500年前,高层建筑,如同行式数据库一般,由墙壁提供水平支撑。由于当时钢铁数量有限、价格昂贵,如此大型的建筑物在高度上受到限制。美国最早期的高层建筑之一就是纽约市摩天大楼“世界大楼”,它高309英尺,共20层,建于1890年。台湾的台北101楼高1474英尺,共101层。诸如此类的现代摩天大楼则是垂直支撑在钢骨架上。目前,台北101是世界上最高的建筑物。但第一的地位很快将被取代。迪拜目前正在建造更高的建筑。这些现代摩天大楼如同列式数据仓库一般,它们的楼高可以并且也将越来越高。
“列式数据仓库以更低成本提供更佳性能,而且所用空间比传统行式关系型数据仓库更小——因此,很难理解为什么那些特别关注查询性能的公司不考虑采纳列式解决方案。”Philip Howard在他洋洋洒洒的报告《“列”酷在哪里?(What's Cool About Columns)》的结尾处写道。该报告发表于2008年3月,是专门提供给欧洲主要信息技术分析组织Bloor研究公司的。
不断成长
事实上,列式数据仓库——Sybase IQ分析服务器——是由其与Sun SPARC Enterprise M9000 Server和BMMsoft Server共同打造而成的全球最大的数据仓库的核心。这一开创纪录的成就涉及1PB(即1035 TB)的原始数据。(详情请见《2009 年吉尼斯世界记录》第 144 页)
我们知道列式数据仓库其实是由Sybase于1993年首创、并在1996年发布的,但近期发生的众多列式数据仓库的相关事件却才刚刚吸引人们的广泛关注。这或许会让人感到困惑,因为在其经过12年发展的今天,Sybase IQ才逐渐赢得主流市场的认同,列式数据仓库的竞争也开始表现得十分活跃。或许,正是上述表现,加上Sybase自身致力于向市场宣传其卓越的分析服务器,以及商业环境的变化(如人们要求在保持性能的同时降低成本)才是根源所在。
Bloor的Howard似乎同意这一观点:“在过去十年里,列式方法的使用在很大程度上一直是一个小众事件。”Howard注意到,近期有8个供应商进入到这个曾是Sybase独享的领域,且全球2000强公司越来越关注该领域,“我们相信,是时候让‘列’走出阴霾,成为数据仓库和相关市场的主要力量了。”他补充。
Sybase IQ目前约有1300名用户,由此可以说,如今的列式数据仓库已经走出了阴霾。在Bloor 13页的报告中,Bloor 详细说明了列式关系型数据库“可能曾经是什么”,和它们的作用、工作方法以及与传统关系型数据库相比的优势。早在2001年,Geoffrey Moore就评价说:它们是最根本、最前沿的技术。
当时,硅谷最优秀的技术大师之一、影响深远的商业书《跨越鸿沟》(Crossing the Chasm)一书的作者Moore认为,Sybase已经将经典的数据库行式架构模式“完全”改变为列式架构,提取数据的速度比传统数据库快100倍,而且支持与多人实时共享。“这是一种全新的模式,由此可以创造无限的市场机遇。”Moore特别强调了该产品的特点,“了解列式数据库对分析的含义。”
优势所在
来自全球最大的数据库专家Winter公司的Richard Winter在《新时代的高效数据仓储》白皮书 (http://www.wintercorp.com) 中如此解释Sybase IQ的架构:“它旨在支持大量用户的并发运行特别是查询。因此,该设计和工程过程……首先关注的是查询性能,其次是完成批量数据更新的速度,再次是小数据更新的性能。这一优先排序与通用引擎截然不同,后者用于在线交易处理和数据仓储(实际上,这通常更强调交易处理)。这样的引擎必须尝试同时实现复杂查询的交互性能和高容量在线更新。由于Sybase IQ的设计目标严格以数据仓储为主,其架构和性能特征相当明显,这有利于数据仓库用户。”
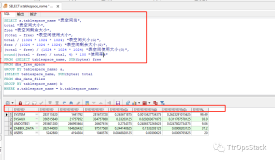
例如,拥有数百万用户的在线购物服务可能需要基本的查询功能。问题可能是:随着圣诞节的来临,过去3年有多少纽约人购买了珠宝?为了回答这一问题,行式数据库将需要50万次输入/输出(I/O)重新定向。因为,行式流程将需要处理大量不相关的数据。在Sybase IQ的列式操作中,要回答此问题则只需要234次I/O。这些数字是利用1600万行、在一个表格上进行计算而获得的。事实上,要进行适当的查询,从每一列获取的数据应始终小于从传统数据库获取的数据。这意味着I/O次数减少,因此列式数据库的性能更佳。行式数据库管理员试图通过构建数据的摘要、聚合和索引,解决与行相关的问题,但是优先采用列式数据库便可解决所有问题。
上述就是Sybase IQ的设计与传统数据库的不同之所在:前者专门定向,提供分析用商业情报仓库,而后者主要用于完善交易——两者的任务不同。
“与行式架构相比,‘将数据储存在列中’采纳压缩算法,提供了大量提高性能的机会。”来自麻省理工学院的三位作者在2006年的一份报告《列式数据库系统集成压缩和执行》中如此描述。三位作者分别是Daniel J Abati、Samuel R. Madden 和 Miguel C. Ferreira。他们在报告中指出,在列式数据库中,采用一次性对多个值进行编码的压缩方案很自然。“而在行式数据库中,此类方案效果不佳,因为属性储存为整体元组(元素集)的一部分,因此将不同元组的相同属性,结合到一个值中将需要采取措施‘混合’元组。”他们解释。
来自Bloor的Howard写道:“从行到列的变化看起来微不足道,实际上意义深远。”正是由于人们越发认识到其意义深远,Sybase IQ的特殊分析列式存储才激发了如此大的热情。在业务环境下,任何人在开发数据价值的同时都随处面临数据超载的问题,他们也致力于寻求控制方法。此时,Sybase IQ的一个优势在于,其数据处理速度比传统方法快 100 倍。Sybase IQ的高速分析能力可几乎实时处理大量的特定查询。另一个优势在于,它仅处理可以回答这些查询的列,而不是分类整理与特定查询无关的数据行。这自然加快了流程。
此外,列式方法应用优化的压缩——效率高达 10:1 以上,同时,每个列的数据保持一致(种类、采购日期和地点)。这意味着可以使用更少的磁盘空间存储更多信息,从而提供更多可供分析的历史数据。
在Sybase IQ众多客户中,法国Prémalliance公司是法国国内主要的社会福利提供商。凭借Sybase IQ,该公司的技术成就脱颖而出,并荣获2008Computerworld Honors(2008 年计算机世界荣誉)的桂冠奖。
Premalliance需要整合和分析全球数据图表,展示其核心业务的福利合约所取得的商业、财务和技术成果。采用Sybase IQ的结果之一就是帮助Prémalliance完成其整合过程,并在不到5秒钟的时间内至少汇总3000万个数据行,而且不会对 服务器 造成巨大负荷。Prémalliance过去曾说,即使是为董事会董事准备报告也要求大量的IT资源投入,通常可以获得所需信息——但需要花2至3周才能将这些信息集合与组织起来。当然,今非昔比,Prémalliance仍有很多潜力可以挖掘,其发展可谓前程似锦。
尾声..转点论坛个人热论已普及一下sybase IQ 的新鲜玩意
提到发展方向,个人认为列式数据库在今后的发展中,应该考虑以下几个方向:
1,分布式计算:可能和楼上提的分布式列式数据库类似,希望看到可能是分步走的过程,先做CPU上面的分布;再做主机层面的分布;最后是存储层面的分布。这样可以更大地打开计算能力的瓶颈。列式数据库的列式存储的优势配合上分布式计算的优势,应该是未来的一个大方向。至于说叫不叫云计算都不重要。
2,进一步的索引优化:可能以新的索引的方式,可能以索引对查询/分析的使用方式等
3,分久必合,合久必分,我想行式数据库必定会有压力去突破,等行式数据库也慢慢地接受列式数据库带来的的技术冲击,最终我们会发现行式和列式其实在某一个层面上并没有那么大的差别,会某种意义上再合并起来,共同解决数据存储/使用的问题。
个人观点:
行式数据库存储的时候大部分是采用堆表的方式,随机插入优势明显,列式数据库如果数据即索引,则随机插入的开销要大。每一列都有次定位和插入的动作,索引本身的维护量不会少。列式数据库本身还有其它形式索引,和行式相似。
大量的修改(varchar)时行式存储难免产生行漂移。这点恐怕对行数据库不利。
大量随机删除时堆表的维护应该是好于索引的维护的。
所以OLTP上行式数据库肯定优于列式数据库。
目前IQ上的索引基本也就改良B树和改良位图两类。全文检索应该是不太合适的。
查询特别是大范围查询,列式数据库因为是压缩存放的,所以IO上优势应该是明显的,
但牵涉到多表关联时更多取决于连接的join算法问题、统计结果的存放问题。现在市面上的OLAP产品也多,
MOLAP的产品在这方面的优势明显,ROLAP在一定程度上处于劣势,虽然IQ增加了join index但该索引的维护很夸张。如果不能再做到分布式的数据分布,后期的扩展就有问题了。
分布式列式数据库在ROLAP上应该是发展方向。
很好的讨论,坐等各位高手的意见。
关于列式数据库你知道多少?
存储结构不同,使用场景不同,老牌的数据库厂商目前只有sybase有很成熟的产品,并且有些成功案例。
你知道列式数据仓库是谁首创的吗?
目前声音最响的是sybase,谁首创真还不知道。
你知道全球有多少家列式数据库厂商?
Sybase是目前最大的一家,还有一些小的列式数据库厂商。
你知道列式数据库与传统行式数据库有什么不同吗?
主要是存储模式不同而导致查询效率、存储效率、索引模式等等方面都和传统行式数据库有很大差异。从列式数据库的实现Sybase IQ而言,相同的地方在于标准的借口和对SQL标准的支持。
你对列式数据库持什么样的看法呢?
目前主要应用于OLAP领域,包括查询、统计、报表、分析、历史数据存储等等方面,OLTP领域不适合。列式数据库应该是一个方向吧,目前Sybase IQ是一个影响最大的实现产品,期待其它DB巨头的表态,好像Oracle新版本也在准备支持,如果这样的话,应该是一个方向。
在BI系统中,一般批量ETL只是准备数据阶段,
在数据展现阶段还是会有大量的读操作。
当然,你也可以把数据展现交给OLAP SERVER去做,比如ESSBASE等。
但这样存在大量数据导入导出,构造CUBE等操作。
IQ当初的设计理念是
写节点处理批量ETL,读节点代替OLAP SERVER,直接支持各种报表类、分析类查询及ad-hoc查询。
因此,写节点需要高配置实现资源集中化,而读节点实现可扩展应付并发查询。
而且用读写节点物理分离的方式解决批处理与查询的资源竞争问题。
“列式数据仓库以更低成本提供更佳性能,而且所用空间比传统行式关系型数据仓库更小——因此,很难理解为什么那些特别关注查询性能的公司不考虑采纳列式解决方案。”Philip Howard在他洋洋洒洒的报告《“列”酷在哪里?(What's Cool About Columns)》的结尾处写道。该报告发表于2008年3月,是专门提供给欧洲主要信息技术分析组织Bloor研究公司的。
不断成长
事实上,列式数据仓库——Sybase IQ分析服务器——是由其与Sun SPARC Enterprise M9000 Server和BMMsoft Server共同打造而成的全球最大的数据仓库的核心。这一开创纪录的成就涉及1PB(即1035 TB)的原始数据。(详情请见《2009 年吉尼斯世界记录》第 144 页)
我们知道列式数据仓库其实是由Sybase于1993年首创、并在1996年发布的,但近期发生的众多列式数据仓库的相关事件却才刚刚吸引人们的广泛关注。这或许会让人感到困惑,因为在其经过12年发展的今天,Sybase IQ才逐渐赢得主流市场的认同,列式数据仓库的竞争也开始表现得十分活跃。或许,正是上述表现,加上Sybase自身致力于向市场宣传其卓越的分析服务器,以及商业环境的变化(如人们要求在保持性能的同时降低成本)才是根源所在。
Bloor的Howard似乎同意这一观点:“在过去十年里,列式方法的使用在很大程度上一直是一个小众事件。”Howard注意到,近期有8个供应商进入到这个曾是Sybase独享的领域,且全球2000强公司越来越关注该领域,“我们相信,是时候让‘列’走出阴霾,成为数据仓库和相关市场的主要力量了。”他补充。
Sybase IQ目前约有1300名用户,由此可以说,如今的列式数据仓库已经走出了阴霾。在Bloor 13页的报告中,Bloor 详细说明了列式关系型数据库“可能曾经是什么”,和它们的作用、工作方法以及与传统关系型数据库相比的优势。早在2001年,Geoffrey Moore就评价说:它们是最根本、最前沿的技术。
当时,硅谷最优秀的技术大师之一、影响深远的商业书《跨越鸿沟》(Crossing the Chasm)一书的作者Moore认为,Sybase已经将经典的数据库行式架构模式“完全”改变为列式架构,提取数据的速度比传统数据库快100倍,而且支持与多人实时共享。“这是一种全新的模式,由此可以创造无限的市场机遇。”Moore特别强调了该产品的特点,“了解列式数据库对分析的含义。”
优势所在
来自全球最大的数据库专家Winter公司的Richard Winter在《新时代的高效数据仓储》白皮书 (http://www.wintercorp.com) 中如此解释Sybase IQ的架构:“它旨在支持大量用户的并发运行特别是查询。因此,该设计和工程过程……首先关注的是查询性能,其次是完成批量数据更新的速度,再次是小数据更新的性能。这一优先排序与通用引擎截然不同,后者用于在线交易处理和数据仓储(实际上,这通常更强调交易处理)。这样的引擎必须尝试同时实现复杂查询的交互性能和高容量在线更新。由于Sybase IQ的设计目标严格以数据仓储为主,其架构和性能特征相当明显,这有利于数据仓库用户。”
例如,拥有数百万用户的在线购物服务可能需要基本的查询功能。问题可能是:随着圣诞节的来临,过去3年有多少纽约人购买了珠宝?为了回答这一问题,行式数据库将需要50万次输入/输出(I/O)重新定向。因为,行式流程将需要处理大量不相关的数据。在Sybase IQ的列式操作中,要回答此问题则只需要234次I/O。这些数字是利用1600万行、在一个表格上进行计算而获得的。事实上,要进行适当的查询,从每一列获取的数据应始终小于从传统数据库获取的数据。这意味着I/O次数减少,因此列式数据库的性能更佳。行式数据库管理员试图通过构建数据的摘要、聚合和索引,解决与行相关的问题,但是优先采用列式数据库便可解决所有问题。
上述就是Sybase IQ的设计与传统数据库的不同之所在:前者专门定向,提供分析用商业情报仓库,而后者主要用于完善交易——两者的任务不同。
“与行式架构相比,‘将数据储存在列中’采纳压缩算法,提供了大量提高性能的机会。”来自麻省理工学院的三位作者在2006年的一份报告《列式数据库系统集成压缩和执行》中如此描述。三位作者分别是Daniel J Abati、Samuel R. Madden 和 Miguel C. Ferreira。他们在报告中指出,在列式数据库中,采用一次性对多个值进行编码的压缩方案很自然。“而在行式数据库中,此类方案效果不佳,因为属性储存为整体元组(元素集)的一部分,因此将不同元组的相同属性,结合到一个值中将需要采取措施‘混合’元组。”他们解释。
来自Bloor的Howard写道:“从行到列的变化看起来微不足道,实际上意义深远。”正是由于人们越发认识到其意义深远,Sybase IQ的特殊分析列式存储才激发了如此大的热情。在业务环境下,任何人在开发数据价值的同时都随处面临数据超载的问题,他们也致力于寻求控制方法。此时,Sybase IQ的一个优势在于,其数据处理速度比传统方法快 100 倍。Sybase IQ的高速分析能力可几乎实时处理大量的特定查询。另一个优势在于,它仅处理可以回答这些查询的列,而不是分类整理与特定查询无关的数据行。这自然加快了流程。
此外,列式方法应用优化的压缩——效率高达 10:1 以上,同时,每个列的数据保持一致(种类、采购日期和地点)。这意味着可以使用更少的磁盘空间存储更多信息,从而提供更多可供分析的历史数据。
在Sybase IQ众多客户中,法国Prémalliance公司是法国国内主要的社会福利提供商。凭借Sybase IQ,该公司的技术成就脱颖而出,并荣获2008Computerworld Honors(2008 年计算机世界荣誉)的桂冠奖。
Premalliance需要整合和分析全球数据图表,展示其核心业务的福利合约所取得的商业、财务和技术成果。采用Sybase IQ的结果之一就是帮助Prémalliance完成其整合过程,并在不到5秒钟的时间内至少汇总3000万个数据行,而且不会对 服务器 造成巨大负荷。Prémalliance过去曾说,即使是为董事会董事准备报告也要求大量的IT资源投入,通常可以获得所需信息——但需要花2至3周才能将这些信息集合与组织起来。当然,今非昔比,Prémalliance仍有很多潜力可以挖掘,其发展可谓前程似锦。
尾声..转点论坛个人热论已普及一下sybase IQ 的新鲜玩意
提到发展方向,个人认为列式数据库在今后的发展中,应该考虑以下几个方向:
1,分布式计算:可能和楼上提的分布式列式数据库类似,希望看到可能是分步走的过程,先做CPU上面的分布;再做主机层面的分布;最后是存储层面的分布。这样可以更大地打开计算能力的瓶颈。列式数据库的列式存储的优势配合上分布式计算的优势,应该是未来的一个大方向。至于说叫不叫云计算都不重要。
2,进一步的索引优化:可能以新的索引的方式,可能以索引对查询/分析的使用方式等
3,分久必合,合久必分,我想行式数据库必定会有压力去突破,等行式数据库也慢慢地接受列式数据库带来的的技术冲击,最终我们会发现行式和列式其实在某一个层面上并没有那么大的差别,会某种意义上再合并起来,共同解决数据存储/使用的问题。
个人观点:
行式数据库存储的时候大部分是采用堆表的方式,随机插入优势明显,列式数据库如果数据即索引,则随机插入的开销要大。每一列都有次定位和插入的动作,索引本身的维护量不会少。列式数据库本身还有其它形式索引,和行式相似。
大量的修改(varchar)时行式存储难免产生行漂移。这点恐怕对行数据库不利。
大量随机删除时堆表的维护应该是好于索引的维护的。
所以OLTP上行式数据库肯定优于列式数据库。
目前IQ上的索引基本也就改良B树和改良位图两类。全文检索应该是不太合适的。
查询特别是大范围查询,列式数据库因为是压缩存放的,所以IO上优势应该是明显的,
但牵涉到多表关联时更多取决于连接的join算法问题、统计结果的存放问题。现在市面上的OLAP产品也多,
MOLAP的产品在这方面的优势明显,ROLAP在一定程度上处于劣势,虽然IQ增加了join index但该索引的维护很夸张。如果不能再做到分布式的数据分布,后期的扩展就有问题了。
分布式列式数据库在ROLAP上应该是发展方向。
很好的讨论,坐等各位高手的意见。
关于列式数据库你知道多少?
存储结构不同,使用场景不同,老牌的数据库厂商目前只有sybase有很成熟的产品,并且有些成功案例。
你知道列式数据仓库是谁首创的吗?
目前声音最响的是sybase,谁首创真还不知道。
你知道全球有多少家列式数据库厂商?
Sybase是目前最大的一家,还有一些小的列式数据库厂商。
你知道列式数据库与传统行式数据库有什么不同吗?
主要是存储模式不同而导致查询效率、存储效率、索引模式等等方面都和传统行式数据库有很大差异。从列式数据库的实现Sybase IQ而言,相同的地方在于标准的借口和对SQL标准的支持。
你对列式数据库持什么样的看法呢?
目前主要应用于OLAP领域,包括查询、统计、报表、分析、历史数据存储等等方面,OLTP领域不适合。列式数据库应该是一个方向吧,目前Sybase IQ是一个影响最大的实现产品,期待其它DB巨头的表态,好像Oracle新版本也在准备支持,如果这样的话,应该是一个方向。
在BI系统中,一般批量ETL只是准备数据阶段,
在数据展现阶段还是会有大量的读操作。
当然,你也可以把数据展现交给OLAP SERVER去做,比如ESSBASE等。
但这样存在大量数据导入导出,构造CUBE等操作。
IQ当初的设计理念是
写节点处理批量ETL,读节点代替OLAP SERVER,直接支持各种报表类、分析类查询及ad-hoc查询。
因此,写节点需要高配置实现资源集中化,而读节点实现可扩展应付并发查询。
而且用读写节点物理分离的方式解决批处理与查询的资源竞争问题。
找了几条比较好的扫扫自己的盲点
本文转自My_King1 51CTO博客,原文链接:http://blog.51cto.com/apprentice/1360626,如需转载请自行联系原作者