前沿
最近项目要使用新的架构,后端数据库要使用Mycat中间件来实现,但是无没接触过啊,没接触过,那怎么办,卧薪藏胆来搞呗。。 接住这个bug,然后修改。
环境介绍
之前项目用的mysql是主从的架构,但是这样的架构有一些弊端:
- 主从同步总是出现问题
- 读写的压力全部积压到了master机器上了,导致系统出现瓶颈
- 系统扩容不是灵活
综上所述,故而决定使用mysql中间库Mycat
拓扑架构
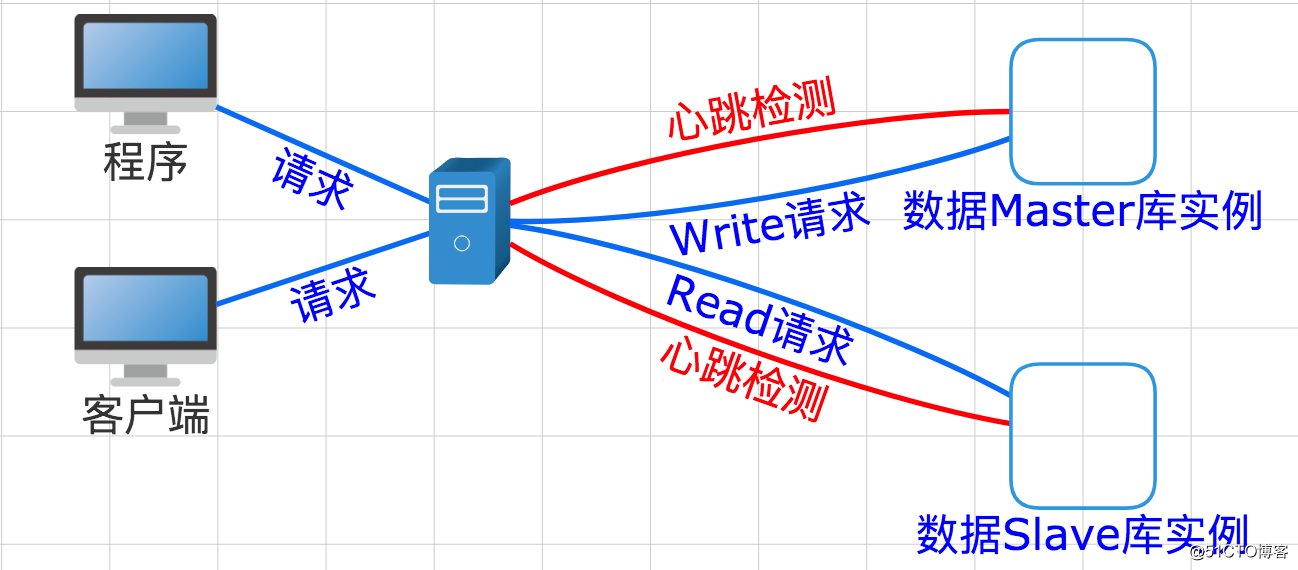
系统环境介绍
| MyCat | Mysql-Master | Mysql-slave |
|---|---|---|
| 192.168.1.186 | 192.168.1.186 | 192.168.1.202 |
| Ubuntu14.04 | Ubuntu14.04 | Ubuntu14.04 |
| MyCat 1.6 | Mysql 5.5 | Mysql 5.5 |
系统安装
1.Mysql主从安装
配置MySql主从就不在说明发,因为我们架构中对mysql的切换要求是当Master down机后Slave不在支持写功能,依旧当做Slave使用,并且提供myslq Read服务。所有要禁止slave的Write功能。
关于主从要说一下几点:
设置slave只读有如下几句语法:
* show global variables like "%read_only%"; #查看当前数据库对写的状态,OFF--->允许读写;ON--->只允许读
* flush tables with read lock; #全局表锁定,所有的用户对所有的表禁止写(包括有用super权限的用户)
* set global read_only=1; #只读权限开关,1为开、0为关因为开启了全局锁表所有的用户对数据库都不能进行写的操作,故而我们只能设置写权限的开关,即 set global read_only=1;
因为只关闭了普通用户的写权限,所以我们在给前端用户分发库权限的时候,一定要针对某个库分配权限,不要使用.的模式进行权限分发。
2.下载Mycat
下载地址:http://mycat.io/ 笔者写文章的时候,最新版本为1.6
3.安装Mycat
安装Mycat很容易,只需要解压,然后把解压的目录指定到$PATH全局环境变量中即可。
4.配置文件讲解
Schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 逻辑库配置 -->
<!--
name : 设计逻辑库名称,可以不与实际库对应,他对应的物理哭是dataNode标签中配置的database的库。
checkSQLschema :当该值设置为 true 时,如果我们执行语句(select * from USERDB.eg_user)则 MyCat 会把语句修改为(select * from eg_user)。即把表示 schema 的字符去掉,避免发送到后端数据
库执行时报**(ERROR1146 (42S02): Table ‘ USERDB.eg_user’ doesn’ t exist)。
不过,即使设置该值为 true ,如果语句所带的是并非是 schema 指定的名字,例如:**select * from db1.eg_user;** 那么 MyCat 并不会删除 db1 这个字段,如果没有定义该库的话
则会报错,所以在提供 SQL语句的最好是不带这个字段
总结: 该字段就是用户执行sql语句时,是否检查表明的schema,实际上与SQL语句语法是有重提的,强烈建议将该字段设置为false;
sqlMaxLimit : 当该值设置为某个数值时。每条执行的 SQL 语句,如果没有加上 limit 语句,MyCat 也会自动的加上所对应的值。例如设置值为 100,执行**select * from USERDB.eg_user;**的效果为
和执行**select * from USERDB.eg_userlimit 100;**相同。
如果没有设置该值的话,MyCat 默认会把查询到的信息全部都展示出来,造成过多的输出。所以,在正常使用中,还是建议加上一个值,用于减少过多的数据返回。
当然 SQL 语句中也显式的指定 limit 的大小,不受该属性的约束。
PS:需要注意的是,如果运行的 schema 为非拆分库的,那么该属性不会生效。需要手动添加 limit 语句。
dataNode : 1.3版本,如果schema配置了datanode属性,则不可以配置分片表.
1.4版本后,schema配置了datanode属性,也可以配置分片表.
dataNode指定了逻辑数据库对应物理数据库节点,逻辑库下的表默认都走schema配置的database.但是如果在table标签中也配置dataNode属性,则schema里面的dataNode不生效。
-->
<schema name="TestMycat" checkSQLschema="false" sqlMaxLimit="5" dataNode="dn1">
<!-- 表分片配置在这些 -->
<!--
如果对一个表进行了拆分,那么就需要在这里配上了逻辑关系,那个表在那个节点的那个库中,需要在这里配置。
name :定义逻辑表的表名,这个名字就如同我在数据库中执行 create table 命令指定的名字一样,同个 schema 标签中定义的名字必须唯一。
dataNode : 定义这个逻辑表所属的 dataNode, 该属性的值需要和 dataNode 标签中 name 属性的值相互对应。
rule : 该属性用于指定逻辑表要使用的规则名字,规则名字在 rule.xml 中定义,必须与 tableRule 标签中 name 属性属性值一一对应。
ruleRequired : 该属性用于指定表是否绑定分片规则,如果配置为 true,但没有配置具体 rule 的话,程序会报错.
primaryKey : 该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就会发送查询语句到所有配置的 DN 上,如果使用该属性配置真实表的主键。那么
MyCat 会缓存主键与具体 DN 的信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的 DN,但是尽管配置该属性,如果缓存并没有命中的话,还
是会发送语句给所有的 DN,来获得数据。
type : 该属性定义了逻辑表的类型,目前逻辑表只有“全局表”和”普通表”两种类型。对应的配置:全局表:global;普通表:不指定该值为 globla 的所有表。
autoIncrement : mysql 对非自增长主键,使用 last_insert_id()是不会返回结果的,只会返回 0。所以,只有定义了自增长主键的表才可以用 last_insert_id()返回主键值。
mycat 目前提供了自增长主键功能,但是如果对应的 mysql 节点上数据表,没有定义 auto_increment,那么在 mycat 层调用 last_insert_id()也是不会返回结果的。
由于 insert 操作的时候没有带入分片键,mycat 会先取下这个表对应的全局序列,然后赋值给分片键。这样才能正常的插入到数据库中,最后使用 last_insert_id()才会返回插入的
分片键值。
如果要使用这个功能最好配合使用数据库模式的全局序列。
使用 autoIncrement=“ true” 指定这个表有使用自增长主键,这样 mycat 才会不抛出分片键找不到的异常。
使用 autoIncrement=“ false” 来禁用这个功能,当然你也可以直接删除掉这个属性。默认就是禁用的。
subTables : 使用方式添加 subTables="t_order$1-2,t_order3"
目前分表 1.6 以后开始支持 并且 dataNode 在分表条件下只能配置一个,分表条件下不支持各种条件的join 语句
needAddLimit : 指定表是否需要自动的在每个语句后面加上 limit 限制。由于使用了分库分表,数据量有时会特别巨大。这时候执行查询语句,如果恰巧又忘记了加上数量限制的话。那么查询所有的数据
出来,也够等上一小会儿的。所以,mycat 就自动的为我们加上 LIMIT 100。当然,如果语句中有 limit,就不会在次添加了。这个属性默认为 true,你也可以设置成 false`禁用掉默认行
为.
childTable : childTable 标签用于定义 E-R 分片的子表。通过标签上的属性与父表进行关联
name : 定义子表的表名;
joinKey : 插入子表的时候会使用这个列的值查找父表存储的数据节点。
parentKey : 属性指定的值一般为与父表建立关联关系的列名。程序首先获取 joinkey 的值,再通过parentKey属性指定的列名产生查询语句,通过执行该语句得到父表存储在哪个分片上。从而确定子表存
储的位置.
primaryKey : 同 table 标签所描述的。
needAddLimit : 同 table 标签所描述的。
-->
<!--
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" primaryKey="ID" joinKey="order_id" parentKey="id" />
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id" parentKey="id" />
</table>
-->
</schema>
<schema name="TestXinsir" checkSQLschema="false" sqlMaxLimit="5" dataNode="dn2">
</schema>
<!-- 节点配置 -->
<!--
dataNode标签定义了 MyCat 中的数据节点,也就是我们通常说所的数据分片。一个dataNode标签就是一个独立的数据分片。
配置中所表述的意思为:使用名字为localhost1 数据库实例上的TestMycat物理数据库,这就组成一个数据分片,最后,我们使用名字 dn1 标识这个分片.
name : 定义数据节点的名字,这个名字需要是唯一的,我们需要在 table 标签上应用这个名字,来建立表与分片对应的关系。
dataHost : 该属性用于定义该分片属于哪个数据库实例的,属性值和dataHost标签中name属性值对应的。
database :该属性用于定义该分片属于哪个具体数据库实例上的具体库,因为这里使用两个维度来定义分片,就是:实例+具体的库。因为每个库上建立的表和表结构是一样的。所以这样做就可以轻松的
对表进行水平拆分。
-->
<dataNode name="dn1" dataHost="localhost1" database="TestMycat" />
<dataNode name="dn2" dataHost="localhost1" database="TestDB" />
<!-- 读写分离的配置 -->
<!--
作为 Schema.xml 中最后的一个标签,该标签在 mycat 逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句.
name : 标签要唯一,供上层的dataNode标签使用。
maxCon : 指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的 writeHost、 readHost 标签都会使用这个属性的值来实例化出连接池的最大连接数.
minCon : 指定每个读写实例连接池的最小连接,初始化连接池的大小I.连接池的连接都是空闲连接,供程序调用。
balance :负载均衡类型,目前的取值有 3 种.
0. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
1. balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
2. balance="2",所有读操作都随机的在 writeHost、 readhost 上分发.
3. balance="3",所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力,注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
writeType : 负载均衡类型,目前的取值有 3 种:
0. writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
1. writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。
2. writeType=”2",不执行写操作。
dbType : 指定后端连接的数据库类型,目前支持二进制的 mysql 协议,还有其他使用 JDBC 连接的数据库。例如:mongodb、 oracle、 spark 等.
dbDriver : 指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。使用 native 的话,因为这个值执行的是二进制的 mysql 协议,所以可以使用 mysql 和 maridb。其他类型的数据库
则需要使用 JDBC 驱动来支持,从 1.6 版本开始支持 postgresql 的 native 原始协议,如果使用 JDBC 的话需要将符合 JDBC 4 标准的驱动 JAR 包放到 MYCAT\lib 目录下,并检查驱动
JAR 包中包括如下目录结构的文件:META-INF\services\java.sql.Driver。在这个文件内写上具体的 Driver 类名,例如:com.mysql.jdbc.Driver
switchType : 此值标识主从同步时候,当主挂掉后,从的操作;目前取值有4种,具体如下:
-1 表示不自动切换;
1 默认值,自动切换;
2 基于 MySQL 主从同步的状态决定是否切换 心跳语句为 show slave status;
3 基于 MySQL galary cluster 的切换机制(适合集群)(1.4.1) 心跳语句为 show status like ‘wsrep%’;
tempReadHostAvailable : 如果配置了这个属性 writeHost 下面的 readHost 仍旧可用,默认 0 可配置(0、 1)
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" switchType="-1" dbType="mysql" dbDriver="native">
<!--
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native">
-->
<!--
heartbeat标签:
这个标签内指明用于和后端数据库进行心跳检查的语句,个人觉得只要是能被相应数据库识别的语句均可。例如,MYSQL 可以使用 select user(),Oracle 可以使用 select 1 from dual 等。
这个标签还有一个 connectionInitSql 属性,主要是当使用 Oracla 数据库时,需要执行的初始化 SQL 语句就这个放到这里面来。例如:alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'
-->
<heartbeat>select user()</heartbeat>
<!--
writeHost和readHost这两个标签都指定后端数据库的相关配置给 mycat,用于实例化后端连接池。唯一不同的是,writeHost 指定写实例、 readHost 指定读实例,组着这些读写实例来满足系统的要求。
在一个 dataHost 内可以定义多个 writeHost 和 readHost。但是,如果 writeHost 指定的后端数据库宕机,那么这个 writeHost 绑定的所有 readHost 都将不可用。另一方面,由于这个 writeHost
宕机系统会自动的检测到,并切换到备用的 writeHost 上去。
host 属性 : 用于标识不同实例,一般 writeHost 我们使用*M1,readHost 我们用*S1。
url 属性 : 后端实例连接地址,如果是使用 native 的 dbDriver,则一般为 address:port 这种形式。用 JDBC 或其他的dbDriver,则需要特殊指定。当使用 JDBC 时则可以这么写:
jdbc:mysql://localhost:3306/。
user 属性 : 后端存储实例需要的用户名.
password 属性 : 后端存储实例需要的密码. 注意:用户名和密码要对dataNode标签中指定的数据库拥有相应的权限。
weight 属性 : 权重 配置在 readhost 中作为读节点的权重(1.4 以后)
usingDecrypt 属性 : 是否对密码加密默认 0 否 如需要开启配置 1,同时使用加密程序对密码加密,加密命令为:
-->
<writeHost host="hostM1" url="192.168.1.186:3306" user="root" password="root">
</writeHost>
<writeHost host="hostS1" url="192.168.1.202:3306" user="root" password="root">
</writeHost>
</dataHost>
</mycat:schema>关于balance、writeType、switchType这三个参数重点讲解
为什么balance的值要等于1:
因为我们的目的是对mysql进行读写分离,而balance=1的时候,适用于的集群模式,也就是说M1-S1、M2-S2、M1-M2的时候M2、S1、S2都会处理读的请求,我们只有一对主从即M1-S1,所以所有的请求会转发的S1上;
我们writeType设置的值为0,所有所有的write请求在第一个writeHost没有down机的情况下,都会转发的第一个WriteHost上;
而我们switchType设置的是-1也就是说当主从复制的时候Master挂掉后不会进行主从的切换,那么从就不会来接替主的工作,这样写的请求就不会转发到从上;
综上三点所述,这样所有的读写请求就被自然的分开了。
heartbeat的参数是来设置检测后端mysql实例是否可以正常工作的设置,因为我们不需要进行主从切换的操作,所以使用了select user()语句进行检查后端实例的存活状态即可。
server.xml
这个配置文件如果修改了后,不需要重启mycat服务,修改完后静等10秒钟服务会自动重新加载这个配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!--本文件如果修改后,不需要重启mycat服务,系统会1分钟加载一次这个文件-->
<system>
<!--
配置该属性的时候一定要保证mycat的字符集和mysql的字符集是一致的
-->
<property name="charset">utf8</property>
<!--
1开启实时记录sql操作、0为关闭
-->
<property name="useSqlStat">0</property>
<!--
useGlobleTableCheck:是否开启全局表一致性检测。1为开启;0为关闭 。
sequnceHandlerType:用来指定Mycat全局序列类型,0为本地文件,1为数据库方式,2为时间戳列方式,默认使用本地文件方式,文件方式主要用于测试
-->
<property name="useGlobleTableCheck">0</property>
<property name="sequnceHandlerType">2</property>
<!--
1为开启mysql压缩协议
-->
<!--
<property name="useCompression">1</property>
-->
<!--
mycat模拟的mysql版本号,默认值为5.6版本,如非特需,不要修改这个值,目前支持设置 5.5,5.6,5.7 版本,其他版本可能会有问题。
<property name="fakeMySQLVersion">5.6.20</property>
-->
<!--
processorBufferChunk:指定每次分配socker direct buffer 的值,默认是4096字节
<property name="processorBufferChunk">40960</property>
processors:配置系统可用的线程数量,默认是cpu数量。
<property name="processors">1</property>
processorExecutor:这个属性主要用于指定NIOProcessor上共享的businessExecutor固定线程池大小。
mycat在需要处理一些异步逻辑的时候会把任务提交到这个线程池中。
新版本中这个连接池的使用频率不是很大了,可以设置一个较小的值。
<property name="processorExecutor">32</property>
-->
<!--
processorBufferPoolType :默认为0。0表示DirectByteBufferPool,1表示ByteBufferArena
-->
<property name="processorBufferPoolType">0</property>
<!--
maxStringLiteralLength :默认是65535 64K 用于sql解析时最大文本长度
sequnceHandlerType:同上
backSocketNoDelay:
<property name="maxStringLiteralLength">65535</property>
<property name="sequnceHandlerType">0</property>
<property name="backSocketNoDelay">1</property>
<property name="frontSocketNoDelay">1</property>
<property name="processorExecutor">16</property>
-->
<!--
<property name="serverPort">8066</property>
<property name="managerPort">9066</property>
<property name="idleTimeout">300000</property>
<property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property>
<property name="processors">32</property>
-->
<!--
分布式事务开关,
0为不过滤分布式事务,
1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),
2为不过滤分布式事务,但是记录分布式事务日志
-->
<property name="handleDistributedTransactions">0</property>
<!--
配置是否启用非堆内存跨分片结果集,1为开启,0为关闭,mycat1.6开始支持该属性
-->
<property name="useOffHeapForMerge">1</property>
<!--
单位为m
-->
<property name="memoryPageSize">1m</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--
是否采用zookeeper协调切换
-->
<property name="useZKSwitch">true</property>
</system>
<user name="xinsir">
<property name="password">123</property>
<property name="schemas">mycat,blog_user,blog_category,blog_article</property>
</user>
</mycat:server>里面有好多的注释设置,不用理睬,我们主要来看下面你这段设置。
<user name="xinsir">
<property name="password">123</property>
<property name="schemas">mycat,blog_user,blog_category,blog_article</property>
</user>name=“xinsir”这里的name设定的是用户名称
name=password标签中的123是设置的用户为xinsir的密码
name="schemas"标签中设定的参数是Schema.xml配置文件中的schema的名字,这里要一一对应不然启动的时候会报错,说找不到schema。
如果想设置只读用户,那么在这个标签下面再加一个标签为
<property name="readOnly">true</property>即表示这个用户对应的schema逻辑库都是只读。
log4j2.xml
为了更好的看到mycat的工作状态我们开启日志级别为debug模式,这样打出的日志会更详细。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d [%-5p][%t] %m %throwable{full} (%C:%F:%L) %n"/>
</Console>
<RollingFile name="RollingFile" fileName="${sys:MYCAT_HOME}/logs/mycat.log"
filePattern="${sys:MYCAT_HOME}/logs/$${date:yyyy-MM}/mycat-%d{MM-dd}-%i.log.gz">
<PatternLayout>
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %5p [%t] (%l) - %m%n</Pattern>
</PatternLayout>
<Policies>
<OnStartupTriggeringPolicy/>
<SizeBasedTriggeringPolicy size="250 MB"/>
<TimeBasedTriggeringPolicy/>
</Policies>
</RollingFile>
</Appenders>
<Loggers>
<asyncRoot level="debug" includeLocation="true">
<AppenderRef ref="Console" />
<AppenderRef ref="RollingFile"/>
</asyncRoot>
</Loggers>
</Configuration>如果验证读写分离是否生效,我们可以观看logs/mycat.log文件。
关于9066端口的使用
服务器启动后会有两个端口开启分别为8066、9066;8066是对外提供服务器的端口;9066是对mycat管理的使用接口,介绍几个常用命令:
show @@help #查看帮助信息,可以打出所有的命令信息,不同版本会有稍微差异
show @@server; #看系统使用情况,包括使用内存、启动时间、数据包的平均大小
show @@processor; #网络的进出流量情况,R_Quere观看请求是否有堆积问题,根据buf使用百分比来调整buf空间大小
show @@threadpod; #主要看积压,连接一般不会又积压
show @@connection;#看前端连接,以及连接信息,比较重要的是看是否有请求积压
show @@backend;#看后端的连接
show @@hearthbat; #RS_CODE心跳值为-1表示后端mysql服务器有问题,连接失败,RETRY表示有问题后尝试了几次连接请求,当后端mysql出现问题后,系统并不会第一时间把他在集群中剔除,而是要尝试几次连接后在进行剔除间隔时间大概是30秒。常见问题排除
1.ERROR:3099:java.long.IllegalArgument Exception:Invalid Deita Source:0
这个问题一般会有如下几个原因:
- 权限entity
- mysql的错误连接数过多,刷新mysql状态(小编遇到了这个坑)
- ip地址配置错误
- mysql故障
2.启动不了 - 尝试脚本本地启动 start_nowrap
- 检测Warp-xxx的可执行文件
- 内存参数修改
- 配置文件格式
3.命令行可以连接程序无法连接报错0miuisecons ago. - 一般是防火墙问题
4.程序连接一段时间报错
Last packet sent to the server was 76548 ms ago - 可能是程序没有开启连接池定时检测机制,导致连接空闲超时被mysql关闭。
mycat连接池默认时间为30分钟(空闲连接)
而mysql连接池默认时间为8小时,二者相差甚多。