引用实例被添加在引用队列中,可以在任何时候通过查询引用队列回收对象。
现在我对一个对象的生命周期进行描述:


package wys.demo1; public class Demo1 { public static Demo1 obj; @Override protected void finalize() throws Throwable { super.finalize(); System.out.println("CanReliveObj finalize called"); obj = this;// 把obj复活了!!! } @Override public String toString(){ return "I am CanReliveObj"; } public static void main(String[] args) throws InterruptedException{ obj = new Demo1();// 强引用 obj = null; //不会被立即回收,是可复活的对象 System.gc();// 主动建议JVM做一次GC,GC之前会调用finalize方法,而我在里面把obj复活了!!! Thread.sleep(1000); if(obj == null){ System.out.println("obj 是 null"); }else{ System.out.println("obj 可用"); } System.out.println("第二次gc"); obj = null; //不可复活 System.gc(); Thread.sleep(1000); if(obj == null){ System.out.println("obj 是 null"); }else{ System.out.println("obj 可用"); } } }
结果:
CanReliveObj finalize called
obj 可用
第二次gc
obj 是 null
说明JVM不管程序员手动调用finalize,JVM它就是执行一次finalize方法。执行finalize方法完毕后,GC会再次进行二轮回收,去判断该对象是否可达,若不可达,才进行回收。
建议:避免使用finalize方法!
太复杂了,还是让系统照管比较好。可以定义其它的方法来释放非内存资源。建议使用try-catch-finally来替代它执行清理操作。
如果手动调用了finalize,很容易出错。且它执行的优先级低,何时被调用,不确定——也就是何时发生GC不确定,因为只有当内存告急时,GC才工作,即使GC工作,finalize方法也不一定得到执行,这是由于程序中的其他线程的优先级远远高于执行finalize()的线程优先级。 因此当finalize还没有被执行时,系统的其他资源,比如文件句柄、数据库连接池等已经消耗殆尽,造成系统崩溃。且垃圾回收和finalize方法的执行本身就是对系统资源的消耗,有可能造成程序的暂时停止,因此在程序中尽量避免使用finalize方法。
- Dump线程
- JVM的死锁检查
- 堆的Dump。
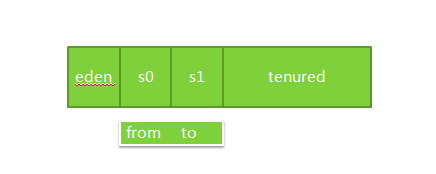
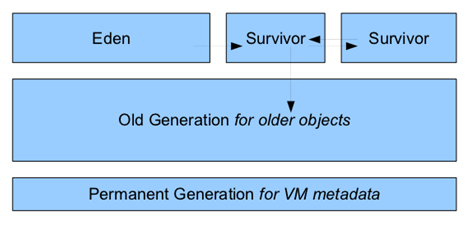
先不说了,先看看JVM的垃圾回收器吧,先看一种最古老的收集器——串行收集器
最古老,最稳定,效率高,但是串行的最大问题就是停顿时间很长!因为串行收集器只使用一个线程去回收,可能会产生较长的停顿现象。我们可以使用参数-XX:+UseSerialGC,设置新生代、老年代使用串行回收,此时新生代使用复制算法,老年代使用标记-压缩算法(标记-压缩算法首先需要从根节点开始,对所有可达对象做一次标记。但之后,它并不简单的清理未标记的对象,而是将所有的存活对象压缩到内存的一端。之后,清理边界外所有的空间。有效解决内存碎片问题)。
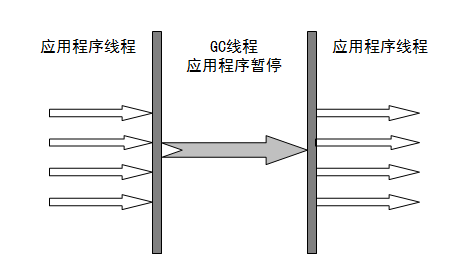
因为串行收集器只使用一个线程去回收,可能会产生较长的停顿现象。
还有一种收集器叫并行收集器(两种并行收集器)
- 一种是ParNew并行收集器。使用JVM参数设置XX:+UseParNewGC,设置之后,那么新生代就是并行回收,而老年代依然是串行回收,也就是并行回收器不会影响老年代,它是Serial收集器在新生代的并行版本,新生代并行依然使用复制算法,但是是多线程,需要多核支持,我们可以使用JVM参数: XX:ParallelGCThreads 去限制线程的数量。如图:
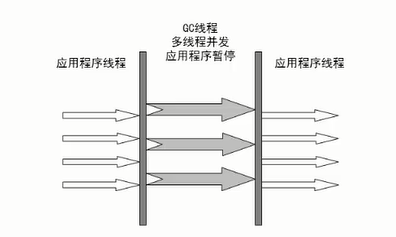
注意:新生代的多线程回收不一定快!看在多核还是单核,和具体环境。、
- 还有一种是Parallel收集器,它类似ParNew,但是更加关注JVM的吞吐量!同样是在新生代复制算法,老年代使用标记压缩算法,可以使用JVM参数XX:+UseParallelGC设置使用Parallel并行收集器+ 老年代串行,或者使用XX:+UseParallelOldGC,使用Parallel并行收集器+ 并行老年代。也就是说,Parallel收集器可以同时让新生代和老年代都并行收集。如图:
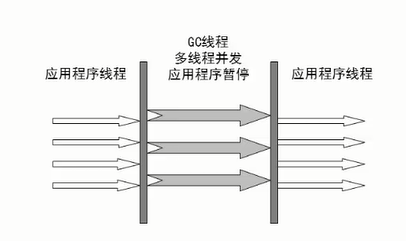
最后看一个很重要的收集器-CMS(并发标记清除收集器Concurrent Mark Sweep)收集器
顾名思义,它在老年代使用的是标记清除算法,而不是标记压缩算法,也就是说CMS是老年代收集器(新生代使用ParNew),所谓并发标记清除就是CMS与用户线程一起执行。标记-清除算法与标记-压缩相比,并发阶段会降低吞吐量,使用参数-XX:+UseConcMarkSweepGC打开。
CMS运行过程比较复杂,着重实现了标记的过程,可分为:
- 初始标记,标记GC ROOT 根可以直接关联到的对象(会产生全局停顿),但是初始标记速度快。
- 并发标记(和用户线程一起),主要的标记过程,标记了系统的全部的对象(不论垃圾不垃圾)。
- 重新标记,由于并发标记时,用户线程依然运行(可能产生新的对象),因此在正式清理前,再做一次修正,会产生全局停顿。
- 并发清除(和用户线程一起),基于标记结果,直接清理对象。这也是为什么使用标记清除算法的原因,因为清理对象的时候用户线程还能执行!标记压缩算法的压缩过程涉及到内存块移动,这样会有冲突。
- 并发重置,为下一次GC做准备工作。

- 在用户线程运行过程中,分一半CPU去做GC,系统性能在GC阶段,反应速度就下降一半。
- 清理不彻底。因为在清理阶段,用户线程还在运行,会产生新的垃圾,无法清理。
- 因为和用户线程基本上是一起运行的,故不能在空间快满时再清理。
可以使用-XX:CMSInitiatingOccupancyFraction设置触发CMS GC的阈值,设置空间内存占用到多少时,去触发GC,如果不幸内存预留空间不够,就会引起concurrent mode failure。
可以使用-XX:+ UseCMSCompactAtFullCollection, Full GC后,进行一次整理,而整理过程是独占的,会引起停顿时间变长。
从三个方面考虑:
- 软件如何设计架构
- 代码如何写
- 堆空间如何分配