行数。
假如要存档一个特别大的表,--limit=1000加--txn-size=1000同时使用时,工具开启一个事务连
续读到了所有满足where的999行数据,但是由于工具本身并不知道究竟有多少数据满足,有可能
会一直全表扫描到最后一行然后才会提交这个事务,因此,使用--commit-each参数每一组提交
一次可以有效避免上面的窘境。--bulk-delete
批量删除,一批数据行用一个DELETE语句完成。同时也意味着--commit-each。
通常删除数据的做法是根据主键进行逐行删除,批量删除在简单WHERE条件下速度会有显著的
提高。
此选项会在收集完所有待删除的数据行前,推迟删除操作。如果有删除前的触发器将不会被触发
(before delete),多行删除前的触发器会被触发(before bulk delete)--[no]bulk-delete-limit
批量删除限制,默认开启
默认情况下,--bulk-delete参数会追加一个--limit参数,在部分情况下,可以使用--no-bulk-delete-limit忽略掉,但仍需手动加上--limit参数。此参数不建议使用--bulk-insert
采用LOAD DATA INFILE的方式(与bulk-delete和commit-each组合使用)
相比一行一行的插入,通过为每批数据创建临时文件,先行写入数据到临时文件,当一批数据获
取完毕后,再进行导入操作。
为了防止一行一行的删除数据时,但这些数据却因为在缓存文件中没有真正的归档在新的数据库
中,造成数据真空甚至不确定情况下的数据丢失,采用--bulk-insert的时候必须与bulk-deletes
成对出现,保证数据在被插入新库之前,旧库不会对这些数据进行删除。
此参数可以与--low-priority-insert,--replace,, 本文转自 angry_frog 51CTO博客,原文链接:http://blog.51cto.com/l0vesql/2048195