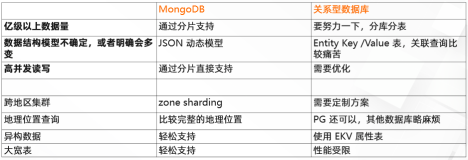
背景
一直受传统RDB的影响,对于数据库表的设计可能大多数开发者都形成了思维定势。在云计算和大数据背景下,RDBMS正在接近极限,KV存储将受到越来越多的关注。学习NoSQL,不求能革RDBMS的命,但希望在设计思路上能得到一些拓宽,很多场景里,SQL表的设计和计算语句其实蛮难受的。
RDBMS天生不是分布式的,因其保持着ACID的特性发展至今,非常重视数据完整性,但在机器规模增长的情况下,ACID是不可扩展的。同时,随着数据量和访问频率增加,ACID所要维护的开销在增大。分割数据库,无论水平还是垂直,都是在分散总数据和读取需求,达到优化目的,维护代价和难度也随之上升。而KV的查找本质是散列表,且数据量无论如何增大,查找时间几乎固定不变,即非常适合大规模数据。ACID很注重CAP中的C,而参考现实世界中很多事务,比如快递,从你下单、付款到取货,资金和物品的流转并不严格一致,只要在一段时间内整个交易的最后结果满足一致性就可以了。同样,NoSQL和RDBMS比,更偏向于BASE(Basically Available, Soft-state, Eventually consistent)的折中,重视可用性,但不追求状态的严密性,且满足最终一致性。下面我以mongodb为例,展现一些他的特性和场景,期待NoSQL在当下能被更多的开发者拿来一显身手。
mongodb与RDBMS
mongodb是面向文档的nosql,CouchDB则是这一类数据库的元祖。从总体上看,
1. mongodb是最亲和RDBMS的一个NoSQL,能解决大部分关系型数据库解决的问题
2. 跟面向列存储的HBase相比,面向文档存储和面向行存储更接近,比如在没有索引的情况下,扫描整个表内记录,同样是扫描全文档,及文档的每个字段
3. mongodb的索引同样也是B树,在一些索引的优化和设计上会和MySQL比较相似(当然需要遵循mongo的设计来做,不完全划等号)
4. 你可以把mongodb拿RDBMS一样来使用(当然不推荐这么做),无非是将一行记录变成mongodb里的json对,在document(相当于mysql的table)之间,也可以做类似外键一样的引用
5. mongodb虽然没有严格的事务性操作,但是开发者自己可以做到类似事务的效果(详见下文)。这一点也算是mongodb贴近RDBMS的一个表现吧。
6. mongo的查询中也有mysql中的in, where, group等字段,而且想group那样的查询会比mysql更强大(见下文)

以下会从各个主要关注点来展开mongo的特性,展现角度更偏向于想要调研使用mongodb的人,看看mongodb是否符合自己的业务场景,也希望我的分析会有所帮助。
存储结构怎么样
Mongodb的存储类似JSON,每个db内有多个collection,相当于table,每个collection内是许许多多的document,这个document的schemeless的。本质上,他的面向文档指的是key-value中的value,而这个value可以是一个值(引用id或基本类型),可以是一个数组,也可以是一个文档(嵌套的json对)。
一对多是最常遇到的场景,mysql中要使用两张或以上表的关联甚至join进行查询,在mongo中直接使用嵌套型或引用型(用id)就可以了。没有特殊需求的话,嵌套的方式只要一张"表"就可以实现。比如我这样建立一个人的信息:
处理好多对多的关系可谓是NoSQL的精髓所在。理论上,可以在一个集合中完成存储。不过实际上这样的情况非常罕见。这是由于查询的多样性所导致的,若是只有一种类型的查询,则这种多对多的关系放在一个良好设计的集合中,虽然会有大量的冗余,但是效率一定是最高的。如何设计这种数据库的关键就是看你有多少种查询,每一种的频率是多少,使用的其他要求是什么样的。对于不同的查询,同样的数据库设计的性能也是大不一样。还有一点,一般不要拆成三个集合,这是传统的关系型数据库的思维方式。而常见的情况就是拆成两个集合,然后有一部分冗余,对最常用的查询做一个索引。
总结就是两张表,一张里面存了另外一张里的id集合,有冗余存放,主要是根据查询场景设计和建索引,不要和RDBMS一样变三张。此外还有个好处是可以进行正反向查询,在各自的字段里加上id数组。
创新、更新、删除文档
为避免不良设计,doc大小有限制,mongodb 1.8支持16M
批量插入 mongoimport
更新:文档替换:模式结构有大变化时,update(find_the_doc, new_doc)
修改器:$inc 操作整数,双精度浮点数 小范围改动 速度很快,如果不存在则创建 {"$inc" : {"keyname" : 100 }}
$set $unset 修改某个键,如果不存在则创建
$push $pop 操作数组 $ne来判断某个数组里是否存在某值 $addToSet和$each组合
修改器速度:$inc属于就地修改 而数组修改器可能更改了文档大小,会慢
mongodb给文档预留了补白,来适应大小变化,如果超出了则重新分配空间,就会慢了
所以要自己设计。不然$push可能会成为瓶颈,就考虑把内嵌的数组独立出来,单独放到集合里
特殊的更新 upsert (update第三个参数)是原子性的,比如db.math.update({"count":25}, {"$inc":{"count":3}}, true) 如果没有count会生成,然后继续加3
update的时候,第一个参数是找符合的doc,第二个参数是更新操作,第三个是否upsert,第四个参数是是否更新多个文档
执行完后运行getLastError看有没有更新出错
findAndModify,等待数据库相应,在操作查询、取值和赋值整个原子性操作时很方便,速度慢些
一直受传统RDB的影响,对于数据库表的设计可能大多数开发者都形成了思维定势。在云计算和大数据背景下,RDBMS正在接近极限,KV存储将受到越来越多的关注。学习NoSQL,不求能革RDBMS的命,但希望在设计思路上能得到一些拓宽,很多场景里,SQL表的设计和计算语句其实蛮难受的。
RDBMS天生不是分布式的,因其保持着ACID的特性发展至今,非常重视数据完整性,但在机器规模增长的情况下,ACID是不可扩展的。同时,随着数据量和访问频率增加,ACID所要维护的开销在增大。分割数据库,无论水平还是垂直,都是在分散总数据和读取需求,达到优化目的,维护代价和难度也随之上升。而KV的查找本质是散列表,且数据量无论如何增大,查找时间几乎固定不变,即非常适合大规模数据。ACID很注重CAP中的C,而参考现实世界中很多事务,比如快递,从你下单、付款到取货,资金和物品的流转并不严格一致,只要在一段时间内整个交易的最后结果满足一致性就可以了。同样,NoSQL和RDBMS比,更偏向于BASE(Basically Available, Soft-state, Eventually consistent)的折中,重视可用性,但不追求状态的严密性,且满足最终一致性。下面我以mongodb为例,展现一些他的特性和场景,期待NoSQL在当下能被更多的开发者拿来一显身手。
mongodb与RDBMS
mongodb是面向文档的nosql,CouchDB则是这一类数据库的元祖。从总体上看,
1. mongodb是最亲和RDBMS的一个NoSQL,能解决大部分关系型数据库解决的问题
2. 跟面向列存储的HBase相比,面向文档存储和面向行存储更接近,比如在没有索引的情况下,扫描整个表内记录,同样是扫描全文档,及文档的每个字段
3. mongodb的索引同样也是B树,在一些索引的优化和设计上会和MySQL比较相似(当然需要遵循mongo的设计来做,不完全划等号)
4. 你可以把mongodb拿RDBMS一样来使用(当然不推荐这么做),无非是将一行记录变成mongodb里的json对,在document(相当于mysql的table)之间,也可以做类似外键一样的引用
5. mongodb虽然没有严格的事务性操作,但是开发者自己可以做到类似事务的效果(详见下文)。这一点也算是mongodb贴近RDBMS的一个表现吧。
6. mongo的查询中也有mysql中的in, where, group等字段,而且想group那样的查询会比mysql更强大(见下文)
以下会从各个主要关注点来展开mongo的特性,展现角度更偏向于想要调研使用mongodb的人,看看mongodb是否符合自己的业务场景,也希望我的分析会有所帮助。
存储结构怎么样
Mongodb的存储类似JSON,每个db内有多个collection,相当于table,每个collection内是许许多多的document,这个document的schemeless的。本质上,他的面向文档指的是key-value中的value,而这个value可以是一个值(引用id或基本类型),可以是一个数组,也可以是一个文档(嵌套的json对)。
一对多是最常遇到的场景,mysql中要使用两张或以上表的关联甚至join进行查询,在mongo中直接使用嵌套型或引用型(用id)就可以了。没有特殊需求的话,嵌套的方式只要一张"表"就可以实现。比如我这样建立一个人的信息:
{
id : 1,
name : "pelick",
hobbies : {
"GameA", "GameB", "GameC"
},
friends : {
male : {
2, 3, 4 # id refer to other person
},
female : {
{
name : "Rita",
hobbies : { "dancing" }
},
{
name : "Kaka",
nickname : "Riva"
}
}
}
} 上述这样的结构中,展现了无模式、value为数组、嵌套、引用等。
处理好多对多的关系可谓是NoSQL的精髓所在。理论上,可以在一个集合中完成存储。不过实际上这样的情况非常罕见。这是由于查询的多样性所导致的,若是只有一种类型的查询,则这种多对多的关系放在一个良好设计的集合中,虽然会有大量的冗余,但是效率一定是最高的。如何设计这种数据库的关键就是看你有多少种查询,每一种的频率是多少,使用的其他要求是什么样的。对于不同的查询,同样的数据库设计的性能也是大不一样。还有一点,一般不要拆成三个集合,这是传统的关系型数据库的思维方式。而常见的情况就是拆成两个集合,然后有一部分冗余,对最常用的查询做一个索引。
总结就是两张表,一张里面存了另外一张里的id集合,有冗余存放,主要是根据查询场景设计和建索引,不要和RDBMS一样变三张。此外还有个好处是可以进行正反向查询,在各自的字段里加上id数组。
创新、更新、删除文档
为避免不良设计,doc大小有限制,mongodb 1.8支持16M
批量插入 mongoimport
更新:文档替换:模式结构有大变化时,update(find_the_doc, new_doc)
修改器:$inc 操作整数,双精度浮点数 小范围改动 速度很快,如果不存在则创建 {"$inc" : {"keyname" : 100 }}
$set $unset 修改某个键,如果不存在则创建
$push $pop 操作数组 $ne来判断某个数组里是否存在某值 $addToSet和$each组合
修改器速度:$inc属于就地修改 而数组修改器可能更改了文档大小,会慢
mongodb给文档预留了补白,来适应大小变化,如果超出了则重新分配空间,就会慢了
所以要自己设计。不然$push可能会成为瓶颈,就考虑把内嵌的数组独立出来,单独放到集合里
特殊的更新 upsert (update第三个参数)是原子性的,比如db.math.update({"count":25}, {"$inc":{"count":3}}, true) 如果没有count会生成,然后继续加3
update的时候,第一个参数是找符合的doc,第二个参数是更新操作,第三个是否upsert,第四个参数是是否更新多个文档
执行完后运行getLastError看有没有更新出错
findAndModify,等待数据库相应,在操作查询、取值和赋值整个原子性操作时很方便,速度慢些
查询(简单例举一下)
find()指定返回的键
查询条件 $lt $gt $lte $gte 别的查询键 $or $in $nin $not等,不具体举例了,不是特性了解就好
查询数组相关:$all $size $slice
正则表达式:支持Perl兼容的正则表达式(PCRE)
对查询结果的处理 $limit $skip $sort (其中$skip适合跳过少量文档,否则性能影响)
以上不能满足,还有$where,更复杂的查询是mapreduce(下文介绍)
find()指定返回的键
查询条件 $lt $gt $lte $gte 别的查询键 $or $in $nin $not等,不具体举例了,不是特性了解就好
查询数组相关:$all $size $slice
正则表达式:支持Perl兼容的正则表达式(PCRE)
对查询结果的处理 $limit $skip $sort (其中$skip适合跳过少量文档,否则性能影响)
以上不能满足,还有$where,更复杂的查询是mapreduce(下文介绍)
聚合( mongodb本身的聚合操作可能可以好好依赖一下,比如olap里复杂的查询和本地聚合操作可以大量借用mapreduce?)
count() distinct()
group() 类似 group by,且可以附带一个finalize函数对结果修剪
mapreduce可以做复杂的聚合查询,并行化到多个服务器,当然mapreduce和group都不适合实时场景
简单演示一下mongodb的group和mapreduce的基本写法,不深究细节,但求了解个大概,高级查询可以做些什么。
Group:
> db.runCommand({"group" : {
"ns" : "posts",
"key" : {"tags" : true},
"initial" : {"tags" : {}},
"$reduce" : function(doc, prev) {
for (var i in doc.tags) {
if (doc.tags[i] in prev.tags) {
prev.tags[doc.tags[i]] ++;
} else {
prev.tags[doc.tags[i]] = 1;
}
},
"finalize" : function(prev) {
var mostPopular = 0;
for (i in prev.tags) {
if (prev.tags[i] > mostPopular) {
prev.tag = i;
mostPopular = prev.tags[i];
}
}
delete prev.tags
}
}})Mapreduce:
> map = function () {
for (var key in this) {
emit(key, {count : 1});
}
};
> reduce = funtion (key, emits) {
total = 0;
for (var i in emits) {
total += emits[i].count;
}
return {"count" : total};
}
> mr = db.runCommand({"mr_example":"test", "map":map, "reduce":reduce})函数分为map, reduce,还有finalize,query,sort,scope等函数辅助MR。
利用好以上的查询和聚合方法,加上合理设计,应该满足大部分查询场景。
索引怎么样
- 和传统RDBMS几乎一样,好处是同样的索引优化方法适用于mongodb
- 被索引之后,会按照索引排序
- 查询一半以上的结果,不用索引,表扫描就可以了,比如查某个布尔或存在某个键
- 默认最大索引个数64,每次插入更新删除都会产生额外开销
- 用ensureIndex:1 or -1来控制索引方向
- 对内嵌文档中的键建索引和普通索引没有什么区别
- 用.explain()看查找情况,有没有用索引,扫描了多少文档等等
- 还有基于地理空间的索引,$near :[-40, 73] $within $box / $center
索引补充:对没有索引的键使用sort,mongo会把所有数据拿到内存排序,所以有上限,不能做T级别sort。所以可以为排序而建索引。
mongodb与js
cmd环境下是js引擎,记得使用的是V8引擎(可能随着版本更新引擎会改变)。所有的执行语句都有一套js的API。同时,db.eval()可以执行js。更令人惊喜的是,system.js里可以存储js变量,所以也可以直接存储js函数,然后用db.eval()执行调用。比如:
db.system.js.insert({"_id" : "log", "value" :
function(msg, level) {
var levels = [“DEBUG”, "WARN", "ERROR", "FATAL"];
level = level ? level : 0;
var now = new Date();
print(now + " " + levels[level] + msg);
}); 然后调用它,
db.eval("x = 1; log('x is '+x); x = 2; log('x is greater than 1', 1);"); 输出结果是:
DEBUG x is 1 WARN x is greater than 1我对mongodb的这一特性充满遐想,可能很多脚本和日常操作,包括运维操作,都可以用js写好并存储,而且js本身可以做一切mongodb的操作,这个特性可以给我们带来更多的什么呢?我觉得mongodb这样的设计,和以前我们接触的mysql这样的数据库有一个很本质的区别。我们通常意义中的数据库只负责存储数据,除了sql提供一些查询和增删改查外,其余复杂的数据处理都需要通过各自语言的driver来连接数据库并自己用代码实现一些处理逻辑,最后再返回到数据库中。而mongodb,不但提供了可以任意执行js的环境,已经mapreduce这样复杂的查询设计,而且还支持保存js代码在system.js中,其实仅仅靠mongodb本身,就可以做任何你想做的数据操作和处理。这样的好处是,使用mongodb的应用层可以完全解耦对mongodb数据处理的依赖,可能mongodb的DBA可以除了专职维护外,用一些内置的js代码完成复杂的处理逻辑,让应用层可以放心使用预备好的数据。我觉得这在易用的同时做到了真正的强大。此外,可以想象前端开发人员如果单独设计一套系统或搭建一个网站,会很喜欢使用mongodb。
事务性怎么样( 没有写要求的可以忽略这段)
mongo的事务性操作其实蛮巧妙的,他支持一个findAndModify的操作,是一个保证原子性的操作。顾名思义,在一个操作里先find目标文档,然后进行修改,整个过程由mongo保证原子。具体使用方法不介绍了。
此外还有一套乐观的并发控制。乐观并发控制其实是update本身,基于认为“同一个文档基本上不会被同时修改”这一乐观的事务机制。整个事务的过程会分拆为以下几个步骤,需要开发者自己来实现:
- 通过查询获得文档
- 保存文档原始值
- 更新得到一个新的文档
- 用原始文档当作arg1,更新文档当作arg2进行一次update操作
- 若更新失败则重复1
分区分库怎么样
有这样的情况,同部门各个项目中,各组的DBA会各自做各自的分库分区,对于mysql的分区分库不够透明,,而在JDBC的SQL语句层(不论使用的是MyBatis还是Spring JDBC等),不能完全将读取数据库路由与上层应用解耦。这应该是一个常见的问题。mongo的分片读取都由路由来完成,应用程序只要连接一个mongos路由进行即可,路由会从配置服务mongod里获得各个db和collection的情况以及分片片键,一般推荐一个mongos对应一个应用。
 上图是一种健壮的分片部署方式。黄色mongod为配置服务器,绿色mongos为路由,蓝色为真实存储数据的分片。且每个shard里有三个mongod,构成的是一个副本集(自动故障恢复的主从集群,且没有固定的主节点)。蓝色mongod是实际存储数据的分片,且shard之间需要手动设定负载均衡依据的片键,mongodb会自动做负载均衡,相关配置信息会记录在黄色mongod配置服务器上。分片可以动态增加和减少,只要启动一个mongod,用命令添加到分片集群里,他就可以一起做负载了。而每个mongod其实都是一个单独的mongodb实例,也可以不依赖集群单独启动使用。应用程序通过连接路由mongos来和mongodb打交道,应该说读取数据是比较透明。分片集群的搭建,扩容与增减分片,副本集的搭建,应用层对分片集群的使用接入等基本概念,具体可以参看我之前一篇博客http://blog.csdn.net/pelick/article/details/8644116。总之,扩容、部
上图是一种健壮的分片部署方式。黄色mongod为配置服务器,绿色mongos为路由,蓝色为真实存储数据的分片。且每个shard里有三个mongod,构成的是一个副本集(自动故障恢复的主从集群,且没有固定的主节点)。蓝色mongod是实际存储数据的分片,且shard之间需要手动设定负载均衡依据的片键,mongodb会自动做负载均衡,相关配置信息会记录在黄色mongod配置服务器上。分片可以动态增加和减少,只要启动一个mongod,用命令添加到分片集群里,他就可以一起做负载了。而每个mongod其实都是一个单独的mongodb实例,也可以不依赖集群单独启动使用。应用程序通过连接路由mongos来和mongodb打交道,应该说读取数据是比较透明。分片集群的搭建,扩容与增减分片,副本集的搭建,应用层对分片集群的使用接入等基本概念,具体可以参看我之前一篇博客http://blog.csdn.net/pelick/article/details/8644116。总之,扩容、部
署、搭建等操作是非常方便的,这也是mongodb易用性高的一个重要原因。
GridFS存储文件
mongo自带存储大的二进制文件。基本思想是把打文件分成很多块,每块单独作为一个文档存。使用方面和存取一般的document一样,也有分片机制,不产生磁盘碎片。视觉中国用GridFS存过大量图片。
管理和运维
./mongod --port XXX --logpath XXX 的启动方式,也可以./mongod --config ~/.mongodb.conf 的配置文件方式启动
比启动端口大1000号的端口有页面版的管理信息查看
mongodump作备份,mongorestore恢复备份
有这样的情况,同部门各个项目中,各组的DBA会各自做各自的分库分区,对于mysql的分区分库不够透明,,而在JDBC的SQL语句层(不论使用的是MyBatis还是Spring JDBC等),不能完全将读取数据库路由与上层应用解耦。这应该是一个常见的问题。mongo的分片读取都由路由来完成,应用程序只要连接一个mongos路由进行即可,路由会从配置服务mongod里获得各个db和collection的情况以及分片片键,一般推荐一个mongos对应一个应用。
署、搭建等操作是非常方便的,这也是mongodb易用性高的一个重要原因。
GridFS存储文件
mongo自带存储大的二进制文件。基本思想是把打文件分成很多块,每块单独作为一个文档存。使用方面和存取一般的document一样,也有分片机制,不产生磁盘碎片。视觉中国用GridFS存过大量图片。
管理和运维
./mongod --port XXX --logpath XXX 的启动方式,也可以./mongod --config ~/.mongodb.conf 的配置文件方式启动
比启动端口大1000号的端口有页面版的管理信息查看
mongodump作备份,mongorestore恢复备份
(待补充)