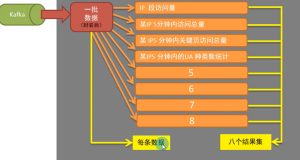
创建第一个实例:
使用urllib包获取百度首页信息:
import urllib.request
#导入urllib.request
f = urllib.request.urlopen('http://www.baidu.com/')
#打开网址,返回一个类文件对象
f.read(500)
#打印前500字符
f.read(500).decode('utf-8')
#打印前500字符并修改编码为utf-8',u){u=u||D.URL;var t=u.match(eval(\'/(\\\\?|#|&)(\'+n+\')=([^&]*)(&|$)/i\'));if(t){m=m||t[2];v=t[3]||v}return m&&v?\'&\'+m+\'=\'+v:\'\'}function ep(p){return(typeof(p)==="undefined")?"":p}function fc(){var h=location.host,x=\'=;expires=\'+new Date(0).toUTCString(),y=x+\';path=\',z=y+\'/;domain=\',l=[x,y,y+\'/\',z+h,z+h.substr(h.indexOf(\'.\'))],o=D.cookie.match(/[^ =;]+(?=\\=)/g);if(o&&S){for(var i=o.length;i--;){for(var j=5;j--;){D.cookie=o[i]+l[j]}}}if(window.localStorage){localStorage.clear()}if(window.sessionStora'
使用Requests库获取百度首页信息:
import requests #导入requests库
r = requests.get('https://www.baidu.com/')
#使用requests.get方法获取网页信息
r<Response [200]>
r.text #打印结果'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç\x99¾åº¦ä¸\x80ä¸\x8bï¼\x8cä½\xa0å°±ç\x9f¥é\x81\x93</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=ç\x99¾åº¦ä¸\x80ä¸\x8b class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ\x96°é\x97»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>å\x9c°å\x9b¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§\x86é¢\x91</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å\x90§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç\x99»å½\x95</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">ç\x99»å½\x95</a>\');\r\n </script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ\x9b´å¤\x9a产å\x93\x81</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å\x85³äº\x8eç\x99¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç\x94¨ç\x99¾åº¦å\x89\x8då¿\x85读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ\x84\x8fè§\x81å\x8f\x8dé¦\x88</a> 京ICPè¯\x81030173å\x8f· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'
r.encoding='utf-8'
#修改编码
r.text #打印结果'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">登录</a>\');\r\n </script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'
爬虫三步走
爬虫第一步:使用requests获得数据:
- 1.导入requests
- 2.使用requests.get获取网页源码
import requests
r = requests.get('https://book.douban.com/subject/1084336/comments/').text爬虫第二步:使用BeautifulSoup4解析数据:
- 1.导入bs4
- 2.解析网页数据
- 3.寻找数据
- 4.for循环打印
from bs4 import BeautifulSoup
soup = BeautifulSoup(r,'lxml')
pattern = soup.find_all('p','comment-content')
for item in pattern:
print(item.string)十几岁的时候渴慕着小王子,一天之间可以看四十四次日落。是在多久之后才明白,看四十四次日落的小王子,他有多么难过。
读了好多年,终于读完了,但是实在共鸣不起来,虽然知道那些道理,但真的觉得没什么了不起啊,是我还太幼稚吗?
我早该猜到,在她那可笑的伎俩后面是缱绻柔情啊。花朵是如此的天真无邪,可是,我毕竟太年轻了,不知该如何去爱她。
我的玫瑰花儿,只有四个微不足道的刺,用来抵御这个世界。
谁能告诉俺,小王子这种书有什么好看的?
他像一颗树那样倒了下去
不能理解的是,為什么它忽然紅成這樣?
说实话 我看不太懂 但还是跟风给个5星吧 以显示我也是有思想有学识之人
虽然我实在幼稚,但我并不怎么喜欢孩童般的纯净,我只爱风浪过后的平静,流水打磨出的清亮,大雪纷飞时的安宁,沧桑看透的纯真,我爱眼冷心热的庄子,人究竟无所逃于天地之间,各适其性,做自己认为有意义的事就好了,无论是统治宇宙还是喝酒点灯,对他们来说,都比爱一朵玫瑰重要,这不是很好的么
我老觉得小狐狸跟小王子是在搞GAY
第一遍读时,我才4岁。等到真的读懂,才明白为什么这是一部“童话”。
It is the time you have wasted for your rose that makes your rose so important.
狐狸告诉小王子的秘密是:用心去看才看得清楚;是分离让小王子更思念他的玫瑰;爱就是责任。
痛苦迷茫不是因为成为了“可笑”的大人,而是成为大人却没有真正长大。所以回过头来想要从怀念童年中解脱缓解痛苦那是本末倒置的做法。如果你作为一个成年人觉得痛苦,原因不是因为你“成年”了,也不是因为是生而为“人”,而是“你”停止了思考停止了学习。
爱屋及乌,爱一个人会让周围的一切变得美好,连麦浪的金黄都会让人心醉。
爱同样意味着责任。因为“你现在要对你驯服过的一切负责到底”。爱与被爱都有责任,每一段我们曾经付出过的感情,都必须为对方,为爱情负责,不是吗?
爱很多时候又会面临失去。小王子离开的时候,对狐狸说“那么你什么好处也没得到”。狐狸回答:“由于麦子颜色的缘故,我还是得到了好处”。爱同样意味着宽容,意味着放弃,也许我们在面对渐行渐远的爱情,该抱着平和感激的心态,因为我们起码收获了麦浪的金黄!
狐狸同样告诉小王子,“只有用心才能看得清。实质性的东西,用眼睛是看不见的”。只有这样,才能让我看清爱的本质。
爱是什么?
漫山遍野的玫瑰,但真的,我最喜欢最初的那一朵,带刺儿的那一朵。我能不能回去继续浇灌那朵玫瑰⋯⋯
长这么大,读过次数最多的书就是《小王子》,我是那么的爱这本书,可是我都没有一本属于我的小王子,每次想读了就去图书馆借他,读过很多版本的小王子,但是每次读他,小王子在我心中都不一样。我在我的612星球等我的小王子回家,但有时候我也不确定我是玫瑰还是狐狸或是那条毒蛇,可能我也是小王子。
原来在我还不懂爱情的时候就爱上了你
如果你是小王子,我就是那捉鸡的狐狸,求你驯养了我,却又对你说要你回去对你的玫瑰花负责。还大方地以为只要看见了麦田就会想起你头发的颜色。我却永远无法随你回到B-612星球。现在觉得,我可能只是猴面包树而已。
其實我覺得小王子自私不負責, 沒有看懂玫瑰, 而且被動地把小狐狸傷害了, 小王子看懂很多人和事, 卻到最後才明白愛情的本質。
爬虫第三步:使用pandas保存数据:
- 1.导入pandas
- 2.新建list对象
- 3.使用to_csv写入
import pandas
comments = []
for item in pattern:
comments.append(item.string)
df = pandas.DataFrame(comments)
df.to_csv('comments.csv')ok.这样就完成了一个简单的爬虫!