信号捕捉trap
语法格式:
trap '这里写上需要执行的内容' 信号自定义进程收到系统发出的指定信号后,将执行触发指令,而不会执行原操作。
信号的表示方法:数字编号(1),全称(SIGHUP),简称(HUP)。更多信息请查看另外一篇《进程管理》
查看所有信号
#trap -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
常用控制信号方法:
trap '' 信号
忽略信号的操作
trap '-' 信号
恢复原信号的操作
trap -p
列出自定义信号操作
9) SIGKILL 不能被捕获示例
#!/bin/bash
#捕抓2信号,也就是 Ctrl + C
trap 'echo "`date +%F-%T`" ' 2
trap -p
for i in {1..10};do
echo $i
sleep 0.5
done运行结果
#bash trap.sh
trap -- 'echo "`date +%F-%T`" ' SIGINT
1
2
^C2018-01-01-11:53:17
3
4
5
^C2018-01-01-11:53:18
6
7
8
9
10
看到了吧,是支持命令嵌套的哦~,每次捕获到信号2的时候,就打印当时的时间
source sh bash ./ 执行脚本的区别
1、source
source 文件名
作用:在当前shell环境下读取并执行File中的命令。该file文件可以无"X执行权限"
该命令通常用命令“.”来替代。命令通常用于重新执行刚修改的配置文件
source 和 . 是bash shell的内置命令。
如:source .bash_profile 等效于 . .bash_profile2、sh和bash
sh 文件名
bash 文件名
作用:在当前shell环境下读取并执行File中的命令。该filen文件可以无"X执行权限"
两者在执行文件时的不同,是分别用自己的shell来跑文件。
/bin/sh
/bin/bash
bash是sh的增强版本,sh不仅不支持多种命令,而且很多细小的差别。
所以其实我们应该更多的使用bash。不过较新的版本默认已经把sh指向bash了
/bin/sh -> bash
bash -n 支持脚本语法检查
bash -x 支持脚本逐条语句的跟踪
3、./
./文件名
作用:打开一个子shell来读取并执行File中命令。运行一个shell脚本时会启动另一个命令解释器.
每个shell脚本有效地运行在父shell(parent shell)的一个子进程里.
shell脚本也可以启动他自已的子进程.
这些子shell(即子进程)使脚本并行有效率地同时运行脚本内的多个子任务.函数
函数function是由若干条shell命令组成的语句块,实现代码重用和模块化编程
它与shell程序形式上是相似的,不同的是它不是一个单独的进程,不能独立运行,而是shell程序的一部分
函数和shell程序比较相似,区别在于:
Shell程序在子Shell中运行
而Shell函数在当前Shell中运行。因此在当前Shell中,函数可以对shell中变量进行修改
定义函数
函数由两部分组成:函数名和函数体
函数名不可以与系统内部的关键字冲突,尽量有意义。系统中一些函数的命名方式为_fname ()。请参考
语法一:
函数名 (){
...函数体代码块...
}
语法二:
function 函数名 {
...函数体代码块...
}
语法三:
function 函数名 () {
...函数体代码块...
}示例
语法一:
f_echo () {
echo `hostname`
echo echo $LANG
}
语法二:
function f_echo {
echo `hostname`
echo echo $LANG
}
语法三:
function f_echo () {
echo `hostname`
echo echo $LANG
}
函数使用
可在交互式环境下定义函数
可将函数放在脚本文件中作为它的一部分
可放在只包含函数的单独文件中
系统本身就自带了一个定义函数的文件,可以去好好参考或调用
/etc/init.d/functions 调用:函数只有被调用才会执行调用:函数名出现的地方,
会被自动替换为函数代码
函数的生命周期:被调用时创建,返回时终止
在交互环境中使用函数
在当前shell中没有载入函数时:
#f_echo
-bash: f_echo: command not found
方法一:
直接在命令提示符后编写函数
#f_echo () {
> echo `hostname`
> echo $LANG
> }
#f_echo
centos7.hunk.teh
en_US.UTF-8
----------------------------
方法二:
在当前shell中载入函数文件时(与生效配置文件的操作一致):
#. 定义好的函数文件 或 source 定义好的函数文件
#f_echo
centos7.hunk.teh
en_US.UTF-8在脚本中定义及使用函数
函数在使用前必须定义,因此应将函数定义放在脚本开始部分,直至shell首次发现它后才能使用
调用函数仅使用其函数名即可
#!/bin/bash
#定义函数
f_echo () {
echo `hostname`
echo $LANG
}
#使用函数
f_echo
运行结果
#bash function.sh
centos7.hunk.teh
en_US.UTF-8使用函数文件
可以将经常使用的函数存入函数文件,然后将函数文件载入shell
文件名可任意选取,但最好与相关任务有某种联系。例如:functions.net
一旦函数文件载入shell,就可以在命令行或脚本中调用函数。可以使用set命令查看所有定义的函数,
其输出列表包括已经载入shell的所有函数
若要改动函数,首先用unset命令从shell中删除函数。改动完毕后,再重新载入此文件
函数文件已创建好后,要将它载入shell
定位函数文件并载入shell的格式:
. filename 或 source filename
注意:此即<点> <空格> <文件名>
这里的文件名要带正确路径
使用set命令检查函数是否已载入。 set命令将在shell中显示所有的载入函数
函数参数
传递参数给函数:调用函数时,在函数名后面以空白分隔给定参数列表即可;例如“ testfunc arg1 arg2 ...”
在函数体中当中,可使用$1, $2, ...调用这些参数;还可以使用$@, $*, $#等特殊变量
定义了一个函数文件
f_echo () {
#定义函数传参,-h 显示主机名
if [ "$1" = "-h" ];then
echo `hostname`
#定义函数传参,-l 显示本地语言
elif [ "$1" = "-l" ];then
echo $LANG
else
echo "没有指定函数参数"
fi
}
是不是有点像Linux命令的感觉?
#source function.sh
#f_echo -h
centos7.hunk.teh
#f_echo -l
en_US.UTF-8
#f_echo
没有指定函数参数
函数的生效范围
函数变量作用域:
环境变量:当前shell和子shell有效
声明:declare -xf function_name
export -f function_name
查看:declare -f 或 declare -F
#declare -f f_echo
f_echo ()
{
echo `hostname`;
echo $LANG
}
本地变量:只在当前shell进程有效,为执行脚本会启动专用子shell进程;
因此,本地变量的作用范围是当前shell脚本程序文件,包括脚本中的函数
局部变量:函数的生命周期;函数结束时变量被自动销毁,不可以被函数外引用
注意:如果函数中有局部变量,如果其名称同本地变量,使用局部变量
在函数中定义局部变量的方法
local NAME=VALUE函数变量作用域示例
代码:
#!/bin/bash
#定义本地变量
bar='本地变量值'
#函数1
_f_echo1 (){
#定义局部变量
local local='局部变量值'
echo "这个是在'_f_echo1'函数内部输出局部变量:$local"
echo "这个是在'_f_echo1'函数内部输出本地变量:$bar"
echo "这个是在'_f_echo1'函数内部输出环境变量:$env"
}
#函数2
_f_echo2 (){
echo "这个是在'_f_echo2'函数内部输出'_f_echo1'函数内部局部变量:$local"
echo "这个是在'_f_echo2'函数内部输出本地变量:$bar"
echo "这个是在'_f_echo2'函数内部输出环境变量:$env"
}
echo "这个是在脚本中输出'_f_echo1'函数中定义的局部变量:$local"
echo "这个是在脚本中输出本地变量:$bar"
echo "这个是在脚本中输出环境变量:$env"
echo "下面输出函数_f_echo1的结果"
_f_echo1
echo "-----------------------------------"
echo "下面输出函数_f_echo2的结果"
_f_echo2
#declare -x env='这是环境变量值'
注意了,这里使用的是bash 脚本文件 的方式运行,也就是在当前shell环境
#bash localfunc.sh
这个是在脚本中输出'_f_echo1'函数中定义的局部变量:(无值)
这个是在脚本中输出本地变量:(有值) 本地变量值
这个是在脚本中输出环境变量:(有值) 这是环境变量值
下面输出函数_f_echo1的结果
这个是在'_f_echo1'函数内部输出局部变量:(有值)局部变量值
这个是在'_f_echo1'函数内部输出本地变量:(有值)本地变量值
这个是在'_f_echo1'函数内部输出环境变量:(有值)这是环境变量值
-----------------------------------
下面输出函数_f_echo2的结果
这个是在'_f_echo2'函数内部输出'_f_echo1'函数内部局部变量:(无值)
这个是在'_f_echo2'函数内部输出本地变量:(有值)本地变量值
这个是在'_f_echo2'函数内部输出环境变量:(有值)这是环境变量值
-------------------------华丽的分割线--------------------------------------------------
#declare -x env='这是环境变量值'
注意了,这里使用的 ./脚本文件 的方式运行,也就是在子shell环境
#./localfunc.sh
这个是在脚本中输出'_f_echo1'函数中定义的局部变量:(无值)
这个是在脚本中输出本地变量:(有值) 本地变量值
这个是在脚本中输出环境变量:(有值) 这是环境变量值
下面输出函数_f_echo1的结果
这个是在'_f_echo1'函数内部输出局部变量:(有值)局部变量值
这个是在'_f_echo1'函数内部输出本地变量:(有值)本地变量值
这个是在'_f_echo1'函数内部输出环境变量:(有值)这是环境变量值
-----------------------------------
下面输出函数_f_echo2的结果
这个是在'_f_echo2'函数内部输出'_f_echo1'函数内部局部变量:(无值)
这个是在'_f_echo2'函数内部输出本地变量:(有值)本地变量值
这个是在'_f_echo2'函数内部输出环境变量:(有值)这是环境变量值
函数递归
函数直接或间接调用自身
注意递归层数
fork×××是一种恶意程序,它的内部是一个不断在fork进程的无限循环,实质是一个
简单的递归程序。由于程序是递归的,如果没有任何限制,这会导致这个简单的程序迅速耗尽系统里面的所有资源
函数实现
:(){ :|:& };:
这里是用 : 作为函数名,换成易懂的写法如下:
bomb() { bomb | bomb & };bomb
定义函数,函数体内是调用函数本身,通过子shell本身通过管道再开一个子shell传给子shell中,而且是并发执行。
脚本实现
#!/bin/bash
./$0 | ./$0 &
先在子shell中执行程序本身,再把本身通过管道再开一个子shell传给子shell中,而且是并发执行。
函数返回值
函数有两种返回值:
函数的执行结果返回值:
(1) 使用echo等命令进行输出
(2) 函数体中调用命令的输出结果
函数的退出状态码:
(1) 默认取决于函数中执行的最后一条命令的退出状态码
(2) 自定义退出状态码,其格式为:
return 从函数中返回(退出当前函数),用最后状态命令决定返回值
return 0 无错误返回。
return 1-255 有错误返回
以下为演示:
f_echo () {
#定义函数传参,-h 显示主机名
if [ "$1" = "-h" ];then
echo `hostname`
echo "没有return,这条指令有输出,并继续判断下面"
#定义函数传参,-l 显示本地语言
elif [ "$1" = "-l" ];then
echo $LANG
return 10
echo "只要看到return,这条指令就不会有输出"
else
echo "没有指定函数参数"
return 20
fi
}
运行结果:
#f_echo -h
centos7.hunk.teh
没有return,这条指令有输出,并继续判断下面
#f_echo -l
en_US.UTF-8
#f_echo -a
没有指定函数参数
#echo $?
20
取消函数
方法一:
#unset 函数名
方法二:
退出当前shell实例:
实现系统中如下的功能,打印带颜色的服务提示
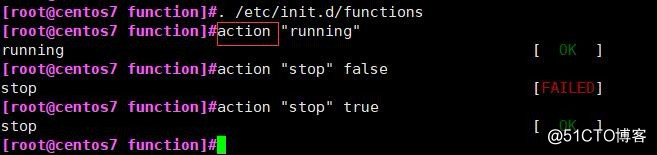
#. /etc/init.d/functions
调用系统内定义好的函数文件,里面的action的用法如下:
action "显示的字符串" 省略 或 true 或 false
省略 或 true 绿色的 OK
false 红色的FAILED
下面第5-6个练习有案例
练习:
1、编写函数,实现OS的版本判断
#only functions code
f_osversion (){
local osversion
osversion=`rpm -q centos-release|sed -r 's/^.*release-([0-9]+).*$/\1/g'`
echo "当前操作系统版本为:Centos $osversion 系列"
}
运行结果
#f_osversion
当前操作系统版本为:Centos 7 系列
#f_osversion
当前操作系统版本为:Centos 6 系列
以下方法都能取得系统版本号,但是,有些管理员会把这些文件删除或修改,因此,上面的方法可能靠谱一些。
cat /etc/centos-release
cat /etc/issue
cat /etc/issue.net2、编写函数,实现取出当前系统网卡的IP地址
#only functions code
f_getip (){
local ip
ip=`ip addr |sed -rn '/ens[0-9]+$|eth[0-9]+$/p'|awk '{print $2}'`
echo -e "当前操作系统所有的网卡IP地址为:\n$ip"
}
运行结果
#f_getip
当前操作系统所有的网卡IP地址为:
192.168.4.101/24
172.18.101.101/16
Centos 6 默认的网卡名为eth*
Centos 7 默认的网卡名为ens*
我之前的的网络章节有介绍
3、编写函数,实现打印绿色OK和红色FAILED
f_green (){
echo -e "\e[1;32mOK\e[0m"
}
f_red (){
echo -e "\e[1;31mFAILED\e[0m"
}<html>
#f_green<font color="#66CD00">OK</font>
#f_red
<font color="#FF0000">FAILED</font>
</html>
4、编写函数,实现判断是否无位置参数,如无参数,提示错误
f_argcheck (){
[ $# -eq 0 ] && echo "Error.no arguments." && return 10
}
运行结果
#source checkfunc.sh
#f_argcheck
Error.no arguments.
#echo $?
10
5、编写服务脚本/root/bin/testsrv.sh,完成如下要求:
(1) 脚本可接受参数:start, stop, restart, status
(2) 如果参数非此四者之一,提示使用格式后报错退出
(3) 如是start:则创建/var/lock/subsys/SCRIPT_NAME,
并显示“服务启动成功”。考虑:如果事先已经启动过一次,该如何处理?
(4) 如是stop:则删除/var/lock/subsys/SCRIPT_NAME, 并显示“服务停止完成”
考虑:如果事先已然停止过了,该如何处理?
(5) 如是restart,则先stop, 再start>考虑:如果本来没有start,如何处理?
(6) 如是status, 则如果/var/lock/subsys/SCRIPT_NAME文件存在,则显示“ 服务运行中...”
如果/var/lock/subsys/SCRIPT_NAME文件不存在,则显示“ 服务已停止...”
其中:SCRIPT_NAME为当前脚本名
(7)在所有模式下禁止启动该服务,可用chkconfig 和 service命令管理
#!/bin/bash
##以下的一行为服务可以使用 chkconfig 和 service命令管理,必须存在
# chkconfig: 35 99 00
# Source function library.
. /etc/rc.d/init.d/functions
#服务启动创建的文件
_sockfile="/var/lock/subsys/testsrv"
#服务各种状态显示彩色文本,调用了系统内置的action函数
f_text_colore (){
[ "$1" = "run_color" ] && echo -ne "\\033[1;5;32m服务运行中...\\033[0m" && return 0
[ "$1" = "stop_color" ] && echo -ne "\\033[1;33m服务已停止\\033[0m" && action && return 0
[ "$1" = "start_color" ] && echo -ne "\\e[1;32m服务启动成功\\033[0m" && action
}
#服务状态查看
f_status (){
if [ -e $_sockfile ];then
f_text_colore run_color
else
f_text_colore stop_color
fi
}
#停止服务
f_stop (){
#停止时删除服务启动时创建的文件
if [ -e $_sockfile ];then
\rm "$_sockfile"
f_text_colore stop_color
else
f_text_colore stop_color
fi
}
#启动服务
f_start (){
if [ -e $_sockfile ];then
f_text_colore run_color
else
touch "$_sockfile"
f_text_colore start_color
fi
}
#重启服务
f_restart (){
if [ -e $_sockfile ];then
f_stop
f_start
else
f_start
fi
}
#本服务指令选择
case $1 in
start)
f_start
;;
stop)
f_stop
;;
restart)
f_restart
;;
status)
f_status
;;
*)
echo "Usage: testsrv start | stop | restart | status "
;;
esac运行结果
以下操作在Centos 6测试成功
1.复制脚本至/etc/init.d
# cp testsrv /etc/init.d/
2.添加至服务列表
# chkconfig --add testsrv
3.测试,实际中有颜色并且特定状态闪烁。
#service testsrv status
服务运行中...
#service testsrv stop
服务已停 [ OK ]
#service testsrv start
服务启动成功 [ OK ]
重启系统,也能正常的看到。可以查看/var/log/boot.log
服务启动成功 [ OK ]
6、编写脚本/root/bin/copycmd.sh
(1) 提示用户输入一个可执行命令名称
(2) 获取此命令所依赖到的所有库文件列表
(3) 复制命令至某目标目录(例如/mnt/sysroot)下的对应路径下
如:/bin/bash ==> /mnt/sysroot/bin/bash
/usr/bin/passwd ==> /mnt/sysroot/usr/bin/passwd
(4) 复制此命令依赖到的所有库文件至目标目录下的对应路径下:
如:/lib64/ld-linux-x86-64.so.2 ==>/mnt/sysroot/lib64/ld-linux-x86-64.so.2
(5)每次复制完成一个命令后,不要退出,而是提示用户键入新的要复制的命令,并重复完成上述功能;直到用户输入quit退出
#/bin/bash
# Source function library.
. /etc/rc.d/init.d/functions
#定义函数 复制命令
f_cpcmd (){
#正确的外部命令赋值给变量cmd
cmd=`which $inputcmd`
#取出命令的目录名赋值给dscdir
cmddscdir=$cmdpath`dirname $cmd`
#创建与命令一致的目录到指定目录下
mkdir -p $cmddscdir
#复制
\cp $cmd $cmddscdir && echo -en "复制 \033[1;31m$cmd\033[0m 至 $cmddscdir" && action ""
}
#定义函数 复制lib文件
f_cplib (){
#取出复制命令所使用的库文件
libpath=`ldd $cmd|egrep -o "/[^[:blank:]]+"`
#循环
for i in $libpath;do
#取出库文件的目录名
libdir=`dirname $i`
#如果库文件目录不存在,就创建
[ ! -e $cmdpath$libdir ] && mkdir -p $cmdpath$libdir
#复制
\cp $i $cmdpath$libdir && echo -en "复制 \033[1;31m$i\033[0m 至 $cmdpath$libdir" && action ""
done
}
#复制目标目录
cmdpath='/tmp/commands'
echo -e "\033[1;36m本脚本将会把命令打包至$cmdpath\033[0m"
#循环退出条件,用户输入quit
while true;do
read -p "请输入一个需要复制的命令 或 < quit | q > 退出:" inputcmd
[[ "$inputcmd" =~ quit|q ]] && exit
#判断是不是内部命令
if [ "`type -t $inputcmd`" = "builtin" ];then
echo -e "\033[1;35m这是内部命令,请输入\033[0m \033[1;31mbash\033[0m 复制" && continue
#判断返回值为空就是不存在的命令
elif [ "`type -t $inputcmd`" = "" ];then
echo -e "\033[1;5;31m命令不存在\033[0m" && continue
else
f_cpcmd
f_cplib
fi
done运行结果
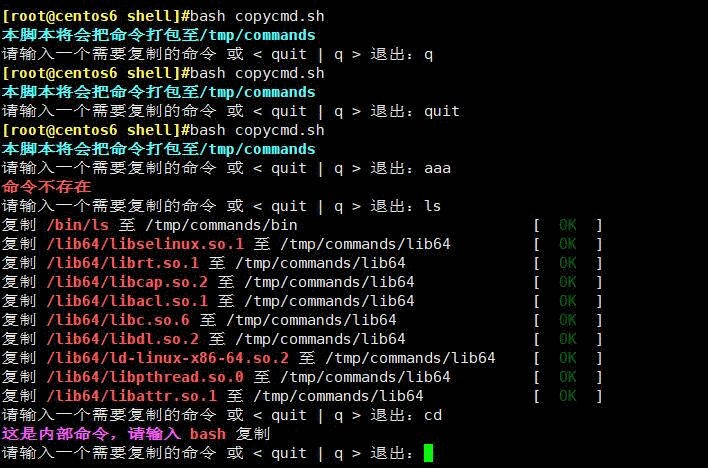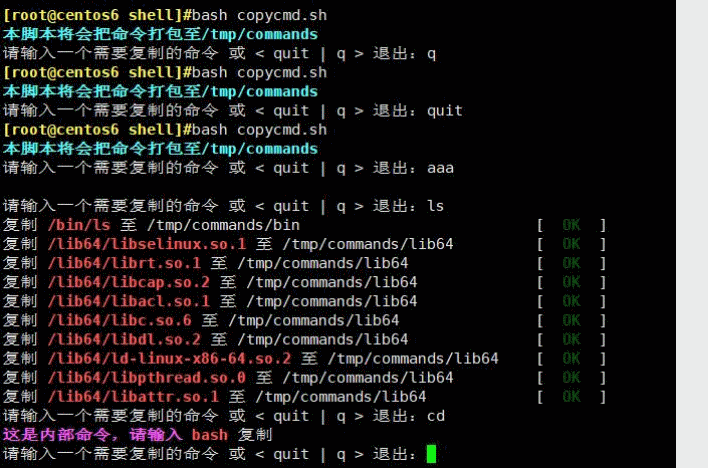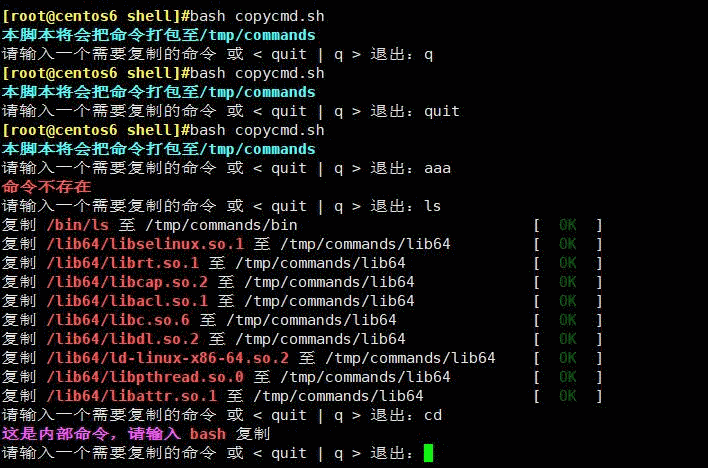
#bash copycmd.sh
本脚本将会把命令打包至/tmp/commands
请输入一个需要复制的命令 或 < quit | q > 退出:q
#bash copycmd.sh
本脚本将会把命令打包至/tmp/commands
请输入一个需要复制的命令 或 < quit | q > 退出:quit
#bash copycmd.sh
本脚本将会把命令打包至/tmp/commands
请输入一个需要复制的命令 或 < quit | q > 退出:aaa
命令不存在
请输入一个需要复制的命令 或 < quit | q > 退出:ls
复制 /bin/ls 至 /tmp/commands/bin [ OK ]
复制 /lib64/libselinux.so.1 至 /tmp/commands/lib64 [ OK ]
复制 /lib64/librt.so.1 至 /tmp/commands/lib64 [ OK ]
复制 /lib64/libcap.so.2 至 /tmp/commands/lib64 [ OK ]
复制 /lib64/libacl.so.1 至 /tmp/commands/lib64 [ OK ]
复制 /lib64/libc.so.6 至 /tmp/commands/lib64 [ OK ]
复制 /lib64/libdl.so.2 至 /tmp/commands/lib64 [ OK ]
复制 /lib64/ld-linux-x86-64.so.2 至 /tmp/commands/lib64 [ OK ]
复制 /lib64/libpthread.so.0 至 /tmp/commands/lib64 [ OK ]
复制 /lib64/libattr.so.1 至 /tmp/commands/lib64 [ OK ]
请输入一个需要复制的命令 或 < quit | q > 退出:cd
这是内部命令,请输入 bash 复制
7、编写函数实现两个数字做为参数,返回最大值
#!/bin/bash
f_compare (){
local max
if [ "$1" -lt "$2" ];then
max=$2
echo $max
else
max=$1
echo $max
fi
}数组
变量:存储单个元素的内存空间
数组:存储多个元素的连续的内存空间,相当于多个变量的集合
数组名和索引
索引:编号从0开始,属于数值索引。最后一个就是N-1
注意:索引可支持使用自定义的格式,而不仅是数值格式,即为关联索引,bash4.0版本之后开始支持
bash的数组支持稀疏格式(索引不连续)声明数组:
declare -a 数组名
关联数组
declare -A 数组名
注意:两者不可相互转换数组元素的赋值
(1) 一次只赋值一个元素
格式:
ARRAY_NAME[INDEX]=VALUE
例:
name[0]="zhang"
name[1]="wang"
(2) 一次赋值全部元素
格式:
ARRAY_NAME=("VAL1" "VAL2" "VAL3" ...)
例:
num=("01" "02" "03")
只要能产生列表的方式就可以生成数组
dir=(`ls -d /*`)
declare -a dir='([0]="/app" [1]="/bin" [2]="/boot" [3]="/dev" [4]="/etc")'
(3) 只赋值特定元素
格式:
ARRAY_NAME=([0]="VAL1" [3]="VAL2" ...)
例:
year=([0]"2017" [2]="2018")
(4) 交互式数组值对赋值
read -a ARRAY使用数组
显示所有数组:declare -a
#declare -a
declare -a year='([0]="[0]2017" [2]="2018")'
引用数组元素:
${ARRAY_NAME[INDEX]}
注意:省略[INDEX]表示引用下标为0的元素
#echo ${year[0]}
[0]2017
#echo ${year}
[0]2017
引用数组所有元素:
${ARRAY_NAME[*]}
${ARRAY_NAME[@]}
数组的长度(数组中元素的个数):
${#数组名[*]}
${#数组名[@]}
表示取下标
${!数组名[@]}
#echo ${#year[@]}
2
#echo ${#year[*]}
2
#echo ${#year[1]}
0
以下是显示某个元素的值长度
#echo ${#year[2]}
4
#echo ${name[0]}
zhang
#echo ${num[0]} ${num[2]}
01 03删除数组和删除数组上某个元素
删除数组中的某元素:导致稀疏格式
unset year[0]
删除整个数组:
unset year数组数据处理
引用数组中的元素:
语法:
数组切片:${数组名[@]:offset:number}
offset: 要跳过的元素个数
number: 要取出的元素个数
#num=({1..10})
echo ${num[*]}
1 2 3 4 5 6 7 8 9 10
#echo ${num[*]:3:4}
4 5 6 7
取偏移量之后的所有元素
${数组名[@]:offset}
#echo ${num[*]:3}
4 5 6 7 8 9 10
修改数组中元素值:
语法:
数组名[${#数组名[*]}]=值
num[${#num[*]}]=11
如果下标不存在,则新增数组元素; 下标已有,则覆盖值
输出原数组
#echo ${list[*]}
A B C D apple ufo cto car
#echo ${!list[*]}
0 1 2 3 4 5 6 7
下标已有,则覆盖值
#list[7]="num7"
#echo ${list[*]}
A B C D apple ufo cto num7
#echo ${!list[*]}
0 1 2 3 4 5 6 7
下标不存在,则新增
#list[8]="num8"
#echo ${list[*]}
A B C D apple ufo cto num7 num8
取出数组下标
#echo ${!list[*]}
0 1 2 3 4 5 6 7 8
列出数组中的所有值
#echo ${list[*]}
A B C D apple ufo cto num7 num8
把list数组中num7替换为num77后赋值给新数组(自动新增)list
#list2=(${list[*]/num7/num77})
#declare -a
declare -a list='([0]="A" [1]="B" [2]="C" [3]="D" [4]="apple" [5]="ufo" [6]="cto" [7]="num7" [8]="num8")'
declare -a list2='([0]="A" [1]="B" [2]="C" [3]="D" [4]="apple" [5]="ufo" [6]="cto" [7]="num77" [8]="num8")'
更多的字符串操作,请参考Shell 编程进阶(四)
关联数组:
declare -A ARRAY_NAME
ARRAY_NAME=([idx_name1]='val1' [idx_name2]='val2‘...)
注意:关联数组必须先声明再调用
本章节最后有一个实例是使用关联数组的。练习
1、生成10个随机数保存于数组中,并找出其最大值和最小值
#!/bin/bash
#清空数组
unset rand
#声明数组
declare -a rand
#声明变量类型
declare -i max
declare -i min
max=0
#生成10个随机数并循环赋值给rand[?]
for i in {0..10};do
rand[$i]=$RANDOM
if [ "$i" -eq 0 ];then
#第一个随机数赋值给min
min=${rand[$i]}
elif [ "${rand[$i]}" -lt "$min" ];then
min=${rand[$i]}
elif [ "${rand[$i]}" -gt "$max" ];then
max=${rand[$i]}
fi
done
echo "生成的10个随机数为:${rand[*]}
最小的随机数为:$min
最大随随机数为:$max"运行结果
#bash arry.sh
生成的10个随机数为:6220 9928 19019 6816 13082 29020 2286 31592 1305 20511 17654
最小的随机数为:1305
最大随随机数为:315922、编写脚本,定义一个数组,数组中的元素是/var/log目录下所有以.log结尾的文件;统计出其下标为偶数的文件中的行数之和
方法一:
#!/bin/bash
#声明了一个数组并赋值,元素为/var/log/*.log
declare -a sumlog=(/var/log/*.log)
line=0
echo -e "数组sumlog中的所有元素为:\n`declare -a|grep "log="|awk -F "[()]" '{print $2}'`"
#总的循环次数等于 数组的总个数-1,也就是下标的编号值。比如10个元素,那就是10-1=9,因为下标是从0-9编号的
for i in `seq 0 $[${#sumlog[*]}-1]`;do
#对$i进行取模运算,结果为0则为偶数。至于0这个数,自己看情况处理。
if [ "$[$i%2]" -eq 0 ];then
echo "需要统计的文件是:${sumlog[$i]} = `wc -l ${sumlog[$i]}|cut -d' ' -f1` 行"
#统计出每个偶数下标文件中的行数再逐个相加赋值给$line
line=$[$line+`wc -l ${sumlog[$i]}|cut -d' ' -f1`]
fi
done
echo "数组sumlog 中下标为偶数的文件中的行数之和为:$line"运行结果
#bash arry-log.sh
数组sumlog中的所有元素为:
[0]="/var/log/anaconda.ifcfg.log"
[1]="/var/log/anaconda.log"
[2]="/var/log/anaconda.program.log"
[3]="/var/log/anaconda.storage.log"
[4]="/var/log/anaconda.yum.log"
[5]="/var/log/boot.log"
[6]="/var/log/dracut.log"
[7]="/var/log/yum.log"
需要统计的文件是:/var/log/anaconda.ifcfg.log = 219 行
需要统计的文件是:/var/log/anaconda.program.log = 991 行
需要统计的文件是:/var/log/anaconda.yum.log = 612 行
需要统计的文件是:/var/log/dracut.log = 2015 行
数组sumlog 中下标为偶数的文件中的行数之和为:3837
方法二:
#!/bin/bash
#声明了一个数组并赋值,元素为/var/log/*.log
declare -a sumlog=(/var/log/*.log)
line=0
echo -e "数组sumlog中的所有元素为:\n`declare -p sumlog`"
#遍历数组下标并比较
for i in `echo ${!sumlog[*]}`;do
if [ "$[$i%2]" -eq 0 ];then
echo "需要统计的文件是:${sumlog[$i]} = `wc -l ${sumlog[$i]}|cut -d' ' -f1` 行"
#统计出每个偶数下标文件中的行数再逐个相加赋值给$line
line=$[$line+`wc -l ${sumlog[$i]}|cut -d' ' -f1`]
fi
done
echo "数组sumlog 中下标为偶数的文件中的行数之和为:$line"运行结果
#bash arry-log2.sh
数组sumlog中的所有元素为:
declare -a sumlog='(
[0]="/var/log/anaconda.ifcfg.log"
[1]="/var/log/anaconda.log"
[2]="/var/log/anaconda.program.log"
[3]="/var/log/anaconda.storage.log"
[4]="/var/log/anaconda.yum.log"
[5]="/var/log/boot.log"
[6]="/var/log/dracut.log"
[7]="/var/log/yum.log")'
需要统计的文件是:/var/log/anaconda.ifcfg.log = 219 行
需要统计的文件是:/var/log/anaconda.program.log = 991 行
需要统计的文件是:/var/log/anaconda.yum.log = 612 行
需要统计的文件是:/var/log/dracut.log = 2015 行
数组sumlog 中下标为偶数的文件中的行数之和为:38373、获取指定元素的下标值
1.定义了一个函数
f_get_arr_idx(){
if [ $# -lt 2 -o $# -gt 2 ];then
echo "必须且只能输入2个参数,语法:f_get_arr_idx 数组名 元素值"
return 10
#判断 $1 不是数组就退出脚本
elif [ "`declare -p $1 &> /dev/null;echo $?`" -ne 0 ];then
echo $1 不是数组
return 20
##判断 $2 是数组就退出脚本
elif [ "`declare -p $2 &> /dev/null;echo $?`" -eq 0 ];then
echo $2 是数组
return 30
fi
#声明局部变量为$1,也就是数组名
local arry_name="$1"
#声明局部变量为$2,也就是需要查询的元素值
local arry_item="$2"
#遍历数组下标并比较元素值,eval的用法,请查看另外一篇
for i in `eval echo \$\{!$1[@]\}`;do
if [ "$2" = "`eval echo \$\{$1[$i]\}`" ];then
echo "所查询的元素 $2 的下标值是:$i"
#如果找到,直接退出函数
return
else
#如果没有找到,继续下轮循环
continue
fi
done
echo "$2 没找到对应的下标"
}
2.载入函数
# source get_array_func
3.声明一个测试用的数组
#declare -a list=( A B C D apple ufo cto car )
运行结果
declare -a list='([0]="A" [1]="B" [2]="C" [3]="D" [4]="apple" [5]="ufo" [6]="cto" [7]="car")'
#f_get_arr_idx
必须输入2个参数,语法:f_get_arr_idx 数组名 元素值
#f_get_arr_idx array list
list 是数组
#f_get_arr_idx list cto
所查询的元素 cto 的下标值是:6
#f_get_arr_idx list D
所查询的元素 D 的下标值是:3
#f_get_arr_idx list oye
oye 没找到对应的下标
4、输入若干个数值存入数组中,采用冒泡算法进行升序或降序排序
#!/bin/bash
#声明一个数组
read -a num -p "请输入正整数:"
#判断所有的数字是否为数字
for input in ${num[*]};do
if [[ "$input" =~ ^[0-9]+$ ]];then
continue
else
echo "$input 不是数字,脚本退出"
exit
fi
done
#取得数组元素总个数
arrtop=${#num[*]}
echo "输入的信息为:${num[*]}"
echo "数组一共有 $arrtop 个元素"
echo $menu
#定义升序的函数
f_asc () {
for i in `seq 0 $[arrtop-1]`;do
for j in `seq 0 $[$i-1]`;do
if [ "${num[$i]}" -lt "${num[$j]}" ];then
tmp=${num[$i]}
num[$i]=${num[$j]}
num[$j]=$tmp
fi
done
done
echo -e "升序排序结果\n\e[1;34m${num[*]}\e[0m"
}
#定义降序的函数
f_desc () {
for i in `seq 0 $[arrtop-1]`;do
for j in `seq 0 $[$i-1]`;do
if [ "${num[$i]}" -gt "${num[$j]}" ];then
tmp=${num[$i]}
num[$i]=${num[$j]}
num[$j]=$tmp
fi
done
done
echo -e "降序排序结果\n\e[1;34m${num[*]}\e[0m"
}
#定义PS3输出信息
PS3='请选择排序方法:asc=升序 desc=倒序 _> '
#选择排序方法
select menu in asc desc quit;do
if [ "$menu" = "asc" ];then
f_asc
elif [ "$menu" = "desc" ];then
f_desc
else
echo "你选择了quit,退出脚本"
exit 10
fi
done运行结果
#bash maopao.sh
请输入正整数:10 0 a 3 b
a 不是数字,脚本退出
#bash maopao.sh
请输入正整数:12 23 495 8372 1000 2000 2018
输入的信息为:12 23 495 8372 1000 2000 2018
数组一共有 7 个元素
1) asc
2) desc
3) quit
请选择排序方法:asc=升序 desc=倒序 _> 1
升序排序结果
12 23 495 1000 2000 2018 8372
请选择排序方法:asc=升序 desc=倒序 _> 2
降序排序结果
8372 2018 2000 1000 495 23 12
请选择排序方法:asc=升序 desc=倒序 _> 3
你选择了quit,退出脚本
5、将下图所示,实现转置矩阵matrix.sh
1 2 3 1 4 7
4 5 6 ===> 2 5 8
7 8 9 3 6 9
要点:
是围绕着轴线159进行两边数字对调的,同时,只要是行号=列号时,数字不会变动。这条就是轴线。
观察原矩阵,发现变化的就只有2<>4 3<>7 6<>8对调
使用关联数组的方式把对应的行列号形成座标。
如果以11 代表第1行第1列,5的位置就是22,9的位置就是33。如下显示
11 12 13
21 22 23
31 32 33
仔细观察用座标表示的位置,会发现:就得出一条公式:
当列号大于行号时,就转换。
当列号等于行号时,不用转换。
比如:
4的座标是12,拆开来看,列的数字2>行的数字1,那么根据公式转换,
新的座标就是21,刚好与数字2的座标是一致的。
因此,只要此2个数字对应的数组下标值对调值即可。
#!/bin/bash
#定义了矩形大小
size=3
#根据规则,定义出各个数字的下标,并赋值给数组
declare -A matrix=( [11]=1 [12]=2 [13]=3 [21]=4 [22]=5 [23]=6 [31]=7 [32]=8 [33]=9 )
#定义函数,打印数组矩形
f_print_arrty (){
local line
local column
for ((line=0;line<size;line++));do
for ((column=0;column<size;column++));do
echo -n "${matrix[$line$column]} "
done
echo
done
}
#定义函数 数组转换
f_conver_arrty(){
local line
local column
for ((line=0;line<size;line++));do
for ((column=0;column<size;column++));do
#当列号等于行号时,不用转换,直接跳过此次循环
if [ "$line" -eq "$column" ];then
continue
#当列号大于行号时,就转换,对应的2个数组值对调,需要用到第三个临时变量tmp
elif [ "$column" -gt "$line" ];then
tmp=${matrix[$line$column]}
matrix[$line$column]=${matrix[$column$line]}
matrix[$column$line]=$tmp
fi
done
echo
done
}
#打印转换前数组矩形
f_print_arrty
echo "
HH
HH
\HH/
\/
"
#进行数组转换
f_conver_arrty
#打印转换后数组矩形
f_print_arrty
运行结果
#bash matrix.sh
1 2 3
4 5 6
7 8 9
HH
HH
\HH/
\/
1 4 7
2 5 8
3 6 9
for ((line=0;line<size;line++));do
for ((column=0;column<size;column++));do
以上代码可以更换为
for line in `seq $size`;do
for column in `seq $size`;do
不过呢,效率上反而慢了,毕竟了多使用了一个命令。相差了0.004s
在循环条件不确定的时候,可以考虑下学习后果然让自己知道如何shell编程,劳动成果。转载请保留链接。








