perf使用示例2
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
稍微扩展一下思路,就可以发现改变采样的触发条件使得我们可以获得不同的统计数据:
以时间点 ( 如 tick) 作为事件触发采样便可以获知程序运行时间的分布。
以 cache miss 事件触发采样便可以知道 cache miss 的分布,即 cache 失效经常发生在哪些程序代码中。如此等等。
1.Perf list,perf 事件
不同的系统会列出不同的结果,在 2.6.35 版本的内核中,该列表已经相当的长,但无论有多少,我们可以将它们划分为三类:
Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样;
Software Event 是内核软件产生的事件,比如进程切换,tick 数等 ;
Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等。
2.Perf stat
使用 -e 选项来查看感兴趣的特殊的事件。
$perf stat ./t1
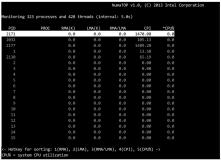
3.perf top
Perf top 用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程。
默认为cpu,还可以通过添加 -e 选项,列出造成其他事件的 TopN 个进程 / 函数。比如 -e cache-miss,用来看看谁造成的 cache miss 最多。
4.perf report
perf record -e cpu-clock ./t1 or perf record -e cpu-clock -g ./t1
perf report
5.示例
分支预测失败案例:
//test.c
#include <stdio.h>
#include <stdlib.h>
void foo()
{
int i,j;
for(i=0; i< 10; i++)
j+=2;
}
int main(void)
{
int i;
for(i = 0; i< 100000000; i++)
foo();
return 0;
}
原文
http://www.ibm.com/developerworks/cn/linux/l-cn-perf1/