这个程序是使用python直接连接到“有道词典”的翻译页,然后实现对应翻译。
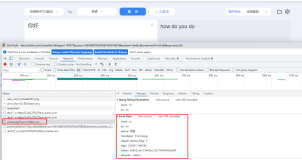
在有道字典的翻译页里,空白地方右键选择检查元素,然后输入一些可以翻译的语句,同时按下“翻译”的按键,观察network栏里的变化,发现有post有get,其中post主要是“发送到服务器”的数据,而get是“电脑接收”的数据。

从headers里获得了真正的翻译网址,以及远程地址。然后再往下看,我们能看见data,这个就是我们传上去的内容。

从这里能看出,我们上传的语句仅仅是“happy new year”,但是在服务器端却是这样的显示,所以在python里,我们也要按照这样的规格给服务器发送信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import
urllib.request
import
urllib.parse
import
json
#启动模块,json模块是因为data里的doctype是json,如果不选择这个的话,输出的格式很难看#
content
=
input
(
"想要翻译的英文:"
)
url
=
"http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=http://www.youdao.com/"
data
=
{}
#建立一个空的字典,然后一项一项的把字典内容填满#
data[
"type"
]
=
"AUTO"
data[
"i"
]
=
content
data[
"doctype"
]
=
"json"
data[
"xmlVersion"
]
=
"1.8"
data[
"keyfrom"
]
=
"fanyi.web"
data[
"ue"
]
=
"UTF-8"
data[
"action"
]
=
"FY_BY_CLICKBUTTON"
data[
"typoResult"
]
=
"true"
data
=
urllib.parse.urlencode(data).encode(
"utf-8"
)
#网站的编码是utf-8的模式,而我们传入的字典映射是默认python下的unicode模式,于是我们需要encode成utf-8,这样的data才是真正服务器可以识别的data#
response
=
urllib.request.urlopen(url,data)
#urlopen如果没有data那么它就是一个获取网页的命令,而有了data就是一个传送data到url的命令#
html
=
response.read().decode(
"utf-8"
)
#获得了服务器的应答之后,把服务器的utf-8的模式解码成python认可的unicode#
AAA
=
json.loads(html)
print
(
"翻译的结果是:"
+
AAA[
"translateResult"
][
0
][
0
][
"tgt"
])
|
本文转自 苏幕遮618 51CTO博客,原文链接:http://blog.51cto.com/chenx1242/1730633