分布式系统要做的任务就是把多台机器有机的组合、连接起来,让其协同完成一件任务,可以是计算任务,也可以是存储任务。如果一定要给近些年的分布式系统研究做一个分类的话,大概可以包括三大部分:
1. 分布式存储系统
2. 分布式计算系统
3. 分布式管理系统
这是一个范围比较广的话题,今天我们就来简单了解一下分布式存储系统的Gluserfs.
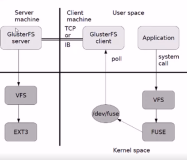
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。GlusterFS支持运行在任何标准IP网络上标准应用程序的标准客户端,用户可以在全局统一的命名空间中使用NFS/CIFS等标准协议来访问应用数据。GlusterFS使得用户可摆脱原有的独立、高成本的封闭存储系统,能够利用普通廉价的存储设备来部署可集中管理、横向扩展、虚拟化的存储池,存储容量可扩展至TB/PB级理论和实践上分析,GlusterFS目前主要适用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳。
官方文档: http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Quickstart/
glusterfs安装部署
我们在四台linux服务器上部署glusterfs,每台服务器上需要有一个用于挂载的外挂盘。
1、统一主机名,关闭selinux和防火墙。
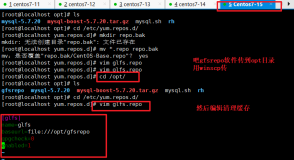
2、安装glusterfs
|
1
2
3
4
|
yum
install
–y centos-release-gluster37.noarch
yum --enablerepo=centos-gluster*-
test
install
glusterfs-server \
glusterfs-cli glusterfs-geo-replication glusterfs -y
/etc/init
.d
/glusterd
start
|
如果下载过程较慢,可以直接下载rpm包进行安装。
3、将存储主机(除本机之外的其他存储)加入信任存储池 (执行这一步后其他服务器也会自动生效)
|
1
2
3
|
gluster peer probe host2
gluster peer probe host3
gluster peer probe host4
|
4、查看存储连接状态
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# gluster peer status
Number of Peers: 3
Hostname: host2
Uuid: e8812107-a299-40a9-a5d2-c9983a5eec81
State: Peer
in
Cluster (Connected)
Hostname: host3
Uuid: 5782682d-05ce-48c1-9f14-13f1e99200a3
State: Peer
in
Cluster (Connected)
Hostname: host4
Uuid: a3370fd2-25ee-4ebf-9e61-6bed142afb58
State: Peer
in
Cluster (Connected)
|
5、格式化磁盘,安装xfs的支持包
|
1
2
3
4
5
6
7
8
9
10
|
yum -y
install
xfsprogs
fdisk
/dev/sdb
n
p
1
enter
w
# fdisk -l
Device Boot Start End Blocks Id System
/dev/sdb1
1 1305 10482381 83 Linux
|
6、格式化所有磁盘为xfs格式:
|
1
2
3
4
5
6
7
8
9
|
# mkfs.xfs -f /dev/sdb1
meta-data=
/dev/sdb1
isize=256 agcount=4, agsize=655149 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=2620595, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
|
7、在所有机器上建立挂载目录,并将磁盘挂载
|
1
2
3
|
# mkdir -p /storage/brick1
# mount /dev/sdb1 /storage/brick1
# df -h
|
GlusterFS的分类
gluster有几种不同的卷类型,分别适用于不同的生产场景,比较常用的有这样几种:
Distributed:分布式卷,文件通过hash算法随机的分布到由bricks组成的卷上,每个卷上存放的文件是完整的,不同的文件可能分布在不同的卷上,容量是各卷之和,节省磁盘空间。
Replicated:复制式卷,类似raid1,replica数必须等于volume中brick所包含的存储服务器数,可用性高,相当于有一个完整的镜像副本。
Striped:条带式卷,类似与raid0,stripe数必须等于volume中brick所包含的存储服务器数,文件被分成数据块,以Round Robin的方式存储在bricks中,并发粒度是数据块,大文件性能好
Distributed Striped:分布式的条带卷,volume中brick所包含的存储服务器数必须是stripe的倍数(>=2倍),兼顾分布式和条带式的功能。
Distributed Replicated:分布式的复制卷,volume中brick所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
对于具体各个卷的含义和理解可以参考:
http://blog.163.com/szy8706@yeah/blog/static/62713185201351510303223/
GlusterFS的操作
创建分布巻:(指定文件分布在两台机器上,默认是分布巻)
|
1
|
gluster volume create gv1 host1:
/storage/brick1
host2:
/storage/brick1
force
|
创建复制卷:
|
1
|
gluster volume create gv1 replica 2 host1:
/storage/brick2
host2:
/storage/brick2
force
|
创建分布式条带卷:(生产场景一般不用,这个目前还不太成熟,有丢失数据的风险)
|
1
|
gluster volume create gv1 stripe 2 host3:
/storage/brick1
host4:
/storage/brick1
force
|
创建分布式复制卷:(如果直接使用的是挂载点创建,需要加上force 参数)
|
1
|
gluster volume create gv1 replica 2 host1:
/storage/brick2
host2:
/storage/brick2
force
|
根据生产需要创建指定的卷之后,启动创建的卷:
|
1
|
gluster volume start gv1
|
查看创建卷的属性:
|
1
|
gluster volume info
|
挂载卷到目录,有两种挂载方式,
-
直接mount挂载:
|
1
|
mount
-t glusterfs 127.0.0.1:
/gv1
/mnt
|
显示方式:
|
1
2
|
df
-h
127.0.0.1:
/gv1
10G 33M 10G 1%
/mnt
|
-
NFS的方式挂载:
|
1
|
mount
-o mountproto=tcp -t nfs host3:
/gv1
/mnt/
|
显示方式:
|
1
2
|
df
-h
host3:
/gv1
10G 32M 10G 1%
/mnt
|
GlusterFS容量扩充和收缩
当有新的服务器需要加进来时,对glusterfs扩容使用 add-brick 命令:
|
1
|
gluster volume add-brick gv2 replica 2 host3:
/storage/brick2
host4:
/storage/brick2
force
|
gv2为已经存在的卷,将brick2的两个磁盘加入gv2
使用df -h 查看,发现gv2容量增大:
|
1
2
3
|
df
-h
/dev/sdb1
10G 33M 10G 1%
/storage/brick1
host13:
/gv2
20G 65M 20G 1%
/mnt
|
注意:当你给分布式复制卷和分布式条带卷中增加bricks时,你增加的bricks的数目必须是复制或者条带数目的倍数,例如:你给一个分布式复制卷的replica为2,你在增加bricks的时候数量必须为2、4、6、8等。
虽然已经新加入了磁盘,但是数据在存储的时候一般还会存储在之前旧的磁盘上,并不能均衡的写到新加入的磁盘中,造成磁盘的读写不均衡,这时就要对卷做磁盘存储平衡。
磁盘存储的平衡
平衡布局是很有必要的,因为布局结构是静态的,当新的bricks加入现有卷,新创建的文件会 分布到旧的bricks中,所以需要平衡布局结构,使新加入的bricks生效。布局平衡只是使新布局生效, 并不会在新的布局移动老的数据,如果你想在新布局生效后,重新平衡卷中的数据,还需要对卷中的数 据进行平衡。
执行数据布局平衡命令:
|
1
|
gluster volume rebalance gv2 start
|
查看平衡状态:
|
1
|
gluster volume rebalance gv2 status
|
此时可以看到数据已经平衡分布,在新加磁盘的服务器brick中已经有了数据。
移除brick
如果我们要想在线缩小卷的大小,例如:当硬件损坏或者网络故障的时候,你可能想在卷中移除相关的bricks。 注意:当你移除bricks的时候,你在 gluster的挂载点将不能继续访问数据,只有配置文件中的信息移除 后你才能继续访问bricks的数据。当移除分布式复制卷或者分布式条带卷的时候,移除的bricks数目必须 是replica或者stripe的倍数。例如:一个分布式条带卷的stripe是2,当你移除bricks的时候必须 是2、 4、6、8等。
操作命令:
停止卷:停止卷会使所有数据下线,不可连接
|
1
|
gluster volume stop gv2
|
移除brick:
|
1
|
gluster volume remove-brick gv2 replica 2 host3:
/storage/brick2
host4:
/storage/brick2
force
|
当移除的复制卷不是互为备份的brick时,会报错:
volume remove-brick commit force: failed: Bricks not from same subvol for replica
当移除brick成功后,就可以卸载磁盘取出修复了。
删除卷
如果想要删除卷,可以采用下面的命令:
移除挂载
|
1
2
3
4
|
umount
/mnt
gluster volume stop gv1
gluster volume delete gv1
gluster volume info gv1
|
存储池中移除服务器节点:
# gluster peer detach hostname
参考链接:http://www.zhihu.com/question/23645117/answer/124708083
本文转自 酥心糖 51CTO博客,原文链接:http://blog.51cto.com/tryingstuff/1862468