问题起因
近期一个客户上云,系统用的是Oracle数据库,正确的姿势当然是去O,改用MySQL再上云,但因采用的软件系统来自外购,短时间内无法做去O改造,就采用了购买ECS并在上面安装Oracle的做法,使用SharePlex for Oracle做主备同步,具体架构如下:
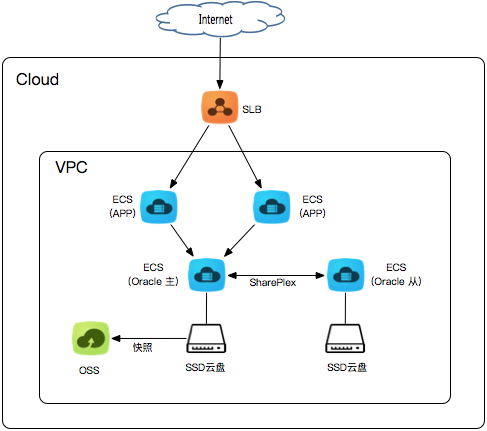
这个架构看起来有应用的负载均衡,有数据库的主备做高可用,有SSD云盘保证IO,有快照做容灾,还是挺完美嘛~但实际使用中,就发现问题多多。
问题一:ECS实例选型
该用户选择的ecs.hfg5型实例,属于“高主频型”,让我们看看这个类型实例的适用场景https://help.aliyun.com/document_detail/25378.html#localssd:“可以满足高性能前端集群、Web 服务器、批量处理、分布式分析、高性能科学和工程应用、广告服务、MMO 游戏、视频编码等场景”,有没有做数据库服务的场景?可能用户觉着选择“高主频型”后,计算能力是足够了,再配合上“SSD云盘”,那存储上的IO也不是瓶颈,岂不是Perfect?
然而在上线后,系统访问压力增大才发现,实际的数据库性能总是上不去,最后发现问题还是在于磁盘IO上:
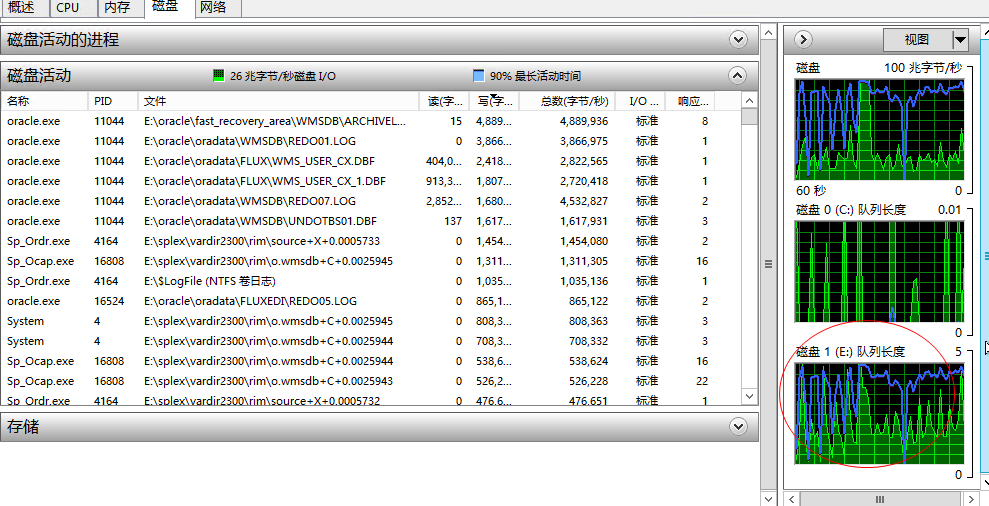
数据盘队列长度一直在5左右,随便搜搜关于磁盘队列长度的讨论,比如:
http://www.ithacks.com/2008/09/12/high-avg-disk-queue-length-and-finding-the-cause/,“As a general rule for hard disks, an Avg Disk Queue Length greater than 2 (per hard disk) for extended periods of time is considered undesirable.”,还有“Disk Queue Length is over 2 and % Disk Time is hovering at 60% or above, you may want to look into a possible I/O bottleneck.”,嗯,似乎确实有点问题哈。
既然都用了SSD云盘了,为什么还有磁盘IO瓶颈呢?经过找块存储的同学沟通后,确认IO带宽并不会是瓶颈,瓶颈是出在延迟上,既然是云盘,是会增加那么一丁点延迟的,经过测试,SSD云盘的写延迟在1ms左右,读延迟在1~2ms,这个结果其实并不差(比行业水平,比如其他云供应商还是强滴),但用在对读写延迟高度敏感的数据库服务器上,就稍显不够了。
那么既然SSD云盘都不够,是不是我们就该放弃云上自建数据库,下云得了?答案是No!其实从一开始我们就有更好的选择,那就是选择“本地SSD”型的ECS,我们来看看这个类型的ECS用在什么场景:“对应本地盘存储类型为NVMe SSD资源,高随机 IOPS 和高顺序读写吞吐、低时延。适用于 OLTP 联机事务处理、NoSQL 数据库、Hadoop 等应用场景”,看到没,这才是真正该选择用于自建数据库的ECS实例类型,前面那是方向错了(但努努力还是有救的,后面再说)。
话说阿里云还是提供过非实例型本地SSD盘(https://promotion.aliyun.com/act/aliyun/localssd.html),只不过现在下架了,这个选项就不再在考虑范围内了。
问题二:磁盘的配置
看系统性能图可以发现,用户的数据库服务器其实只有两块盘,一个是系统盘(高效云盘),另一个是数据盘(SSD云盘),数据、日志等都写在数据盘上,在高访问压力的时候,除了大量的数据写入外,也产生巨量的redo log。那么数据、日志分别写不同的磁盘,是否可以提高并行程度,从而改进写入效率呢?
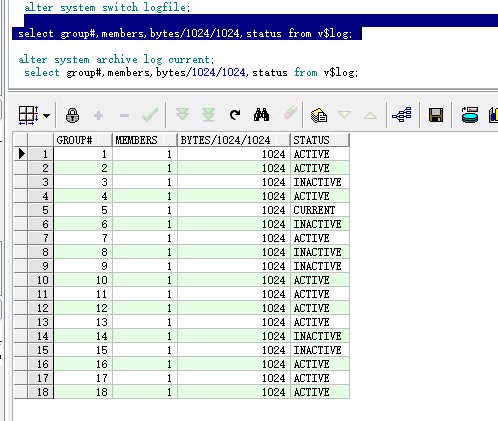
说做就做,请用户新购买个SSD云盘,把当前9组redo log全部从当前数据库盘挪到新盘,并新加9组redo log,这样18个日志组都存在新盘中:
现在系统架构变这样了:
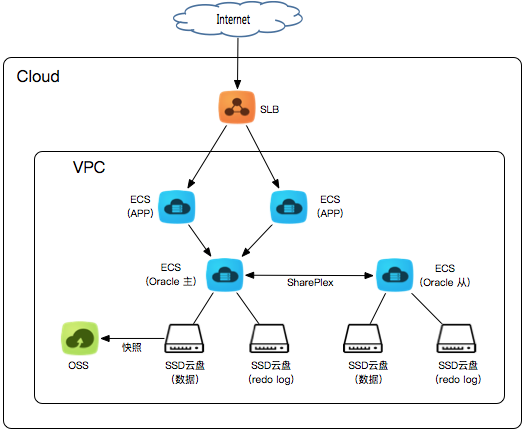
再看看系统性能情况:
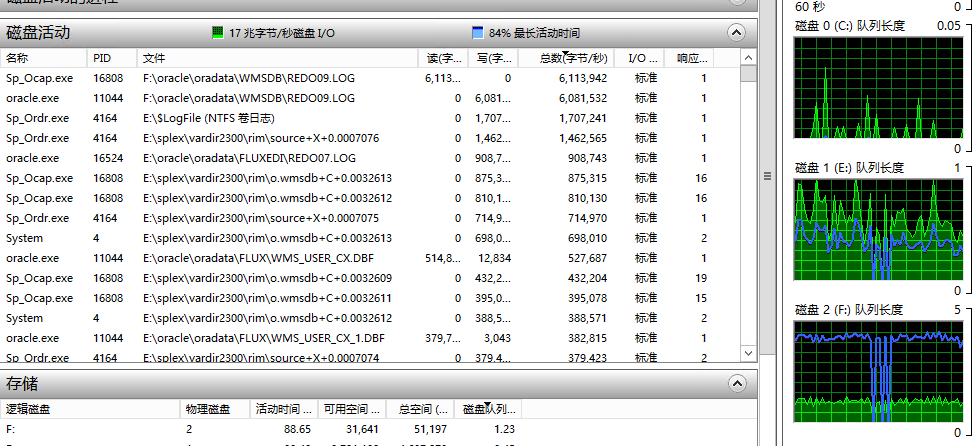
数据盘的队列长度1,已经到了合理范围内,现在压力到了日志盘(F盘),似乎有点儿矫枉过正了,两个盘又有点写入不均匀。但是anyway,数据库的IO性能大有改善,在业务顶峰的时候也妥妥的扛得住。
虽然用户系统扛得住,但咱们还是要总结经验教训的,得找正式说法不是~其实Oracle官方文档已经早早的给咱们指明这个道路啦https://docs.oracle.com/cd/B28359_01/server.111/b28310/onlineredo002.htm#ADMIN11312,“Datafiles should also be placed on different disks from redo log files to reduce contention in writing data blocks and redo records.”。当然系统还可以进一步优化,比如数据文件也分布在不同的盘上,比如数据文件和日志文件怎么分布才能取得最佳平衡点,这就是下一步目标了。
问题三:快照容灾
OK,现在性能的问题解决了,是不是就一切OK了呢?别急,还早着了,下一个问题就是用快照做数据容灾不靠谱。如果用“oracle datafile corrupted”搜一下,会发现那结果是相当的多,估计背后都是满满的眼泪~在ECS上对云盘做快照,因为是不停机状态,数据文件更容易处于一个不完全的状态,换句话说,在真正需要基于快照恢复的时候,你会发现有很大的几率告诉你因为数据文件损坏,数据库无法启动。
在云下的时候,数据文件被损坏了还是能恢复的,条件是:“A datafile can still be recovered if no backup exists for it, provided: a、all redolog files since the creation of the datafile are available;b、the control file contains the name of the damaged file (that is, the control file is current, or is a backup taken after the damaged datafile was added to the database)”,可以发现这个在云上是很难满足的,也就代表你从快照恢复数据库也是很难满足的。
那正确的容灾姿势是什么呢?见下图:
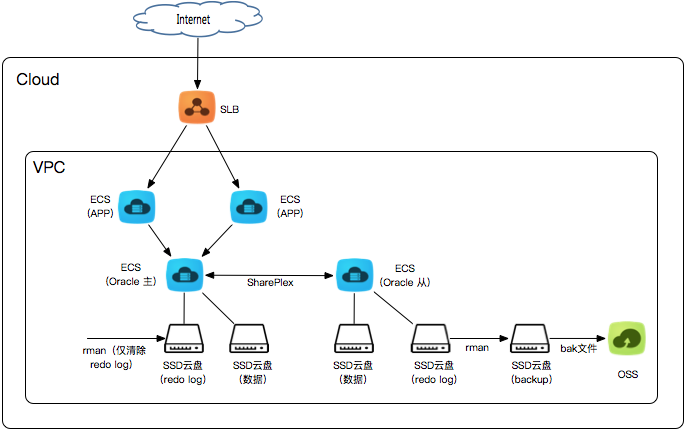
其中备份到OSS这个其实可选,毕竟云盘提供9个9的可靠性(见https://help.aliyun.com/document_detail/25382.html),OSS也不过10个9,主备实例的云盘加上备份用的云盘全挂的概率实在不高。如果希望能够进一步提高数据的可靠性(及时备份),可以在主实例上做rman数据备份,这会损失一点主实例的性能。
问题四:快照时机
上个问题提到快照容灾不靠谱,容易导致数据文件损坏,无法做灾难恢复。其实用户使用快照还有另一个有问题的地方,就是为了容灾中尽量少损失数据,设置了每3个小时做一次快照,而其中有几次会发生在业务高峰期!这就导致了在快照的时间点(因为数据量巨大,快制作快照需要的时间比较久)会因为备份争抢磁盘的IO,这会导致数据库性能的进一步恶化,这也是在实际使用中发生性能不够的一个重要的因素。正常的快照操作应该在业务低谷时候做。
问题五:数据库HA方案
现在我们回过头来看看该用户的Oracle HA方案,架构里面看起来似乎做到了HA,但实际还离得远,很简单,如果主实例出故障,那么会怎么切换?首先这没有自动切换的机制,如果半夜三更没人值班,发生故障了只能等业务出问题了,再去找运维人员,然后做手动切换。
那找到运维人员是不是就能快速恢复?No!既然是应用服务器上直连数据库服务器,那么不管使用IP还是实例名,切到备服务器都需要修改应用服务器的配置,然后重新应用,这个时间可就长了,别说做不到业务无感的自动切换,连快速恢复都算不上。
数据库HA最常见的实践是用VIP,但在阿里云里面现在是不支持VIP的使用,如果对数据库的请求走“SLB+多ECS(ECS内再自建load balancer)”来实现failover似乎性能的损失会比较大,目前看来还没能找到比较靠谱的云上自建数据库HA方案,如果哪位知道还请指点一下:)

