编译hbase-1.2.3源代码.pdf
编译hbase-1.2.3源代码.pdf
目录
8. Problems opening an editor ... does not exist 10
1. 约定
确保机器可以正常访问Internet,如能正常访问https://repo.maven.apache.org等,如果是代理方式则需要设置好eclipse和maven的网络配置。
本文环境为64位版本Windows7,jre安装目录为C:\java\jdk1.8.0_111,jdk安装目录为C:\java\jre1.8.0_111。
最好将jre安装在在jdk目录下,否则编译时会遇到“Could not find artifact jdk.tools:jdk.tools:jar”错误。将jre安装在jdk目录下的目的是使得jre的上一级存在jdk的lib目录。
2. 安装jdk
略!安装好后请设置环境变量JAVA_HOME为jdk的安装目录(不是javac所在的bin目录,而是bin的上一级目录)。
3. 安装maven
从maven官网下载安装包(本文下载的是apache-maven-3.3.9-bin.zip):
https://maven.apache.org/download.cgi
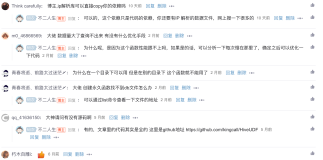
解压后,将maven的bin目录加入到环境变量PATH中,本文对应的目录为C:\Program Files\apache-maven-3.3.9\bin。并设置环境变量M2_HOME的值为maven的安装目录,对于本文M2_HOME值为C:\Program Files\apache-maven-3.3.9
然后设置eclipse使用外部的maven,进入eclipse的Preferences中按下图进行设置:
4. 网络配置
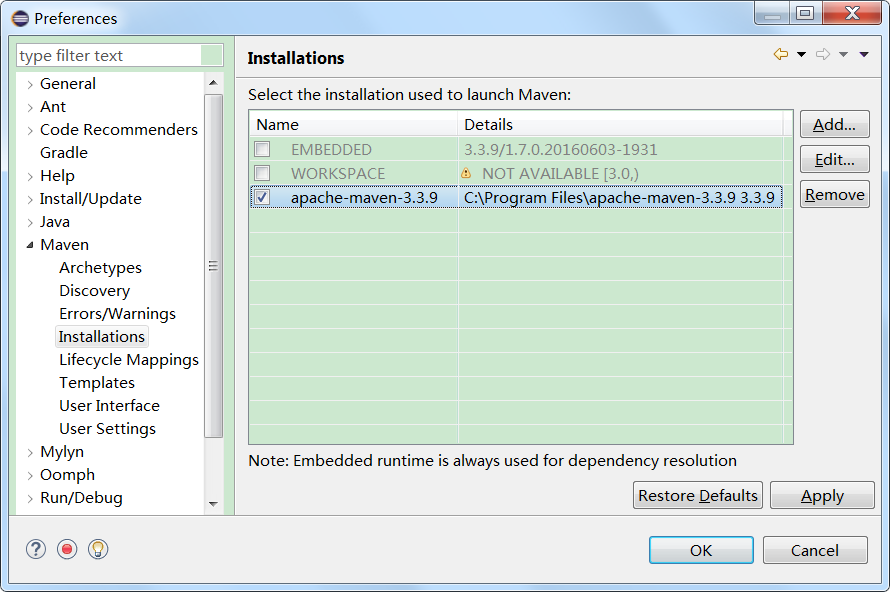
确保机器可以正常访问Internet,否则大量问题难以解决。如果是通过代理才能访问,则需要为eclipse和maven配置好代理。
4.1. eclipse
4.2. maven
编辑$HOME/.m2目录下的settings.xml,如果不存在该文件,则复制$MAVEN_HOME/conf目录下的settings.xml,然后再修改即可同。
MAVEN_HOME为maven的安装目录,$HOME/.m2为repository的默认目录,HOME为Windows用户目录,Windows7上假设用户名为mike则HOME为C:\Users\mike。
假设代理服务器的地址和端口分别为:proxy.oa.com和8080,则(不需要用户名或密码,则相应的值不设置即可):
|
http-proxy true http
proxy.oa.com 8080 local|127.0.0.1
https-proxy true https
proxy.oa.com 8080 local|127.0.0.1
|
5. 从hbase官网下载源代码包:
以下网站均提供hbase源代码包下载:
http://mirrors.hust.edu.cn/apache/hbase/
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/
http://mirror.bit.edu.cn/apache/hbase/
http://apache.fayea.com/hbase/
本文下载的是hbase-1.2.3-src.tar.gz。
6. eclipse导入hbase源代码
本文使用的eclipse版本:
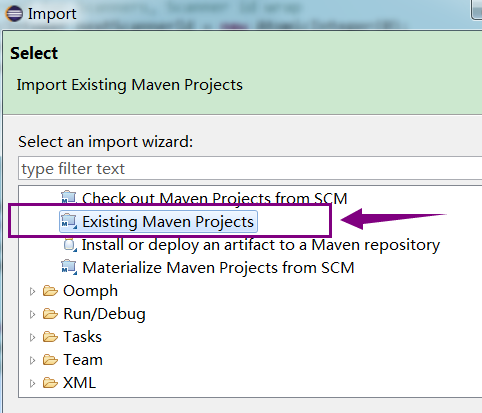
将hbase-1.2.3-src.tar.gz解压,本文将其解压到目录E:\bigdata\hbase-1.2.3-src,然后以“Existing Maven Projects”方式导入:
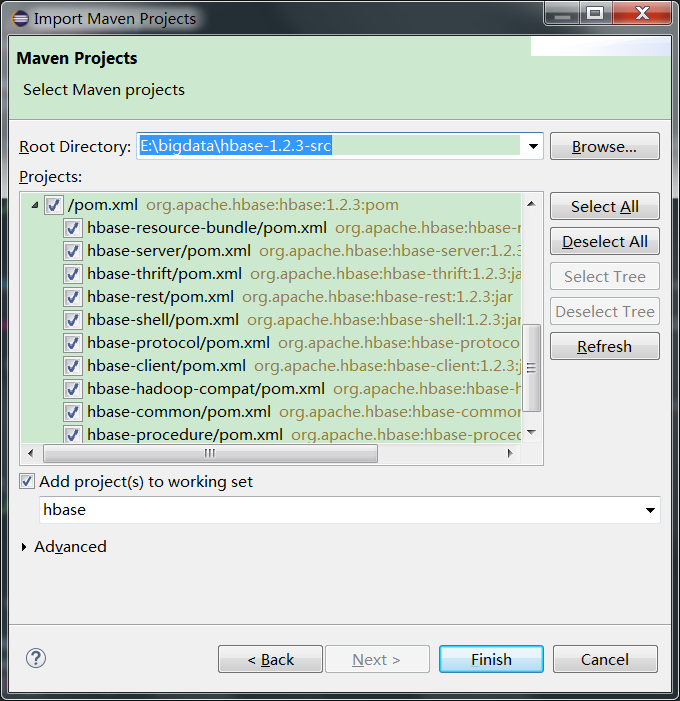
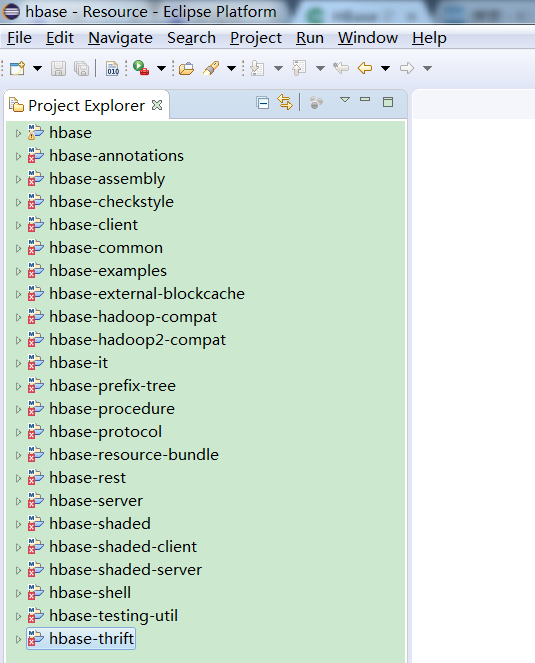
成功导入后如下图所示:
以maven编译hbase源代码,编译整个hbase容易遇到错误,比如编译hbase-common需要安装bash,hbase-thrift、但hbase-server、hbase-client等模块不依赖bash。为简单体验,先定一个小目标:编译hbase-thrift模块:
7. 编译hbase-thrift
鼠标右击hbase-thrift,按下图进入设置界面:
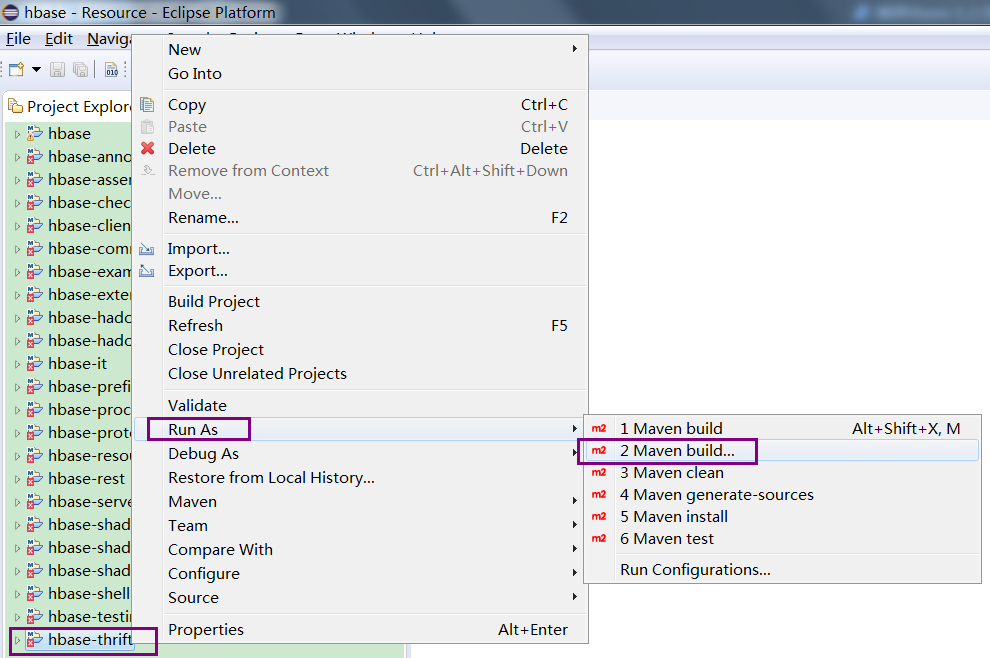
设置界面如下图所示,并设置Goals为clean install -DskipTests(注意不是clean install,需要加上-DskipTests,否则即使勾选了Skip Tests也可能无效):
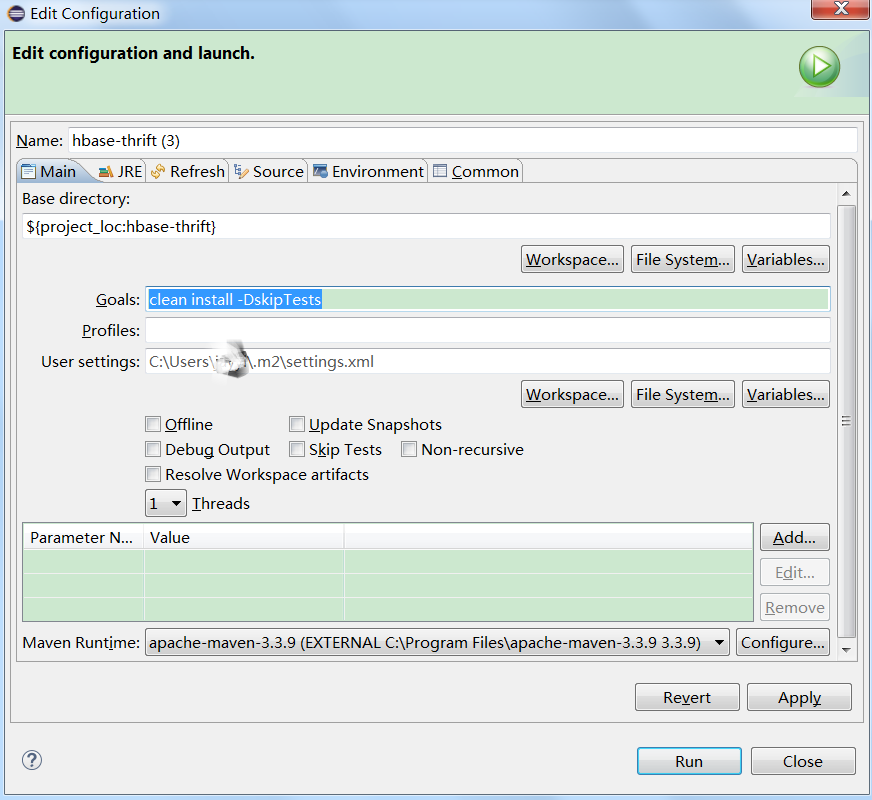
然后点击“Run”即开始编译!
编译过程中如遇到下面的错误,请确认是否存在目录C:\java\jre1.8.0_111/../lib,其用意是jre安装在jdk的目录下,也就是说lib需要为jdk的lib目录。
简单的做法是复制jdk的lib目录到C:\java目录下。
| [ERROR] Failed to execute goal on project hbase-thrift: Could not resolve dependencies for project org.apache.hbase:hbase-thrift:jar:1.2.3: Could not find artifact jdk.tools:jdk.tools:jar:1.8 at specified path C:\java\jre1.8.0_111/../lib/tools.jar -> [Help 1] |
成功后如下图所示:
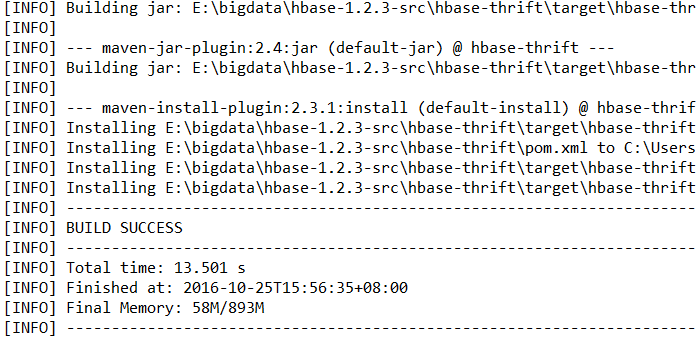
在目录E:\bigdata\hbase-1.2.3-src\hbase-thrift\target下可以看到编译生成的jar文件:
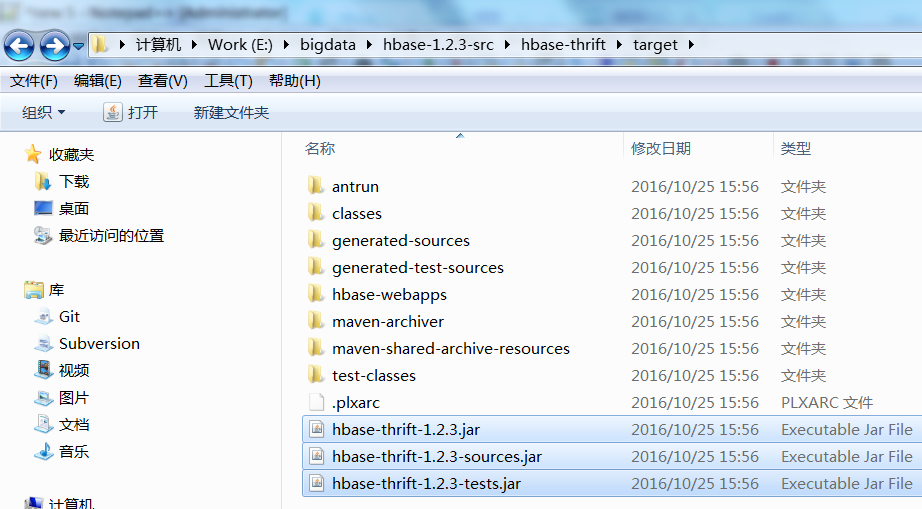
然后可以编译hbase-client,如果需要编译hadoop-common则需要安装bash先,也就是得安装cygwin(https://cygwin.com/install.html)。
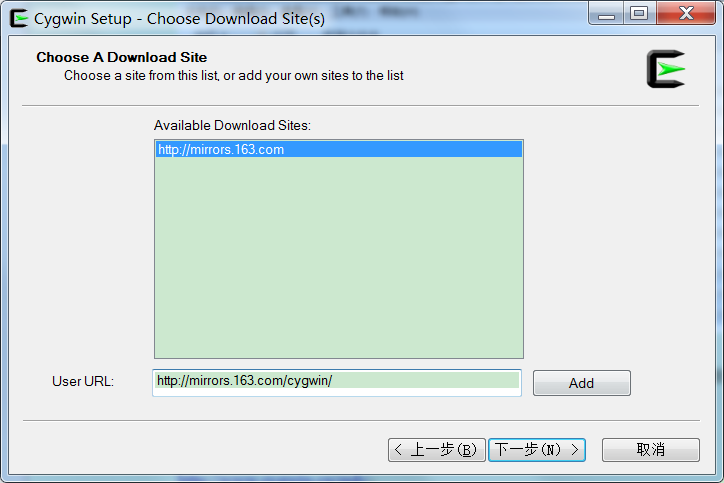
建议从国内镜像安装cgywin,会快很多,可用镜像:
http://mirrors.163.com/cygwin/
选择从互联网安装,在“User URL”处输入国内镜像网址。
安装好cygwin后,需将cgywin的bin目录加入到环境变量PATH中,并需要重启eclipse才会生效。如果未安装bash,则用同样方法编译hadoop-common时,会报如下错误:
| [ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.6:run (generate) on project hbase-common: An Ant BuildException has occured: Execute failed: java.io.IOException: Cannot run program "bash": CreateProcess error=2, 系统找不到指定的文件。 -> [Help 1] |
8. Problems opening an editor ... does not exist
在eclipse里用F3想进入某个类的某方法时,提示以下错误(Problems opening an editor Reason: [项目名] does not exist):
解决办法(目的是生成“.project”和“.classpath”两个eclipse需要的文件):
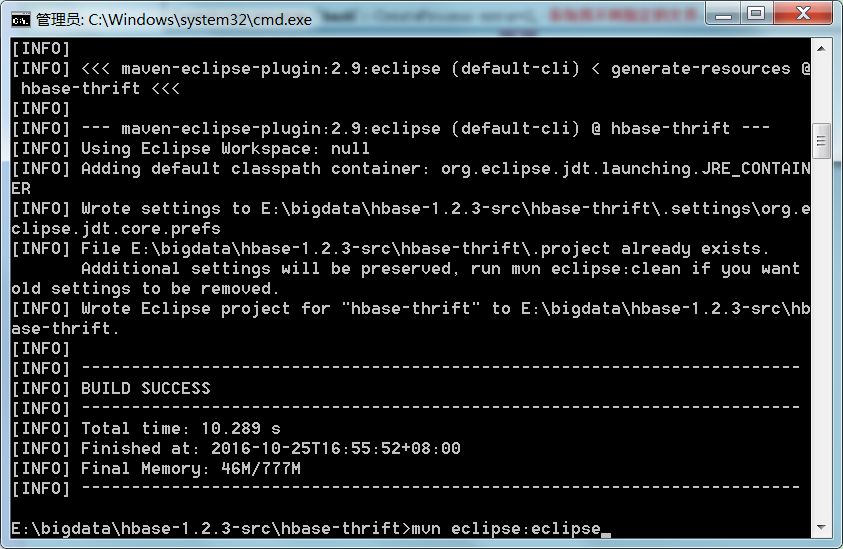
按下图所示,进入项目的根目录,以hbase的hbase-thrift为例,如hbase-thrift所在目录为E:\bigdata\hbase-1.2.3-src\hbase-thrift,注意不是E:\bigdata\hbase-1.2.3-src,然后执行:mvn eclipse:eclipse,成功后重启eclipse上述问题即解决(mvn eclipse:eclipse的作用是将maven项目转化为eclipse项目,即生成两个eclipse导入所需的配置文件,并无其他改变,也就是生成eclipse需要的.project和.classpath两个文件):
其它诸于hbase-client、hbase-common、h base-server等同样处理即可。
9. hbase-common
编译hbase-common如遇到下述问题:
| [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:2.5.1:compile (default-compile) on project hbase-common: Compilation failure: Compilation failure: [ERROR] E:\bigdata\hbase-1.2.3-src\hbase-common\target\generated-sources\java\org\apache\hadoop\hbase\package-info.java:[5,39] 错误: 非法转义符 [ERROR] E:\bigdata\hbase-1.2.3-src\hbase-common\target\generated-sources\java\org\apache\hadoop\hbase\package-info.java:[5,30] 错误: 未结束的字符串文字 [ERROR] E:\bigdata\hbase-1.2.3-src\hbase-common\target\generated-sources\java\org\apache\hadoop\hbase\package-info.java:[6,0] 错误: 需要class, interface或enum [ERROR] E:\bigdata\hbase-1.2.3-src\hbase-common\target\generated-sources\java\org\apache\hadoop\hbase\package-info.java:[6,9] 错误: 需要class, interface或enum [ERROR] -> [Help 1] |
打开package-info.java:
| /* * Generated by src/saveVersion.sh */ @VersionAnnotation(version="1.2.3", revision="Unknown", user="mooon\mike ", date="Tue Oct 25 18:02:39 2016", url="file:///cygdrive/e/bigdata/hbase-1.2.3-src", srcChecksum="88f3dc17f75ffda6176faa649593b54e") package org.apache.hadoop.hbase; |
,可以看到问题出在“mike”后多了一个换行符,正常应当是:
| /* * Generated by src/saveVersion.sh */ @VersionAnnotation(version="1.2.3", revision="Unknown", user="mooon\mike", date="Tue Oct 25 18:02:39 2016", url="file:///cygdrive/e/bigdata/hbase-1.2.3-src", srcChecksum="88f3dc17f75ffda6176faa649593b54e") package org.apache.hadoop.hbase; |
查看hadoop-common的saveVersion.sh,部分内容如下:
| unset LANG unset LC_CTYPE
version=$1 outputDirectory=$2
pushd . cd ..
user=`whoami` date=`date` cwd=`pwd` |
问题就出在whoami命令返回了mooon\mike,并且mike后跟了一个换行符导致的,因此可以如下消灭多余的换行符:
| unset LANG unset LC_CTYPE
version=$1 outputDirectory=$2
pushd . cd ..
user=`whoami|awk '{printf("%s",$1);}'` date=`date` cwd=`pwd` |
再次编译,仍然报错:
| [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:2.5.1:compile (default-compile) on project hbase-common: Compilation failure [ERROR] E:\bigdata\hbase-1.2.3-src\hbase-common\target\generated-sources\java\org\apache\hadoop\hbase\package-info.java:[5,39] 错误: 非法转义符 [ERROR] -> [Help 1] |
再次打开package-info.java:
| /* * Generated by src/saveVersion.sh */ @VersionAnnotation(version="1.2.3", revision="Unknown", user="mooon\mike", date="Tue Oct 25 17:59:21 2016", url="file:///cygdrive/e/bigdata/hbase-1.2.3-src", srcChecksum="88f3dc17f75ffda6176faa649593b54e") package org.apache.hadoop.hbase; |
问题出在“mooon\mike”间的斜杠,需要将单个斜杠改成双斜杠“mooon\\mike”或者干脆去掉“mooon\”仅保留“mike”也可以。
再次修改saveVersion.sh,直接写死user:
| unset LANG unset LC_CTYPE
version=$1 outputDirectory=$2
pushd . cd ..
user=mike date=`date` cwd=`pwd` |
然后再次编译hadoop-common,终于成功了: