在论坛上经常会有人问,到底是使用Trie算法保存路由表还是用Hash算法。那么我首先要明白,你要保存多大的路由表。简单的答案如下:
少量:Hash算法
大量:Trie算法
但是,仅仅这么回答会显得很业余,真的很业余。但是如果回答多了,恐怕也不是什么好事,关键看问者是谁,目的做甚。因此简单且完整的回答必须毫无针对性,只能写作日志供日后回忆了。
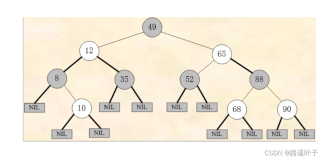
以Linux内核为例,如果是少量的路由表,Hash算法的性能会很高,一共32个Hash桶,每一个前缀一个,所有的路由表项挂在这些Hash桶的冲突 链表上,由于路由表项并不是很多,因此统计上看,每一个冲突链表的长度也不会太长,查询操作很简单,唯一不确定的就是遍历冲突链表,由于该链表很短,因此 很高效。
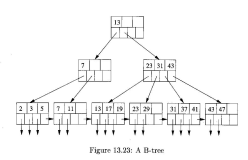
从Hash路由表的组织上看,Hash桶的数量是固定的,那么必然地,随着路由表项的增加,冲突链表的长度也会增加,如果是大量的路由表项,Hash算法 的性能会下降。那么此时Trie算法的优势就显而易见了,原因我不想多解释,这大早上的,一会儿还要去上班,不想一日的开始就讨论痛苦的细节,但是还是可 以从感性的角度说一点。如果你把Hash算法的核心看成了“它规划了32个Hash桶”,那么Trie算法的核心就是“它比较了IP地址的32个位”,不 考虑空间消耗,它最多可以在一棵32层的树中经过32次比较操作后得到答案,然而正如我的一篇命题作文里说的那样,这棵树肯定会被压缩,优化,因此代价可 能会是多了一些回溯,少量遍历操作,但是本质是一样的。
因此,不要用Hash存储大量的路由表。如何二者结合各取其优,很容易想到将Hash算法冲突链表给Trie化,这样的意义是可以做到提前了解到匹配或者 不匹配,不匹配的话还要进入下一个Hash桶,冲突链表的Trie化统计上看,提前感知“快速失败”,除非你的路由项前缀的32位明细的,不然的话,总有 退到24位前缀桶,16位前缀桶的时候...不管怎么说,确实比单纯的遍历Hash冲突链表要好。或者反过来,Trie算法中融入Hash操作,都是可以 的。
算法的纠结到此为止,如果你的回答到此结束,可以说你对系统的理解很深,但是你被问题本身捆住了。如果有人问我路由表到底是用什么数据结构存储呢?到底是 Hash算法快还是Trie算法快呢?如果我回答都不快!使用快速交换最快!那么提问者可能会觉得我的回答没有解释它的问题。然而我却给了更好的方案。接 下来谈谈我的方案。
高端的路由器(如果你没有碰过Cisco/华为的路由器,请绕道),一般会将路由子系统单独作为控制平面来运作,而数据平面的核心则是快速交换。路由表通 过静态配置,动态路由协议,路由重定向,链路层发现等生成,然后会通过一系列的硬件接口将路由表的表项注入到交换板,整个交换板上有一张硬件交换表。交换 板上的任何操作都和路由子系统是独立的,你可以将其看作是两个独立的系统。路由子系统由单独的CPU控制,这是一个慢速的系统,而交换子系统甚至可以没有 CPU,完全的片上转发,当然,它可能还是会有CPU,用来路由和处理非常规的控制报文以及管理报文。
至于交换板的内部什么样子,可以买一本大学教材来看。必须要理解的是,交换板是硬件的,它的设计思路和软件完全不同,很多高效的算法会因为成本问题,空间 损耗问题被直接pass。并且,交换技术大多是索引定位技术,而不是搜索技术,因为搜索算法依赖很多中间状态,而在硬件上,很难维护有状态的系统或者说需 要大量的空间维护状态信息。我们可以通过CPU Cache来理解交换机制,交换表可以看作是路由表的Cache,真是这么回事儿。CPU Cache和交换表都使用TCAM存储器,这是一个可以高速定位索引标记的存储器。表项存储在一个规整的硬件表中,通过标记来索引,而索引则是通过各种 “算法”来获取的,通过TCAM来完成。最常见的不是什么tree算法,而是Hash算法,因为它足够简单。当然,我的这篇《 以DxR算法思想为基准设计出的路由项定位结构图解 》文章中展示了另一种方案。
少量:Hash算法
大量:Trie算法
但是,仅仅这么回答会显得很业余,真的很业余。但是如果回答多了,恐怕也不是什么好事,关键看问者是谁,目的做甚。因此简单且完整的回答必须毫无针对性,只能写作日志供日后回忆了。
以Linux内核为例,如果是少量的路由表,Hash算法的性能会很高,一共32个Hash桶,每一个前缀一个,所有的路由表项挂在这些Hash桶的冲突 链表上,由于路由表项并不是很多,因此统计上看,每一个冲突链表的长度也不会太长,查询操作很简单,唯一不确定的就是遍历冲突链表,由于该链表很短,因此 很高效。
从Hash路由表的组织上看,Hash桶的数量是固定的,那么必然地,随着路由表项的增加,冲突链表的长度也会增加,如果是大量的路由表项,Hash算法 的性能会下降。那么此时Trie算法的优势就显而易见了,原因我不想多解释,这大早上的,一会儿还要去上班,不想一日的开始就讨论痛苦的细节,但是还是可 以从感性的角度说一点。如果你把Hash算法的核心看成了“它规划了32个Hash桶”,那么Trie算法的核心就是“它比较了IP地址的32个位”,不 考虑空间消耗,它最多可以在一棵32层的树中经过32次比较操作后得到答案,然而正如我的一篇命题作文里说的那样,这棵树肯定会被压缩,优化,因此代价可 能会是多了一些回溯,少量遍历操作,但是本质是一样的。
因此,不要用Hash存储大量的路由表。如何二者结合各取其优,很容易想到将Hash算法冲突链表给Trie化,这样的意义是可以做到提前了解到匹配或者 不匹配,不匹配的话还要进入下一个Hash桶,冲突链表的Trie化统计上看,提前感知“快速失败”,除非你的路由项前缀的32位明细的,不然的话,总有 退到24位前缀桶,16位前缀桶的时候...不管怎么说,确实比单纯的遍历Hash冲突链表要好。或者反过来,Trie算法中融入Hash操作,都是可以 的。
算法的纠结到此为止,如果你的回答到此结束,可以说你对系统的理解很深,但是你被问题本身捆住了。如果有人问我路由表到底是用什么数据结构存储呢?到底是 Hash算法快还是Trie算法快呢?如果我回答都不快!使用快速交换最快!那么提问者可能会觉得我的回答没有解释它的问题。然而我却给了更好的方案。接 下来谈谈我的方案。
高端的路由器(如果你没有碰过Cisco/华为的路由器,请绕道),一般会将路由子系统单独作为控制平面来运作,而数据平面的核心则是快速交换。路由表通 过静态配置,动态路由协议,路由重定向,链路层发现等生成,然后会通过一系列的硬件接口将路由表的表项注入到交换板,整个交换板上有一张硬件交换表。交换 板上的任何操作都和路由子系统是独立的,你可以将其看作是两个独立的系统。路由子系统由单独的CPU控制,这是一个慢速的系统,而交换子系统甚至可以没有 CPU,完全的片上转发,当然,它可能还是会有CPU,用来路由和处理非常规的控制报文以及管理报文。
至于交换板的内部什么样子,可以买一本大学教材来看。必须要理解的是,交换板是硬件的,它的设计思路和软件完全不同,很多高效的算法会因为成本问题,空间 损耗问题被直接pass。并且,交换技术大多是索引定位技术,而不是搜索技术,因为搜索算法依赖很多中间状态,而在硬件上,很难维护有状态的系统或者说需 要大量的空间维护状态信息。我们可以通过CPU Cache来理解交换机制,交换表可以看作是路由表的Cache,真是这么回事儿。CPU Cache和交换表都使用TCAM存储器,这是一个可以高速定位索引标记的存储器。表项存储在一个规整的硬件表中,通过标记来索引,而索引则是通过各种 “算法”来获取的,通过TCAM来完成。最常见的不是什么tree算法,而是Hash算法,因为它足够简单。当然,我的这篇《 以DxR算法思想为基准设计出的路由项定位结构图解 》文章中展示了另一种方案。
好了,小小起床了,虽然还没写完,也不写了,新的一天开始了。
本文转自 dog250 51CTO博客,原文链接:http://blog.51cto.com/dog250/1661074