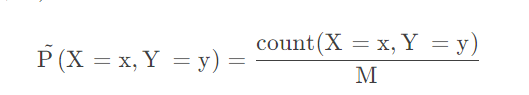MapReduce for Machine Learning
Baofeng Zhang
369447122@qq.com
转载请注明出处:http://blog.csdn.net/zbf8441372
Abstract
We are at the beginning of the multicoreera. Computers will have increasingly many cores (processors), but there isstill no good programming framework for these architectures, and thus no simpleand unified way for machine learning to take advantage of the potential speedup.
Recently, I have read a lot on Hadoop ,which is nowadays famousenough on dealing with Big data and distributed computation or storage.Especially, Mapreduce is created for distributed computation. It occurs to methat why not to program the existed classic machine learning algorithms,including those in data mining or artificial intelligence in a mapreduce way.
Thus, I did some research on the Map-Reduce for machine learning torewrite and accomplish parallel form of programming.
Introduction
Owing to my series of work, includingcollection, reading and practice, I`ve got some idea on the parallelprogramming by Mapreduce. I have set up a hadoop environment on my PC accordingto the official hadoop website[1], which helps me get to know the wholearchitecture about mapreduce more clearly. Besides, I`ve read books like Hadoopin action[2], Data-intensive Text Processing with MapReduce[3], Mahout inaction[4] and related papers at home and abroad. Actually, Mahout is aopen-project owned by Apache, which already achieved quite a lot algorithmsbased on the hadoop environment as commercial application.
During the next parts, I`ll first introduce Mapreduce to you for abetter understanding of what mapreduce is and what a kind of parallel programminglanguage it is. Only then can we realize its advantage and availability onturning the basic algorithms into parallel ones. In addition, some of the frequentlyused machine learning algorithms will be discussed as examples of what can becoded in the mapreduce framework, especially k-means, PageRank, EM. And alsoothers like locally weighted linear regression (LWLR), k-means, logisticregression (LR), naive Bayes (NB), SVM, ICA, PCA, gaussian discriminantanalysis(GDA), and backpropagation (NN)[6].
Hope my job can open your mind and trigger your interest inmapreduce programming, finally achieve something fantastic.
More about Mapreduce
MapReduce is a programming paradigm[5] thatat first sounds odd, or too simple to be powerful. The MapReduce paradigmapplies to problems where the input is a set of key-value pairs. A “map”function turns these key-value pairs into other intermediate key-value pairs. A“reduce” function merges in some way all values for each intermediate key, toproduce output. Actually, many problems can be framed as a MapReduce problem,or a series of them. And, the paradigm lends itself quite well toparallelization: all of the processing is independent, and so can be splitacross many machines.
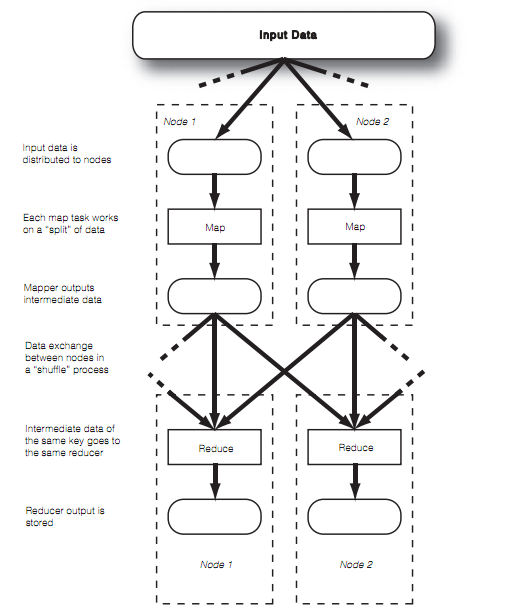
The above image show a general mapreduce data flow. Note that afterdistributing input data to different nodes, the only time nodes communicatewith each other is at the “shuffle” step. This restriction on communicationgreatly helps scalability.
Architecture
Many programming frameworks are possiblefor the summation form, but inspired by Google’s success in adapting a functionalprogramming construct, mapreduce [9], for wide spread parallel programming use inside their company, weadapted this same construct for multicore use. Google’s map-reduce isspecialized for use over clusters that have unreliable communication and whereindividual computers may go down. These are issues that multicores do not have;thus, we were able to developed a much lighter weight architecture formulticores, shown as follows.
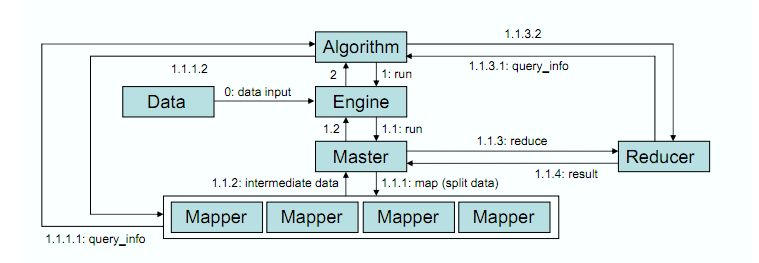
It showsa high level view of our architecture and how it processes the data. In step 0,the mapreduce engine is responsible for splitting the data by training examples(rows). The engine then caches the split data for the subsequent map-reduce invocations.Every algorithm has its own engine instance, and every map-reduce task will bedelegated to its engine (step 1). Similar to the original mapreducearchitecture, the engine will run a master (step 1.1) which coordinates themappers and the reducers. The master is responsible for assigning the splitdata to different mappers, and then collects the processed intermediate datafrom the mappers (step 1.1.1 and 1.1.2). After the intermediate data iscollected, the master will in turn invoke the reducer to process it (step1.1.3) and return final results (step 1.1.4). Note that some mapper and reduceroperations require additional scalar information from the algorithms. In orderto support these operations, the mapper/reducer can obtain this information throughthe query info interface, which can be customized for each different algorithm(step 1.1.1.1 and 1.1.3.2).
Adopted Algorithms
K-means
K-means is common in clustering, and it isrelatively fast and easy to code. Also many papers did optimization on naivek-means and implemented variations based on the original k-means. For thepurpose of comparison, first of all, let`s review the simple description on Serialk-means method procedure.
1) Randomly choose k samples to bethe center of each group
2) Do the iteration
a) According to the centercoordinated calculated each time, distribute each sample point to some group bythe nearest Eular distance
b) Update the center point, whichmeans compute the average coordinates in every group
3) Until converge
Next, see how we can change its costume. The main task lays in how toproperly design and implement the “Map” and “Reduce” method, including the typesof <key, value> pairs as input and output and the specific logic. We dothe parallelization based on the conclusion that the procedure of “distributeeach sample point to some group by the nearest Eular distance” is relativelyindependent. Here comes the PKmeans(Parallel KMeans)[7].
1) Randomly choose k samples to bethe center point, store these k points in a HDFS file, as the global var. Theiteration is composed of three functions: Map, Combine and Reduce.
2) Map:
For the input <key, value>,key is the offset respect to the current group center`s position and value is astring of coordinates of the current sample in all its dimensions. We analyzethe value and get the data info allover dimensions, then calculate its Eulardistance relative to each k group`s center point separately, finding thenearest. At last, output the new <key`, value`>, whose key` stands forthe coordinate of the nearest center and value` is still a string ofcoordinates of the current sample in all its dimensions.
The pseudocode goes like this:
map (<key, value>, <key`, value`>) {
String[]instance;
get the sample object from “value”and put into instance
Long minDis;
assign proper value fot assist varminDis to be possibly large
for i=0 to k-1 do {
dis= the distance between the instance and the Ki point;
if (dis < minDis) {
minDis = dis;
index= i;
}
}
take the index as key`;
get coordinates in all the dimensionfor value`;
return <key`, value`>;
}
In order to reducethe data volume during transition and the cost in communication, we havedesigned a Combine operation to merge the output data in local after the Mapoperation. Because Map`s output is first stored locally, the cost incommunication of the merging is low.
3) Combine:
For the input<key, V>, key means the index of the data set and V is a linked list ofstring, also for the coordinates of samples in all its dimensions, and thesesamples are allocated to a certain data set described in key. We analyze theinput and get every sample`s coordinates in all dimension sequentially from thelinked list, meanwhile count the summation of samples. At last, output the new<key`, value`>, whose key` is the same as input and value` contains twoaspects: total amout of samples and a string of the coordinate values in alldimensions.
pseudocode:
combine(<key,V>, <key`, value`>) {
initial an arrayfor storing the sum of the coordinates over all dimensions, and each vector isset to zero initially;
initial a varnamed num, counting the sum of samples allocated to some same data set, set tozero;
while (V.hasNext()) {
get coordinates values of one sample fromV.next();
do the summation over all dimensions tothe array and relevant vector;
num ++;
}
take key askey`;
construct astring, including num and info of all vectors in arrays, assign to value`;
return <key`,value`> ;
}
4) Reduce:
For the input<key, V>, key is the index of data set, V comes from combine`sintermediate result. In Reduce, we get the amount of samples in each Combineand the summation of relevant nodes` coordinate values over all dimensions. Thenadding together the coordinates values separately in dimensions and divided bythe total amout of samples, as the new center point coordinate.
pseudocode:
reduce(<key, V>, <key`, value`>) {
initial an arrayfor storing the sum of the coordinates over all dimensions, and each vector isset to zero initially;
initial a varnamed NUM, counting the sum of samples allocated to some same data set, set tozero;
while (V.hasNext()) {
get coordinates values of one sample andtotal number of samples as num from V.next();
do the summation over all dimensions tothe array and relevant vector;
NUM+= num;
}
divide each part-value in array byNUM, resulting in the new center coordinate;
assign key for key`;
construct a string, including the newcenter pointer`s info in all dimensions, assign for value`;
return <key`, value`>;
}
Based on the output of Reduce, getting the new center point andupdate the HDFS file. Then continue the iteration till converge.
On the whole, the PKmeans shows parallelization and high expansion ratio for thecombine operation to cut down the cost in communication.
EM
Machine learning is often categorized aseither supervised or unsupervised. Supervised learning of statistical modelssimply means that the model parameters are estimated from training dataconsisting of pairs of inputs and annotations. Unsupervised learning, on theother hand, requires only that the training data consist of a representativecollection of objects that should be annotated.
Here we focus on a particular class ofalgorithms, expectation maximization (EM), algorithms that can be used to learnthe parameters of a joint model Pr(x, y) from incomplete data.
Expectationmaximization algorithms fitt naturally into the MapReduce paradigm, and are usedto solve a number of problems of interest in text processing. Furthermore,these algorithms can be quite computationally expensive, since they generallyrequire repeated evaluations of the training data. MapReduce therefore providesan opportunity not only to scale to larger amounts of data, but also to improveefficiency bottlenecks at scales where non-parallel solutions could beutilized.
Here is the general steps to get MapReduce implementations of EM algorithm:
1) Each iteration of EM is oneMapReduce job.
2) A controlling process (i.e.,driver program) spawns the MapReduce jobs, keeps track of the number ofiterations and convergence criteria
3) Model parameterswhich arestatic for the duration of the MapReduce job, are loaded by each mapper fromHDFS or other data provider (e.g., a distributed key-value store).
4) Mappers map over independenttraining instances, computing partial latent variable posteriors (or summarystatistics, such as expected counts).
5) Reducers sum together therequired training statistics and solve one or more of the M-step optimizationproblems.
6) Combiners, which sum togetherthe training statistics, are often quite effective at reducing the amount ofdata that must be written to disk.
Thedegree of parallelization that can be attained depends on the statisticalindependence assumed in the model and in the derived quantities required tosolve the optimization problems in the M-step. Since parameters are estimatedfrom a collection of samples that are assumed to be i.i.d., the E-step cangenerally be parallelized effectively since every training instance can beprocessed independently of the others. In the limit, in fact, each independenttraining instance could be processed by a separate mapper!
Reducers,however, must aggregate the statistics necessary to solve the optimizationproblems as required by the model. The degree to which these may be solved independentlydepends on the structure of the model, and this constrains the number of reducersthat may be used. Fortunately, many common models (such as HMMs) requiresolving several independent optimization problems in the M-step. In thissituation, a number of reducers may be run in parallel. Still, it is possiblethat in the worst case, the M-step optimization problem will not decompose intoindependent subproblems, making it necessary to use a single reducer.
PageRank
PageRank [8] is a measure of web pagequality based on the structure of the hyperlink graph. PageRank is a measure ofhow frequently a page would be encountered by our tireless web surfer. Moreprecisely, PageRank is a probability distribution over nodes in the graph representingthe likelihood that a random walk over the link structure will arrive at a particularnode. Its rule is that nodes that have high in-degrees tend to have highPageRank values, as well as nodes that are linked to by other nodes with highPageRank values. Similarly, if a high-quality page links to another page, thenthe second page is likely to be high quality also.
Formally,the PageRank P of a page n is dened as follows:

where|G| is the total number of nodes (pages) in the graph, is therandom jumpfactor, L(n) is the set of pages that link to n, and C(m) is theout-degree of node m (the number of links on page m). The random jump factorissometimes called the “teleportation” factor; alternatively, (1 -) isreferred to as the “damping” factor.
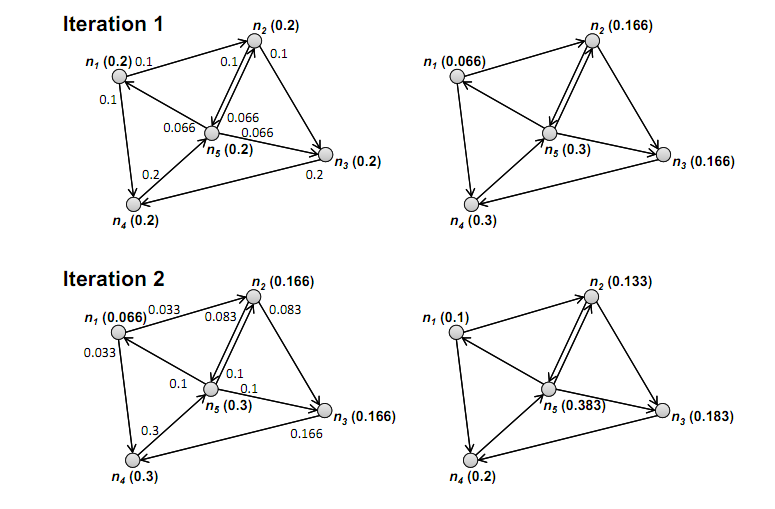
Thefollow example showing two iterations, top and bottom. Left graphs show PageRankvalues at the beginning of each iteration and how much PageRank mass is passedto each neighbor. Right graphs show updated PageRank values at the end of eachiteration. (ignore the random jump factor for now (i.e., = 0) and further assume that there are nodangling nodes (i.e., nodes with no outgoing edges)
Pseudo codeof the MapReduce PageRank algorithm is shown here. it is simplied in that wecontinue to ignore the random jump factor and assume no dangling nodes.
class Mapper
methodMap(nid n, node N)
p← N.PageRank /|N.AdjacencyList|
EMIT(nidn, N) // Pass along graph structure
for all nodeid m∈N.AdjacencyListdo
EMIT(nidm, p) // Pass PageRank massto neighbors
class Reducer
methodReduce(nid m, [p1, p2, …])
M← null
forall p∈counts[p1,p2, …] do
if IsNode(p) then
M← p
else
s← s+p
M:PageRank← s
Emit(nidm, node M)
Inthe map phase we evenly divide up each node's PageRank mass and pass each piecealong outgoing edges to neighbors. In the reduce phase PageRank contributions aresummed up at each destination node. Each MapReduce job corresponds to oneiteration of the algorithm.
The algorithm maps over the nodes, and for each node computes howmuch PageRank mass needs to be distributed to its neighbors (i.e., nodes on theadjacency list). Each piece of the PageRank mass is emitted as the value, keyedby the node ids of the neighbors. Conceptually, we can think of this as passingPageRank mass along outgoing edges.
In the shuffle and sort phase, the MapReduce execution frameworkgroups values (piece of PageRank mass) passed along the graph edges bydestination node (i.e., all edges that point to the same node). In the reducer,PageRank mass contributions from all incoming edges are summed to arrive at theupdated PageRank value for each node.
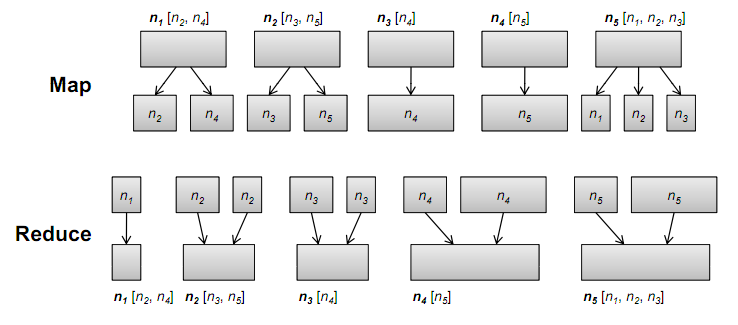
The size of each box is proportion to its PageRank value. During themap phase, PageRank mass is distributed evenly to nodes on each node'sadjacency list (shown at the very top). Intermediate values are keyed by node(shown inside the boxes). In the reduce phase, all partial PageRankcontributions are summed together to arrive at updated values.
Here just do not take into account the random jump factor and dangling nodes.
To seemore examples, refer to the NIPS06 paper by Cheng-Tao Chu, Sang Kyun Kim, Yi-AnLin, YuanYuan Yu, Gary Bradski, Andrew Y. Ng, Kunle Olukotun.[6] I`m too youngtoo naive to specify them in sequence.
Conclusion
Bytaking advantage of the summation form in a mapreduce, framework, we couldparallelize a wide range of machine learning algorithms.
Due to the limited time, I`ve got no extra time to finish theexperiment part. Though, I have got a great passion on accomplishing these theoreticallycapable algorithms(some also has been succeeded in implementation). From nowon, this report/paper will encourage me and arouse my interests in putmapreduce parallel algorithms into practice. I`m looking forward to making somedifferences based on my present hierarchy. The reference material helps me alot. So if you are ruuning out of time or just tired of my wordy writing, docheck the references and you are bound to benefit quite a lot! Thx.
References
[1] hadoop website/quickstart: http://hadoop.apache.org/common/docs/r0.19.2/cn/quickstart.html
[2] book: “hadoop in action”
[3] Data-Intensive Text Processing with MapReduce, JimmyLin and Chris Dyer, University of Maryland, College Park
[4] book: “mahout in action”
[5] Dean J, Ghemawat S. Mapreducesimplifieddata processing on large clusters
[6] Map-Reduce for Machine Learning on Multicore,NIPS06, Cheng-Tao Chu, Sang Kyun Kim, Yi-An Lin, YuanYuan Yu, Gary Bradski, AndrewY. Ng, Kunle Olukotun
[7] 基于云计算平台Hadoop的并行k-means聚类算法设计研究, 赵卫中, 马慧芳, 傅燕翔,史忠植
[8] Lawrence Page, Sergey Brin, Rajeev Motwani, andTerry Winograd. The PageRank citation ranking: Bringing order to theWeb.
[9] J. Dean and S. Ghemawat. Mapreduce: Simpli?ed dataprocessing on large clusters. Operating Systems Design and Implementation,pages 137–149, 2004.
[10] Hadoop-MapReduce下的PageRank矩阵分块算法, 李远方,邓世昆,闻玉彪,韩月阳