我们希望 Java 应用程序的计算部分只涉及 Java 源代码的一小部分。Jalape�o 的优化编译器致力于高效地编译这些字节码。优化编译器是 动态的:它在应用程序运行时编译方法。将来,优化编译器也将是 自适应的:它将在计算密集的方法上被自动调用。优化编译器的目标是在给定的编译时间预算内生成所选定方法的尽可能好的代码。此外,它的优化必须在正确地保护异常、垃圾回收和线程的 Java 语义的同时很大地提高性能。对实现 SMP 服务器的可伸缩性性能来说,降低同步和其它线程原语的花费尤其重要。最后,以最少的工作量把优化编译器的目标重定向到各种硬件平台应是可能的。构建达到这些目标的动态优化编译器是一个很大的挑战。
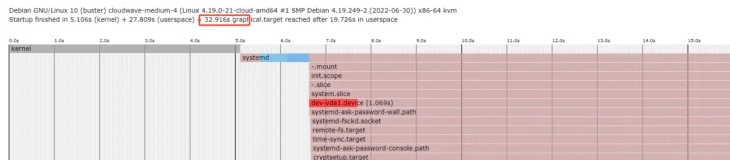
这个部分提供了 Jalape�o 优化编译器的概述;更详细的信息可在别处找到。 15 优化编译器的结构如图 4 所示。
从字节码到中间表示(intermediate representation) 优化编译器从把 Java 字节码转换成 高级中间表示(high-level intermediate representation(HIR))开始。这是基于寄存器的三个中间表示之一,这些中间表示共享一个公共实现。(基于寄存器的表示比基于堆栈或树的表示在代码移动和代码转换方面有更大的灵活性。它们也允许更接近 Jalape�o 的目标体系结构的指令集。)这些中间表示的指令是 n 元组:一个 操作符和零个或多个 操作数。多数操作数表示的是符号寄存器,但它们也可以表示物理寄存器、内存位置、常数、分支目标或类型。这些中间表示反映了 Java 的类型结构:对不同基本类型上的相似操作有截然不同的操作符,操作数带有类型信息。 17 指令被组合进扩展的基础块,方法调用或可能导致抛出异常的指令都不能终止这些块。(当进行数据流分析或移动这些扩展块上的代码要特别小心。) 16, 17 这些中间表示也包含高速缓存诸如可达定义(reaching-definition) 18 集合、依赖图和循环嵌套结构的编码这样的可选的附加信息。
转换过程发现方法的扩展基础块,为方法创建异常表并为字节码创建 HIR 指令。它发现并编码类型信息,这些信息可用于随后的优化,而且引用映射表也需要这些信息。一定程度简单的“快速”优化 ― 副本传播、常数传播、本地变量的寄存器重命名、死代码清除等等 ― 也被执行。 19 (尽管在稍后的优化阶段会执行这些优化的更多版本,在这里执行它们还是值得做的,因为这样做减小了生成的 HIR 的大小,从而减少随后的编译时间。)此外,合适地短的 final 或 static 方法被内联了。
副本传播是在转换期间执行快速优化的一个示例。Java 字节码常常包含执行计算并把结果存储到本地变量的指令序列。对中间表示的生成的一个天真想法是为计算结果创建一个临时寄存器,并另外用一条指令把这个寄存器的值移入本地变量。简单的副本传播试探法清除了大量这些不必要的临时寄存器。当从临时寄存器把值存储到本地变量时,将检测到最近生成的指令。如果是这条指令创建了这个临时寄存器来存储结果,那么这条指令就被改成把结果直接写到本地变量。
转换通过字节码的 抽象解释继续进行。按照 Java 虚拟机规范 20 的定义,本地变量的类型(如果在编译时已知,则还包括值)和执行堆栈的条目构成了抽象解释的 符号状态。(因为这些类型不是从 Java 字节码静态可用的,因此所有的 Jalape�o 编译器都必须有效地跟踪这个符号状态。)字节码的抽象解释涉及生成适当的 HIR 指令和更新符号状态。
转换算法的主循环使用一个包含代码块和它们的初始符号状态的工作表(list)。最初,这个工作表包含开始于字节码 0 的代码和每个方法的异常处理程序(符号状态为空)的条目。代码块相继被从工作表中移走并把它们当作扩展基础块对它们进行解释。如果碰到一个分支,则块被分隔并将碎块添加到工作表。(在控制流汇合点,从不同流传入的堆栈操作数的值可能不同,但这些操作数的类型必须匹配。 21 一个元素智能的 meet 操作被用在在堆栈操作数上以更新这些点上的符号状态。 19 )如果一个分支是向前跳转的,则从块的开头到这个分支的一块被暂时看作一个完整的扩展基础块。从该分支到它的目标和从该目标到块的末端的块被添加到工作表。如果分支是向后跳转的,则从分支到块的末端的块被添加到工作表。如果向后跳转分支的目标在一个已经生成了的扩展基础块中,则这个块将在目标点被分隔。如果堆栈在目标点不空,则块必须重新生成,因为它的开始状态可能是不正确的。
为尽量减少为同块字节码生成 HIR 的次数,简单贪婪算法为抽象解释选择有最低开始字节码索引的块。这个简单的试探法依赖于这样的事实,即除了循环,所有控制流构造都是以拓扑有序方式生成的,而且控制流图是可简化的。偶而地,这个试探法看来获得了用当前 Java 源代码编译器编译的方法的扩展基础块的最优顺序。
高级优化 HIR 中的指令很好地模仿了 Java 字节码,有两个重要不同 ― HIR 指令在符号寄存器操作数上进行操作,而不是在隐式堆栈上,而且 HIR 包含独立的操作符,用于实现运行时异常的显式检查(例如,数组边界检查)。相同的运行时检查通常需要多于一条的指令。(例如,incrementing A[ i] 可能涉及两个独立的数组访问,但只需一次边界检查。)对这些检查指令的优化减少了执行时间并使另外的优化更容易。
当前,HIR 使用带有适度编译时开销的简单的优化算法。这些优化有三类:
- 本地优化。这些优化对扩展基础块是本地的,例如,公共子表达式清除、冗余异常检查清除以及冗余装入清除。
- 流不敏感优化。为在基础块之间进行优化,就要利用 Java 虚拟机规范的“Java 程序中的每个变量在被使用前必须有值” 20 保证。如果一个变量只被定义一次,则该定义将影响到每次使用。对这样的变量,可构建“定义- 使用”链,进行副本传播,并且不需昂贵的控制流或数据流分析即可清除死代码。此外,编译器执行保守的流不敏感的转义分析以把聚集的标量替换和调用的语义扩展变换转义到标准 Java 库方法。 22
这种技术能捕捉到很多优化机会,但其它的情况只能由流敏感的算法检测到。
- 方法调用的内联扩展。为在 HIR 级别上把方法调用扩展成内联,被调用方法的 HIR 被生成并被补入到调用者的 HIR。静态的、基于大小的试探法当前用于控制对静态和最后方法的调用的自动内联扩展。对于非最后虚方法调用,优化编译器预测虚调用的接收方为对象的声明类型。它用运行时测试来监视每个内联虚方法以验证对接收方的预测是正确的,如果不正确,则缺省设置为正常虚方法调用。在有动态类装入的情况下,这种运行时测试是安全的。
由于 Jalape�o 是用 Java 写的,与用于把应用程序方法扩展为内联的框架相同的框架也可用于把对运行时方法的调用扩展为内联(特别是同步和对象分配)。一般说来,从应用程序代码到 Java 库,下至 Jalape�o 运行时系统,都可以把调用扩展为内联,这为优化提供了极好的机会。
低级优化 在执行了高级分析和优化之后,HIR 被转换为 低级中间表示(low-level intermediate representation(LIR))。LIR 把 HIR 指令扩展为特定于 Jalape�o 虚拟机的对象布局和参数传递约定的操作。例如,虚方法调用被表达为类似于 invokevirtual 字节码的单条 HIR 指令。这一条 HIR 指令被转换在三条 LIR 指令,分别负责从一个对象获得 TIB 指针,从 TIB 获得适当方法体的地址,以及将控制转到方法体。
由于字段和头的偏移量现在都是可用的常数,新的优化机会出现了。原则上,任何高级优化也可用在 LIR 上。然而,由于 LIR 的大小可能是相应 HIR 大小的两到三倍,所以在进行 LIR 优化时要更留意编译时间开销。目前,清除本地的公共子表达式是 LIR 上进行的唯一优化。由于 HIR 和 LIR 共享相同的基础设施,所以在 HIR 上执行公共子表达式清除的代码不用修改就可重用在 LIR 上。
同样,作为低级优化的最后一步,我们为每一个扩展基础块构造一个 依赖图。 17 依赖图用于指令选择(请参阅下一部分)。依赖图的每个节点是一条 LIR 指令,而每一条边对应于一对指令的依赖约束。边可表示真、假以及寄存器和内存的输出依赖 17 。边还可表示控制、同步和异常依赖。通过在同步操作(monitor_enter 和 monitor_exit)和内存操作之间引入 同步依赖边建立同步约束的模型。这些边阻止内存操作的代码移动越过同步点。Java 异常语义模型 20 通过用 异常依赖边链接扩展块中的不同异常点来建立。异常依赖边也被添加到这些异常点之间和本地变量的寄存器写操作之间,如果方法中有任何异常处理大块空间,则这些本地变量就“生活”在其中。依赖约束的精确模型使我们可以在下一个优化阶段对代码进行激烈的重新排序。
指令选择和特定于机器的优化 在低级优化之后,LIR 被转换成 特定于机器的中间表示(machine-specific intermediate representation(MIR))。当前的 MIR 反映 PowerPC 体系结构。(如果 Jalape�o 被移植到不同的体系结构,可以引入另外的 MIR 指令集。)方法的扩展基础块的依赖图被转换成树。这些用于 自下而上重写系统(bottom-up rewriting system(BURS)) 23 ,这个系统产生 MIR。然后符号寄存器映射到物理寄存器。在每个方法的开始添加 序言,在结尾添加 结语(epilogue)。最后,就生成了可执行代码。
BURS 是代码生成器(code-generator)生成器,类似于扫描器和分析器生成器。想得到的目标体系结构的指令选择由 树语法(tree grammar)指定。树语法中的每一条规则都有一个相关花费(反映生成的指令的大小和指令的预期周期数)和代码生成动作。处理树语法以生成一组表,这些表在编译时驱动指令选择。
在指令选择上使用 BURS 技术有两个重要好处。首先,编译时进行的树型匹配法通过使用动态编程为所有输入树找到了最少花费的分析(与树语法中指定的花费相比)。其次,构建 BURS 基础设施的花费可在几个目标体系结构中分期付清。特定于体系结构的部分相对较少;Jalape�o 的 PowerPC 树语法约有 300 条规则。
BURS 中的树型匹配法最初是开发用来从基于树的中间表示生成代码的,通常是在没有全局优化的场合。为树型匹配法生成有向非循环图的以前的办法只考虑了包含寄存器真依赖(register-true-dependence)边的图。 24 我们的办法更通用,因为它考虑了存在寄存器和非寄存器依赖两种情况下的转换。对这种区分的合法约束不是微不足道的。 25
在构造了 MIR 之后,就执行活动变量分析,以判断符号寄存器和堆栈变量的活动范围,这些堆栈变量保存了位于垃圾回收安全的点的对象引用。标准活动变量分析 18 已被修改成处理 控制流分解图的扩展基础块的,如 Choi 等人所描述的那样。 16
接着,优化编译器使用 线性扫描全局寄存器分配算法 26 来把物理机器寄存器指定给符号 MIR 寄存器。这个算法不是基于图染色的,但却贪婪地在符号寄存器的活动范围的一次线性扫描时间内把物理寄存器分配给符号寄存器。这个算法比图染色算法快几倍,而结果代码的效率几乎一样。更成熟(花费也更大)的寄存器分配算法最终将在更高级别的优化上使用(请参阅下一部分)。(当前在快速编译器中使用的算法比在优化编译器中使用的算法更昂贵,对作者真是一个讽刺。)
方法序言分配一个堆栈框架,保存方法需要的任何非易失性寄存器,并且检查是否有人提出让出请求。结语恢复任何被保存的寄存器并解除堆栈帧分配。如果方法被同步,则序言锁定,而且结语解锁,指定对象也被同步。
优化编译器然后把可执行的二进制代码放到指令数组,即方法体。通过把中间指令偏移量转换为机器代码偏移量,这个装配阶段也最后确定了异常表和指令数组的引用映射图。
优化的级别 优化编译器可在不同的优化级别上执行。每个级别都包含前一级别的所有优化和一些其它东西。 级别 1恰好包含上面描述的优化。(存在 级别 0 主要是出于调试的目的,它与级别 1 相似,但没有任何高级或低级优化。)两个级别的更加激烈的优化也在计划之中。
级别 2 优化将包括代码说明,过程内的流敏感优化和指令调度,流敏感优化基于 静态单指定(static single assignment(SSA))形式(标量 27 和数组 28 )的成熟的寄存器分配。指令调度目前正在实现之中。它使用 MIR 依赖图,这个图用与 BURS 用来构建 LIR 依赖图相同的代码来构建。
级别 3 优化包括过程内的分析和优化。目前,过程内的转义分析 29 和寄存器保存和恢复的过程内优化 15 都正在实现之中。
操作的形态。 优化编译器的前端(转换到 HIR 和高级优化)不依赖于 Jalape�o 的对象布局和调用约定。一个字节码优化项目正在使用这个前端。 30
优化编译器的运作方式是想作为自适应 JVM 的一个组件。图 5 显示了这样一个虚拟机的整体设计。优化编译器是 Jalape�o 的自适应优化系统的关键组成部分,这个自适应系统也包含联机测量(on-line measurement)和正在开发的控制器子系统(controller subsystem)。通过使用软件采样和成型技术和来自硬件性能监视器的信息的概要,联机测量子系统将监视单个方法的性能。当联机测量子系统检测到某个性能阈值被达到时,控制器子系统将被调用。控制器将用概要信息构建一个“优化计划”,这个计划描述了哪个方法应被编译以及应用哪一个优化级别。然后调用优化编译器来编译优化计划中的方法。联机测量子系统继续监视单个方法,包括那些已经优化的方法,以在必要时触发进一步的优化过程。
除上面描述的动态编译方式之外,优化编译器也可用作静态编译器,如图 6 所示。在这种方式下,优化编译器生成的优化代码被存储在引导映像(boot image)中(请参阅 附录 B)。优化编译在执行 Jalape�o 虚拟机之前脱机进行。(我们希望最终能把两种方式合并。应用程序运行一会儿,自适应优化系统就为该应用程序优化 JVM。最后,这个优化后的 JVM 将作为特定于该应用程序的引导映象被写出来。)
优化编译器也可用作 JIT 编译器,在方法第一次执行时编译所有方法。当要设定优化编译器的性能基准时,优化编译器同时用作静态引导映象编译器(针对引导映象的 JVM 代码)和 JIT 编译器(针对基准程序代码和任何余下的 JVM 代码)。