定义
hashmap基于哈希表
的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 根据需要该容器可能会对元素重新哈希,元素的顺序也会被重新打散,因此不同时间迭代同一个HashMap的顺序可能会不同。根据对冲突的处理方式不同,哈希表有两种实现方式,一种开放地址方式(Open addressing),另一种是冲突链表方式(Separate chaining with linked lists)。Java HashMap采用的是冲突链表方式。
hashmap与map的关系图如下:
hashmap结构图:

hashMap类的成员变量:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;// 默认初始容量为16,必须为2的幂
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;// 最大容量为2的30次方
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;// 默认加载因子0.75
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table;// Entry数组,哈希表,长度必须为2的幂
/**
* The number of key-value mappings contained in this map.
*/
transient int size;// 已存元素的个数
/**
* The next size value at which to resize (capacity * load factor).
* @serial
*/
int threshold;// 下次扩容的临界值,size>=threshold就会扩容
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;// 加载因子
HashMap有两个参数影响其性能:初始容量和加载因子。默认初始容量是16,加载因子是0.75。容量是哈希表中桶(Entry数组)的数量,初始容量只是哈希表在创建时的容量。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
HashMap的三构造方法
第一个
使用默认初始容量16和加载因子0.75的hashmap
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75). 使用默认的初始化容量16和加载因子0.75
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
第二个
自定义初始容量和加载因子的hashmap
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor. 自定义初始容量以及加载因子
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
第三个
自定义初始容量,使用默认加载因子0.75的hashmap
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75). 自定义初始容量,使用默认的加载因子0.75
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR); //调用第二个构造方法
}
方法剖析
put方法源码:
public V put(K key, V value) {
// 处理key为null,HashMap允许key和value为null
if (key == null)
return putForNullKey(value);
// 得到key的哈希码
int hash = hash(key);
// 通过哈希码计算出bucketIndex
int i = indexFor(hash, table.length);
// 取出bucketIndex位置上的元素,并循环单链表,判断key是否已存在
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 哈希码相同并且对象相同时
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 新值替换旧值,并返回旧值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// key不存在时,加入新元素
modCount++;
addEntry(hash, key, value, i);
return null;
}put(K key, V value) 方法是将指定的 key, value 对添加到 map 里。该方法首先会对 map 做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于 getEntry() 方法;如果没有找到,则会通过 addEntry(int hash, K key, V value, int bucketIndex) 方法插入新的 entry ,插入方式为头插法。
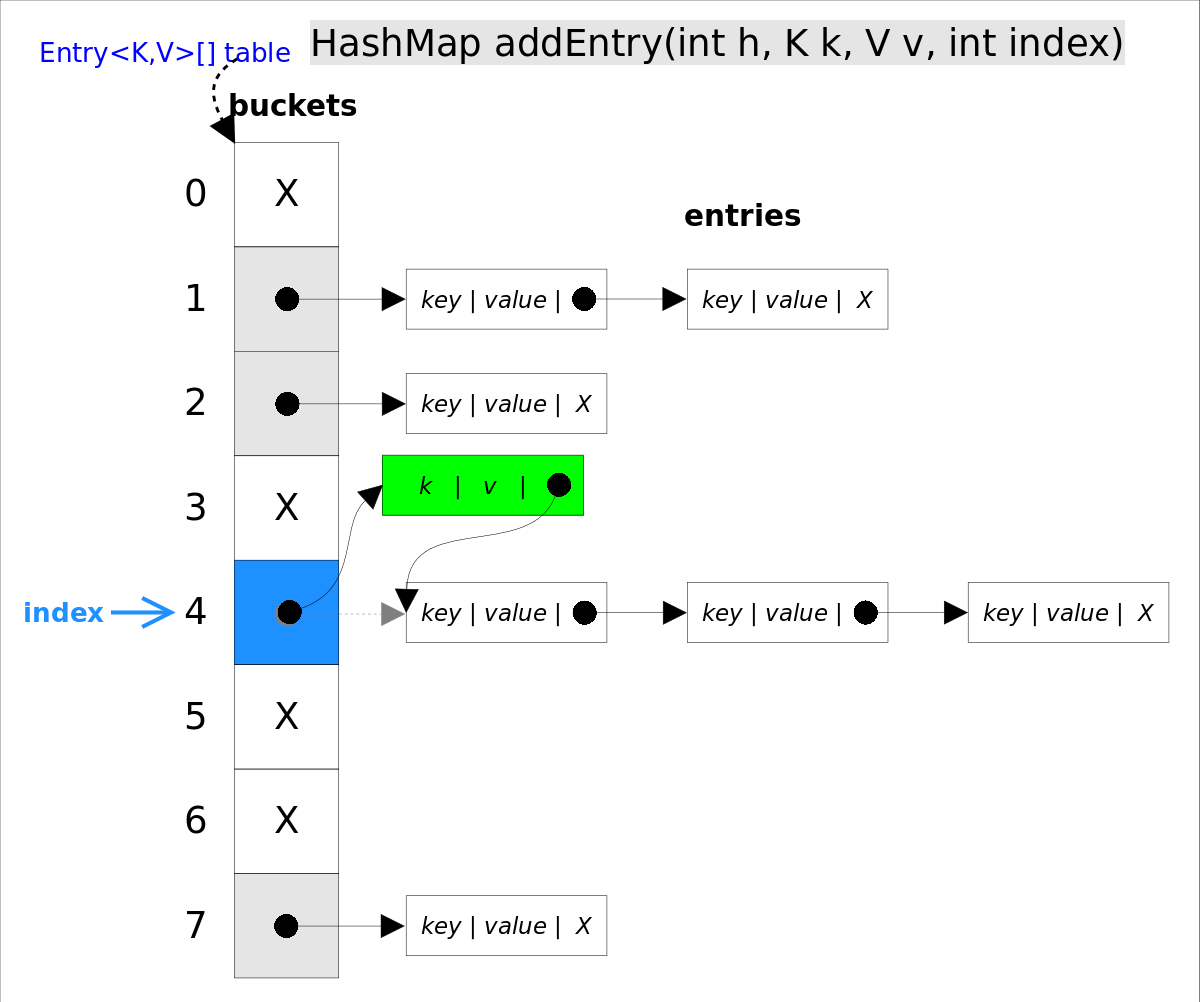
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
我们了解到put方法两件事:
- HashMap通过键的hashCode来快速的存取元素。
- 当不同的对象hashCode发生碰撞时,HashMap通过单链表来解决冲突,将新元素加入链表表头,通过next指向原有的元素。在单链表如果发现对象以及存在,则用新的value替换原有的value。
HashMap的遍历有两种常用的方法,那就是使用keyset及entryset来进行遍历。
第一种:
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}效率高,以后可以考虑多使用此种方式!
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}get()方法源码:
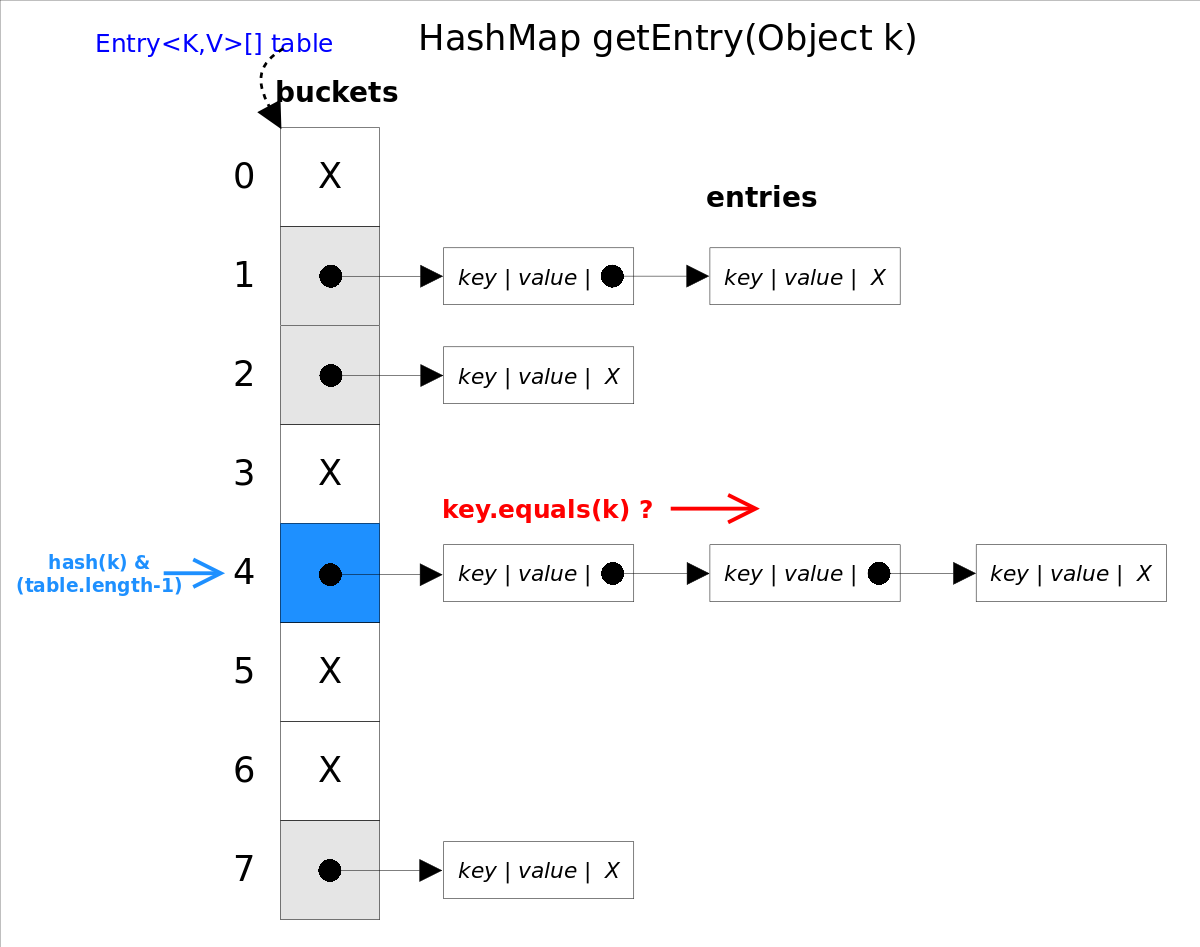
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
get()通过indexFor()获取要查找的value位置,如果这个位置有value,且这个value不是要查找的value,则在value所属的单链表中继续查找,直到满足“e.hash == hash && ((k = e.key) == key || key.equals(k))”。