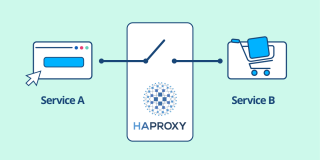
haproxy基础概念
HAproxy对比LVS
lvs是工作在内核空间中的,因此突破了SOCK文件的限定(文件描述符)所以ipvs转发和并发能达到400万
haproxy和nginx是工作在用户空间的,因此每个进程打开的套接字文件数是有限定的,一般来讲最多并发不能超过65536个 只是单纯的理论上来讲
一般来讲大于4万个就不错了,因为每个连接请求到达之后,其会每一端(客户端和服务器端)都需要同时打开1个文件,所以其并发连接有限,但仅此而言无论是nginx还是haproxy
从以上对比来看,虽然haproxy和nginx的性能略有下降,但是下降的并不多,维持连接的代价也不是非常大,因此一般能维持2W个并发连接问题是不大的。
事实上2W-3W已经是非常大的并发量了,如果同时并发连接数有2w个,那么每个用户的每个请求可以在1秒钟提供处理的话,那么一天的响应量将近16亿个,假如页面中平均有20个对象的话,意味着每天的响应量能达到亿级PV。
haproxy在同样并发场景下haproxy可能比nginx需要更多的内存资源但是haproxy拥有很多自己独有的特性
虽然与nginx相比,区别不是非常的大,但haproxy有一种独有的特性的数据结构算法叫做弹性二叉树(作者自行开发的独有数据结构)
haproxy的一些机制,在内存中,会话的建立、查找、删除是非常频繁的
这时为了实现高效的数据的频繁建立 查找 删除等必须有一种非常好的数据结构
初期haproxy的数据结构类似于O(logN)的算法,但作者认为随着用户连接数的增多,额外开销不容忽视,所以在其基础上又将其进行了改进被称为弹性二叉树
这种数据结构由于不用额外维护其的平衡性,可以达到O(1),此外数据建立查找等操作,能够在内部维护,但是在弹性我二叉树维持上,也避免了最后的线性查找
所以在随着连接数增多在建立连接、保持连接等是非常恒定的,因此建立多少个链接都无所谓,只要当前haproxy能够支撑(硬件)
haproxy目前主要版本的特性
1.4版本:
提供了更好的弹性
·支持客户端一次长连接
简单来讲,web代理服务器是一次性处理两者(客户端和upstream server)的独立链接
那客户端至haproxy的连接可以使其支持keepalive(保持连接)
因为http是无状态的,每个资源的请求默认情况下首先tcp三次握手,建立会话并取得资源,最后四次断开,如果一次请求多个对象,那么毫无疑问每个对象都要这么做,所以效率会非常低,因此如果我们开启keepalive功能,那么效率相对来说会非常高。
但注意的是haproxy1.0的版本默认情况下保持会话连接是关闭的1.1版本默认是开启的,所以在1.0中要使用keepalive功能用户的客户端和服务端通信的时候要发送一独特的首部信息,首部信息明确说明是keepalive,而版本1.1默认就启动了keepalive,只要服务器打开了keepalive功能之间本身就可以保持连接,但是keepalive保持时间不能过长,允许服务器端将用户连接释放掉,并去响应其他用户请求的,所以要想支持keepalive,服务器端必须要有此功能,叫做服务器端关闭。
一般而言,都是谁请求谁关闭,也就是说一般都是由客户端进行关闭的,但是只要使用keepalive功能,一般需要支持服务端关闭功能,因为keepalive本身开启还必须要有保持时间等机制,一旦超时则关闭其连接。
·支持tcp加速
所有的数据不用复制进用户空间,而直接转发
·支持响应池
也被称为响应缓冲池
·支持RDP协议
远程桌面协议,通常是多个连接,甚至可以反向负载均衡至多个winserver并且将多个请求定向发送至指定server 以避免交叉连接
·基于源的粘性
类似于nginx的IP Hash算法 ,将来自于同一客户端的请求始终转发至一个后端upstreamserver
·更好的统计数据接口
有独立的状态页面,每个状态颜色和状态客观明了
·更详细的健康状态监测机制
与nginx差不多,多次重复的尝试几次检查
而且可以观测服务器流量,如果流量越来越小则自动结束掉其连接
·支持http认证
·服务器管理命令行接口
在命令行模式下可对服务器进行管理
·基于acl的持久性
可以将用户的某些特性抽取特性并根据其特性做匹配条件控制
另外有自己独立的日志分析器,方便分析日志
·单进程驱动模型
haproxy是单进程事件驱动模型,因此不用进行上下文切换,避免了上下文本身的资源的开销
O(1)事件检查器,使弹性二叉树来实现
·单缓冲模型
因此实现不复制任何数据的方式完成读写操作
借助于linux 2.6内核中的splice()模块进行系统调用,能够实现零复制转发,甚至在3.5的内核实现零复制启动
MRU内存分配器在固定大小的内存池中实现即时内存分配
·树型存储,弹性二叉树
优化的http首部分析,目前来讲性能够好,精心降低了系统调用,大部分工作都在用户空间完成,如时间读取、缓冲聚合以及文件描述符的启用和禁用等
本文转自zuzhou 51CTO博客,原文链接:http://blog.51cto.com/yijiu/1428649