谷歌大脑Jeff Dean等人最新提出一种分层模型,用于将计算图有效地放置到硬件设备上,尤其是在混合了CPU、GPU和其他计算设备的异构环境中。
设备配置(Device placement)可以被框定为学习如何在可用设备之间对图进行分区,将传统的图分区方法作为一个自然的baseline。先前的工作有Scotch 提出的一个用于图分区的开源库,其中包括k-way Fiduccia-Mattheyses, Multilevel 方法, Band 方法, Diffusion 方法和Dual Recursive Bipartitioning Mapping。
我们此前已经提出利用深度网络和强化学习进行组合优化[4,13,20]。ColocRL [13]使用一个递归神经网络(RNN)策略网络来预测计算图中操作的位置。虽然这种方法优于传统的图形分区启发式算法和人类专家配置方法,但它仅限于小图形(少于1000个节点),并且需要人类专家手动将图分配到配置组中,作为预处理步骤。
在本文中,我们介绍了一种更灵活的端到端方法,该方法学习优化具有数万个操作的神经网络的设备配置。与以前需要人工专家提供硬件属性或手动集群操作的方法不同,这一方法是自动化的,可以扩展到更大的计算图和新的硬件设备上。对于Inception-V3 [19],ResNet [7],语言建模[10]和神经机器翻译[22]等模型,这一方法在多种设备上找到了有意义的配置。我们的模型找到的配置优于TensorFlow的默认配置[1],Scotch算法的配置以及人类专家的配置,从而实现每个训练步骤的运行时间减少高达60.6%。
分层策略网络方法:Grouper + Placer
我们训练了一个分层策略网络(hierarchical policy network),可以产生优化的配置。该策略网络由两个子网络组成:一个叫Grouper,作用是在输入TensorFlow图中将操作分配给groups;以及一个Placer,作用是将groups分配给目标设备。我们使用策略梯度方法来联合训练两个子网络,并将预测配置的运行时间(runtime)作为网络的reward,如图1所示。
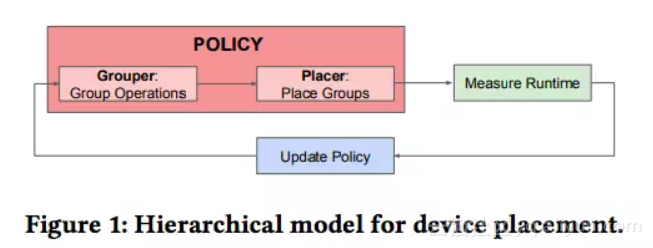
图1:设备配置的分层模型
我们将这一方法称为“分层规划器”(Hierarchical Planner),它的目的是将目标神经网络的一个前向通道,一个反向传播通道和一个参数更新的运行时间最小化。为了测量运行时间,预测的配置需要在实际的硬件上运行。
Grouper是一个前馈模型,Placer是一个序列 - 序列模型,具有长短期记忆和基于内容的注意机制。为了将操作表示为Grouper的输入,我们对关于操作的信息进行编码,包括类型(例如,MatMul,Conv2d,Sum等),输出的大小和数量,以及与其他操作的连接。我们通过组合成员操作的嵌入来创建group嵌入。每个group嵌入是三个组件的连接:成员操作类型嵌入的平均值,成员操作大小和输出数量的平均值,以及编码为邻接矩阵的组内和组间连接信息。
Placer的RNN编码器一次读取一组嵌入,并产生M个隐藏状态。M等于组数,我们将M作为一个超参数。Placer的解码器RNN每个时间步预测一个device。这些device以与输入组嵌入相同的顺序返回,即,第一组中的操作将被放置在由第一个解码器步骤返回的device上,以此类推。每个device都有自己的可训练嵌入,然后将其作为输入提供给下一个解码器时间步骤。
Planner根据Grouper和Placer做出的决定来优化目标模型(例如,TensorFlow graph)的训练时间。设为预测的设备配置
的每个训练步骤的运行时间。我们将配置
的reward定义为
。Planner应该尽量使
对其决策的期望最大化。因此,我们优化的成本函数是:
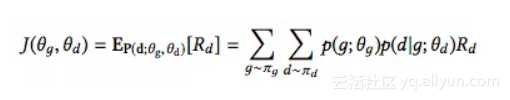
设和
分别为Grouper和Placer的参数。这里,
是从Grouper softmax分布
绘制的样本组配置 g 的概率,
是从Placer softmax分布
绘制的样本设备配置 d 的概率。我们使用 REINFORCE 规则[21]来优化成本函数。
我们的策略是以分布式的方式训练的,参数服务器由多个控制器共享。控制器异步更新策略。我们使用4个控制器和16个worker(每个控制器4个)。每个worker执行其控制器给出的配置并报告运行时间。每个控制器都托管在一个GPU上。worker们并行地运行配置。一旦所有worker都完成了运行,控制器将使用测量到的运行时间来计算梯度。
实验
我们在四个广泛使用的神经网络模型中评估我们的方法:Inception-V3(batch size= 32),24713次操作;ResNet(batch size= 128),20586次操作;RNNLM(batch size= 64),9021次操作;以及NMT(batch size= 64),分别具有2层,4层和8层encoder-decoder,分别是28044次,46600次和83712次操作。
我们将结果与以下方法进行比较:CPU和GPU,仅在单个CPU或GPU上放置整个模型的baseline。Scotch static mapper[16],它将图(graph)、每个操作的计算成本以及相关设备的计算能力和通信能力作为输入。Mincut baseline与Scotch类似,但我们的设备只考虑GPU。作为比较的手工配置来自以前出版的论文。对于Inception-V3和Resnet,人类专家将图形放置在单个GPU上。对于RNNLM和NMT,现有工作[18,23]将每个LSTM层放置在单独的GPU上。
我们的实验在有1个Intel Haswell 2300 CPU和最多8个Nvidia Tesla K40 GPU的机器上运行。我们使用TensorFlow r1.3来运行评估。
结果:性能提升最高60.6%
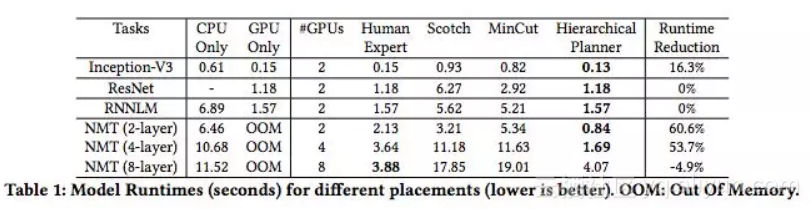
表1:不同配置的模型的运行时间(s)(越低越好)。 OOM:内存不足
表1展示了 Hierarchical Planner的性能。我们的方法可用的唯一信息是TensorFlow图和一个设备列表。减少的百分比的计算方法是Hierarchical Planner实现的运行时间与先前最佳配置的运行时间的差,然后再除以先前的最佳运行时间。对于每个模型,我们都会制定一项新策略,学习如何优化该特定模型的配置。所有结果都是在更新策略的1000次迭代之后计算的。实际上,这最多需要三个小时。这个策略本身是一个轻量级的网络,在单个GPU上进行训练。
对于ResNet和RNNLM,我们的模型发现使用单个GPU更高效,因为这可以最大限度地降低通信成本。对于Inception-V3, Hierarchical Planner学习将模型分布到2个GPU中,与将模型放置在单个GPU上相比,运行时间减少了16.3%。对于具有2层、4层和8层的NMT,我们分别使用2个,4个和8个GPU进行实验。对于NMT(2层),我们的结果优于先前最好的将结果60.6%;对于NMT(4层),优于最佳结果53.7%;对于NMT(8层), Hierarchical Planner发现的配置比人类专家的慢4.9%。即使Hierarchical Planner的表现略有不足的这一情况,仍然有必要采用一种自动化的方法来找到与人类专家相媲美的配置。
与Scotch和MinCut相关的结果显着低于人类专家baseline,这与[13]中报告的结果一致。
考虑到我们训练目标神经网络有成千上万个步骤,策略训练的开销是合理的。例如,为了训练WMT'14 En-> Fr数据集,该数据集在一个epoch(batchsize= 64)具有超过3600万个examples,我们运行NMT模型需要大约562500步。由于我们将运行时间从3.64秒减少到1.69秒,因此每个epoch都可以节省304个GPU-hours,即使我们考虑用约102个GPU-hours训练策略,这也是非常显著的节省。
结论
我们提出一种分层方法,可以有效地将计算图的操作配置到设备上。我们的方法完全是端到端的,并扩展到包含超过80,000个操作的计算图。我们的方法在图中找到了高度细化的并行性,使之能够比以前的方法性能超出60.6%。
原文发布时间为:2018-02-25
本文作者:马文
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号

