IPv4实际上是一个被设计的很勉强的协议,远远没有TCP等传输层协议设计的好。对于它的升级版,IPv6,实际上我也一样不看好,虽然它解决了很多问题,扩展了地址空间,增加了协议堆栈化的支持...
此后,IP地址又可以划分子网了,同时又有了超网一说,然后就是路由汇聚,所有这一切都需要基于分类的路由表项生成算法以及查找算法作相应的修改。Cisco的路由器就支持两种逻辑,一种是分类的,另一个是无类的。
终于,CIDR出现了,路由查找算法也相应的变成了“最长前缀匹配算法”,这种算法统一了所有的路由查找算法,必要时侯也可以退化到兼容分类路由的程度。路由模块如何实现不重要,重要的是你是把IP地址当成一个平坦的空间看呢,还是将它看成一个分级的地址空间呢?举个例子吧,32位系统中的内存地址也是32位,和IP地址一样,我们看到处理器和主板芯片组中存在那么多精巧的小芯片,它们精巧的逻辑正是在处理路由和地址变换,正是它们让元器件之间以及其与外设之间的“绝妙互联”成为可能,然而这种精妙的逻辑并不是直接被设计出来的,而是在有了分级的地址空间之后才设计的。页表之类的处理逻辑正是做这个的。
如果你不对地址作规划,而只是将其作为一个平坦的一维空间看待的话,它标示的东西早晚会不可控。另外就是如何分级的问题,起初IP地址被分成了5个类别,这是一种固定的分级方式,而如今的CIDR则是一种更加动态的分级方式,二者相比各有千秋,估计法实现简单,效率高,但是管理不便,动态法则更容易满足动态的需求。如果我们看路由查找的实现算法,Cisco的256叉树是一种固定的算法,而Linux的Trie树则是动态的算法。
如主板芯片组规划一样,IP地址规划的好坏也会影响到“世界互联网”这块大主板的设计。什么事一旦有人参与就复杂了,我们不会行走于散热片之间,然而我们却每天都在敲击着键盘。
以往MPLS之类的协议出来以前,即使是Cisco这类巨头也只是使用CEF之类的技术来加速转发,没有明说,然而CEF实则就是一种交换技术,在CEF之前,使用的Cache之类的加速技术。CEF将路由和转发交换相分离,不再为数据包再去查找路由表,而是先根据路由表生成一张“转发表”,然后数据包通过“交换技术”直接根据转发表来被发送到合适的链路。这张转发表是如何建立的呢?实际上是“默默地”建立的,系统在没有包要发送的时候,默默地通过ARP得到每一条路由下一跳的链路层地址,然后构建转发表...
MPLS只是更加逻辑化的CEF,它也是默默地建立起标签-端口映射表,通过标签交换协议可以很容易做到。然后在IP数据报的外表打上标签,每一个“MPLS交换机”基于标签进行快速交换,在无连接的IP协议外面默默构建了一条虚拟的标签通道,并且为了能表现IP地址分级的逻辑,标签可以嵌套,根据标签层次的不同,我们也就能映射到每一层标签所代表的IP地址级别。堆栈化的标签协议所要表达的正如CIDR中的前缀(prefix,掩码)所要表达的意思一样。
Identification只有16位,因此只能在65535,这在快速网络上很快就会回绕,为了协议的紧凑,该字段又不能太大,因此就定在了16位。至于如何防止回绕,RFC791并没有细说:
Identification
The choice of the Identifier for a datagram is based on the need to
provide a way to uniquely identify the fragments of a particular
datagram. The protocol module assembling fragments judges fragments
to belong to the same datagram if they have the same source,
destination, protocol, and Identifier. Thus, the sender must choose
the Identifier to be unique for this source, destination pair and
protocol for the time the datagram (or any fragment of it) could be
alive in the internet.
It seems then that a sending protocol module needs to keep a table
of Identifiers, one entry for each destination it has communicated
with in the last maximum packet lifetime for the internet.
However, since the Identifier field allows 65,536 different values,
some host may be able to simply use unique identifiers independent
of destination.
It is appropriate for some higher level protocols to choose the
identifier. For example, TCP protocol modules may retransmit an
identical TCP segment, and the probability for correct reception
would be enhanced if the retransmission carried the same identifier
as the original transmission since fragments of either datagram
could be used to construct a correct TCP segment.
实际上,使用一个字段无法标示“唯一性”,那就使用多个字段,于是源地址,目的地址,协议都用上了(由于IP协议只能控制到它自己的字段,因此不能假定任何猜测,所以就不能使用5元素了,毕竟像很多协议没有端口的概念)。这下可以了,基本不会回绕了,在Linux的实现上,针对每一个目的地,都绑定了一个peer字段,其ID在peer结构体中,也就是说,Linux实现的是针对每一个目的地的Identification,而不是全局的。对于“不能分段”的IP数据报,就无所谓了,就算重复了也无所谓。
RFC中还说了,建议让高层协议去维护这个Identification字段,不过这样可能会带来很多竞态,不利于多处理器并行。
除此之外,IP分段的Identification还会被NAT设备冲刷掉,使得数据分片到达目的地的时候重组失败。RFC只是说Identification由各个主机分别自行产生,没有提到任何其他的,因此比如说内网两台主机H1和H2同时使用http经由SNAT到达同一台目的地S1,恰巧两个主机的两个分段的Identification相同,穿越SNAT设备的时间也相差不久,它们的源地址会被改成相同的NAT设备的外网口地址,S1最终会认为来自H1和H2的分片是同一个IP数据报的分片,因为按照RFC的说法,它们的源地址,目的地址,协议,Identification字段均相同...
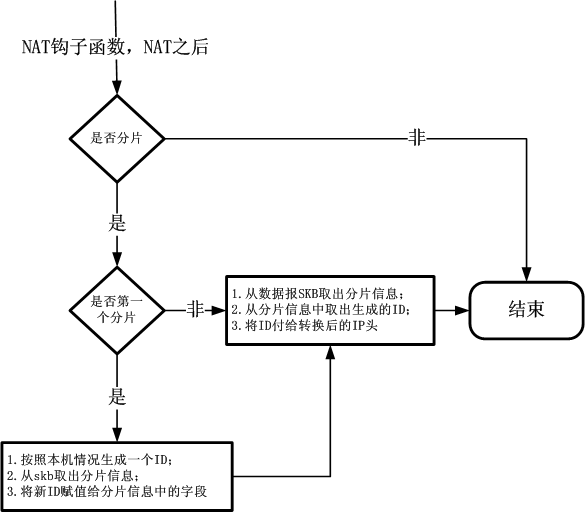
我们需要在ip_conntrack以及分片信息表项中保存一个NAT设备新生成的Identification,如果设备对数据报进行了NAT,那么就连Identification也一并转换了。如下图所示:
1.地址空间和路由模块
对于IPv4而言,其起初的地址空间是分类的,此时的路由表因此也是分类的,最显然的高效率实现方式就是每一类别一张表,路由器需要在查表逻辑之前有一个分类器来将IP数据报的目的地址分类,然后根据分类结果来查找相应的路由表。此后,IP地址又可以划分子网了,同时又有了超网一说,然后就是路由汇聚,所有这一切都需要基于分类的路由表项生成算法以及查找算法作相应的修改。Cisco的路由器就支持两种逻辑,一种是分类的,另一个是无类的。
终于,CIDR出现了,路由查找算法也相应的变成了“最长前缀匹配算法”,这种算法统一了所有的路由查找算法,必要时侯也可以退化到兼容分类路由的程度。路由模块如何实现不重要,重要的是你是把IP地址当成一个平坦的空间看呢,还是将它看成一个分级的地址空间呢?举个例子吧,32位系统中的内存地址也是32位,和IP地址一样,我们看到处理器和主板芯片组中存在那么多精巧的小芯片,它们精巧的逻辑正是在处理路由和地址变换,正是它们让元器件之间以及其与外设之间的“绝妙互联”成为可能,然而这种精妙的逻辑并不是直接被设计出来的,而是在有了分级的地址空间之后才设计的。页表之类的处理逻辑正是做这个的。
如果你不对地址作规划,而只是将其作为一个平坦的一维空间看待的话,它标示的东西早晚会不可控。另外就是如何分级的问题,起初IP地址被分成了5个类别,这是一种固定的分级方式,而如今的CIDR则是一种更加动态的分级方式,二者相比各有千秋,估计法实现简单,效率高,但是管理不便,动态法则更容易满足动态的需求。如果我们看路由查找的实现算法,Cisco的256叉树是一种固定的算法,而Linux的Trie树则是动态的算法。
如主板芯片组规划一样,IP地址规划的好坏也会影响到“世界互联网”这块大主板的设计。什么事一旦有人参与就复杂了,我们不会行走于散热片之间,然而我们却每天都在敲击着键盘。
2.分组交换
IP协议是分组交换的核心协议,是沙漏的中心。因此它被设计成了最简单的无连接协议。可是恰恰在核心网上,正有一股势力偏离了IP协议的初衷,这就是基于标签的协议,比如MPLS。MPLS实际上是一个有连接的协议,只不过这个连接不是建立在端到端的,而是分组交换意义上的,将“基于下一跳查找的路由”变成了“基于标签的交换路由”,这明显增加了效率。以往MPLS之类的协议出来以前,即使是Cisco这类巨头也只是使用CEF之类的技术来加速转发,没有明说,然而CEF实则就是一种交换技术,在CEF之前,使用的Cache之类的加速技术。CEF将路由和转发交换相分离,不再为数据包再去查找路由表,而是先根据路由表生成一张“转发表”,然后数据包通过“交换技术”直接根据转发表来被发送到合适的链路。这张转发表是如何建立的呢?实际上是“默默地”建立的,系统在没有包要发送的时候,默默地通过ARP得到每一条路由下一跳的链路层地址,然后构建转发表...
MPLS只是更加逻辑化的CEF,它也是默默地建立起标签-端口映射表,通过标签交换协议可以很容易做到。然后在IP数据报的外表打上标签,每一个“MPLS交换机”基于标签进行快速交换,在无连接的IP协议外面默默构建了一条虚拟的标签通道,并且为了能表现IP地址分级的逻辑,标签可以嵌套,根据标签层次的不同,我们也就能映射到每一层标签所代表的IP地址级别。堆栈化的标签协议所要表达的正如CIDR中的前缀(prefix,掩码)所要表达的意思一样。
3.IPv4协议头中的Identification字段
IPv4头中有一个Identification字段,它可了不得啊,关于它的讨论可谓多矣。然而它却只不过和分片重组有关系(可能还和压缩有关),如果没有分段重组,我们完全可以撇掉这个字段。它的存在就是为了标示属于同一个IP数据报的IP分片。Identification只有16位,因此只能在65535,这在快速网络上很快就会回绕,为了协议的紧凑,该字段又不能太大,因此就定在了16位。至于如何防止回绕,RFC791并没有细说:
Identification
The choice of the Identifier for a datagram is based on the need to
provide a way to uniquely identify the fragments of a particular
datagram. The protocol module assembling fragments judges fragments
to belong to the same datagram if they have the same source,
destination, protocol, and Identifier. Thus, the sender must choose
the Identifier to be unique for this source, destination pair and
protocol for the time the datagram (or any fragment of it) could be
alive in the internet.
It seems then that a sending protocol module needs to keep a table
of Identifiers, one entry for each destination it has communicated
with in the last maximum packet lifetime for the internet.
However, since the Identifier field allows 65,536 different values,
some host may be able to simply use unique identifiers independent
of destination.
It is appropriate for some higher level protocols to choose the
identifier. For example, TCP protocol modules may retransmit an
identical TCP segment, and the probability for correct reception
would be enhanced if the retransmission carried the same identifier
as the original transmission since fragments of either datagram
could be used to construct a correct TCP segment.
实际上,使用一个字段无法标示“唯一性”,那就使用多个字段,于是源地址,目的地址,协议都用上了(由于IP协议只能控制到它自己的字段,因此不能假定任何猜测,所以就不能使用5元素了,毕竟像很多协议没有端口的概念)。这下可以了,基本不会回绕了,在Linux的实现上,针对每一个目的地,都绑定了一个peer字段,其ID在peer结构体中,也就是说,Linux实现的是针对每一个目的地的Identification,而不是全局的。对于“不能分段”的IP数据报,就无所谓了,就算重复了也无所谓。
RFC中还说了,建议让高层协议去维护这个Identification字段,不过这样可能会带来很多竞态,不利于多处理器并行。
除此之外,IP分段的Identification还会被NAT设备冲刷掉,使得数据分片到达目的地的时候重组失败。RFC只是说Identification由各个主机分别自行产生,没有提到任何其他的,因此比如说内网两台主机H1和H2同时使用http经由SNAT到达同一台目的地S1,恰巧两个主机的两个分段的Identification相同,穿越SNAT设备的时间也相差不久,它们的源地址会被改成相同的NAT设备的外网口地址,S1最终会认为来自H1和H2的分片是同一个IP数据报的分片,因为按照RFC的说法,它们的源地址,目的地址,协议,Identification字段均相同...
4.Linux的NAT实现
Linux为了避免IP分片的NAT问题,它是这样实现的:在进行连接追踪之前,会进行分片重组,从而避免了上述的问题,然而牺牲了效率。见下面的HOOK钩子优先级定义:enum nf_ip_hook_priorities { NF_IP_PRI_FIRST = INT_MIN, NF_IP_PRI_CONNTRACK_DEFRAG = -400, ... NF_IP_PRI_CONNTRACK = -200, ... };
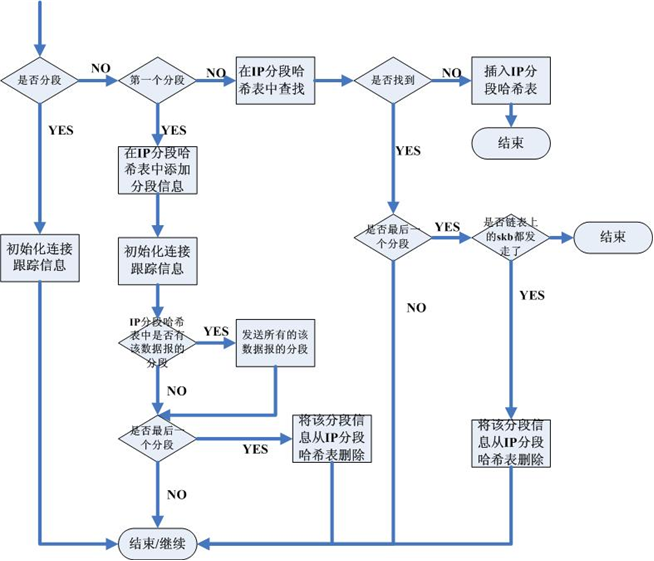
另一个方式就是不为NAT重组分片,见下图(该图在之前的文字中用过,然而第一个YES/NO画反了):
我们需要在ip_conntrack以及分片信息表项中保存一个NAT设备新生成的Identification,如果设备对数据报进行了NAT,那么就连Identification也一并转换了。如下图所示:
本文转自 dog250 51CTO博客,原文链接:http://blog.51cto.com/dog250/1268983

