线上一个查询简化如下:
Selectdt,count(distinct c1) , count(distinct case when c2>0 and c1=0 then c1 end),count(distinct case when c2>0 and c1>0 then c1 end) from t where dtbetween ‘20131108’ and ‘20131110’ group by dt;
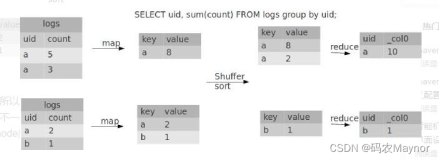
一个让人头痛的multi-distinct问题,为什么说很头痛,看看执行计划就清楚了:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
|
ABSTRACTSYNTAX TREE:
(TOK_QUERY (TOK_FROM (TOK_TABREF (TOK_TABNAMEt))) (TOK_INSERT (TOK_DESTINATION (TOK_DIR TOK_TMP_FILE)) (TOK_SELECT(TOK_SELEXPR (TOK_TABLE_OR_COL dt)) (TOK_SELEXPR (TOK_FUNCTIONDI count(TOK_TABLE_OR_COL c1))) (TOK_SELEXPR (TOK_FUNCTIONDI count (TOK_FUNCTION when(and (> (TOK_TABLE_OR_COL c2)
0
) (= (TOK_TABLE_OR_COL c1)
0
))(TOK_TABLE_OR_COL c1)))) (TOK_SELEXPR (TOK_FUNCTIONDI count (TOK_FUNCTION when(and (> (TOK_TABLE_OR_COL c2)
0
) (> (TOK_TABLE_OR_COL c1)
0
))(TOK_TABLE_OR_COL c1))))) (TOK_WHERE (TOK_FUNCTION between KW_FALSE(TOK_TABLE_OR_COL dt)
'20131108'
'20131110'
)) (TOK_GROUPBY (TOK_TABLE_OR_COLdt))))
STAGEDEPENDENCIES:
Stage-
1
is a root stage
Stage-
0
is a root stage
STAGEPLANS:
Stage: Stage-
1
Map Reduce
Alias -> Map Operator Tree:
t
TableScan
alias: t
Filter Operator
predicate:
expr: dt BETWEEN
'20131108'
AND
'20131110'
type: Boolean
//通过select operator做投影
Select Operator
expressions:
expr: dt
type: string
expr: c1
type:
int
expr: c2
type:
int
outputColumnNames: dt, c1, c2
//在MAP端进行简单的聚合,雷区1:假设有N个distinct,MAP处理数据有M条,那么这部处理后的输出是N*M条数据,因为MAP会对dt,keys[i]做聚合操作,所以尽量在MAP端过滤尽可能多的数据
Group By Operator
aggregations:
expr: count(DISTINCTc1)
expr: count(DISTINCTCASE WHEN (((c2 >
0
) and (c1 =
0
))) THEN (c1) END)
expr: count(DISTINCTCASE WHEN (((c2 >
0
) and (c1 >
0
))) THEN (c1) END)
bucketGroup:
false
keys:
expr: dt
type: string
expr: c1
type:
int
expr: CASE WHEN (((c2>
0
) and (c1 =
0
))) THEN (c1) END
type:
int
expr: CASE WHEN (((c2>
0
) and (c1 >
0
))) THEN (c1) END
type:
int
mode: hash
outputColumnNames: _col0,_col1, _col2, _col3, _col4, _col5, _col6
//雷区2:在做Reduce Sink时是根据partition cplumns进行HASH的方式,那么对于按date分区的表来说一天的所有数据被放大N倍传输到Reducer进行运算,导致性能长尾或者OOME.
Reduce Output Operator
key expressions:
expr: _col0
type: string
expr: _col1
type:
int
expr: _col2
type:
int
expr: _col3
type:
int
sort order: ++++
Map-reduce partitioncolumns:
expr: _col0
type: string
tag: -
1
value expressions:
expr: _col4
type: bigint
expr: _col5
type: bigint
expr: _col6
type: bigint
Reduce Operator Tree:
Group By Operator
aggregations:
expr: count(DISTINCTKEY._col1:
0
._col0)
expr: count(DISTINCTKEY._col1:
1
._col0)
expr: count(DISTINCTKEY._col1:
2
._col0)
bucketGroup:
false
keys:
expr: KEY._col0
type: string
mode: mergepartial
outputColumnNames: _col0, _col1,_col2, _col3
Select Operator
expressions:
expr: _col0
type: string
expr: _col1
type: bigint
expr: _col2
type: bigint
expr: _col3
type: bigint
outputColumnNames: _col0, _col1,_col2, _col3
File Output Operator
compressed:
true
GlobalTableId:
0
table:
input format:org.apache.hadoop.mapred.TextInputFormat
output format:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Stage: Stage-
0
Fetch Operator
limit: -
1
|
虽说Hive里有参数:hive.groupby.skewindata(具体见:http://boylook.blog.51cto.com/7934327/1316432)不过当设置该参数时只支持single-distinct(https://issues.apache.org/jira/browse/HIVE-2416)因此在这种场景下是没办法设置的.但是这个参数还是有一定启发的就是把SQL化归到这种single-distinct:通过union all(注意不能直接Union All而是需要嵌套进子查询,否则会报异常:Toplevel UNION is not supported currently; use a subquery for the UNION).
查看执行计划(省去非关键部分):
|
1
2
3
4
5
6
|
STAGE DEPENDENCIES:
Stage-
1
is a root stage
Stage-
2
depends on stages:Stage-
1
, Stage-
3
, Stage-
4
Stage-
3
is a root stage
Stage-
4
is a root stage
Stage-
0
is a root stage
|
可以看到每个single-distinct都是独立的stage,因此可以设置上面的参数,这里既然每个stage是独立的那么是不是可以设置hive.exec.parallel,hive.exec.parallel.thread.number这两个参数来以资源换时间呢?故事总是残忍的,这里还有一个Bug(https://issues.apache.org/jira/browse/HIVE-4436), 因此在Hive0.12 release前是没办法的,这就叫有钱没地方花.
另外也有通过unionall+sum的解决方法,感兴趣的同学也可以尝试一下.
如果不做100%精确计算的话可以通过bucket sample的方式可以更快的解决:)
本文转自MIKE老毕 51CTO博客,原文链接:http://blog.51cto.com/boylook/1322536,如需转载请自行联系原作者