之前一篇介绍过如何自定义实现拼音分词器,不过当初只考虑了全拼这种情况,且有些BUG,趁着抗日胜利70周年阅兵3天假期有时间,又把当初的代码拿起来进行了改进,改进点包括支持全拼,简拼以及全拼+简拼,支持汉字数字是否NGram处理的可配置,支持NGram长度范围的可配置等,特此更新此篇进行分享!如有不妥之处,还望不吝指正!
废话不多说,直接上代码:
Java代码

- import java.io.IOException;
- import java.util.ArrayList;
- import java.util.Collection;
- import java.util.Iterator;
- import org.apache.lucene.analysis.TokenFilter;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.pinyin.utils.Constant;
- import org.apache.lucene.analysis.pinyin.utils.Pinyin4jUtil;
- import org.apache.lucene.analysis.pinyin.utils.StringUtils;
- import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
- import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
- import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
- import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
- /**
- * 拼音过滤器[负责将汉字转换为拼音]
- * @author Lanxiaowei
- *
- */
- public class PinyinTokenFilter extends TokenFilter {
- /**是否输出原中文*/
- private boolean isOutChinese;
- /**是否只转换简拼*/
- private boolean shortPinyin;
- /**是否转换全拼+简拼*/
- private boolean pinyinAll;
- /**中文词组长度过滤,默认超过2位长度的中文才转换拼音*/
- private int minTermLength;
- /**词元输入缓存*/
- private char[] curTermBuffer;
- /**词元输入长度*/
- private int curTermLength;
- private final CharTermAttribute termAtt = (CharTermAttribute) addAttribute(CharTermAttribute.class);
- /**位置增量属性*/
- private final PositionIncrementAttribute posIncrAtt = addAttribute(PositionIncrementAttribute.class);
- private final TypeAttribute typeAtt = addAttribute(TypeAttribute.class);
- /**当前输入是否已输出*/
- private boolean hasCurOut;
- /**拼音结果集*/
- private Collection<String> terms;
- /**拼音结果集迭代器*/
- private Iterator<String> termIte;
- public PinyinTokenFilter(TokenStream input) {
- this(input,Constant.DEFAULT_MIN_TERM_LRNGTH);
- }
- public PinyinTokenFilter(TokenStream input, int minTermLength) {
- this(input, Constant.DEFAULT_SHORT_PINYIN, Constant.DEFAULT_PINYIN_ALL,minTermLength);
- }
- public PinyinTokenFilter(TokenStream input, boolean shortPinyin) {
- this(input, shortPinyin, Constant.DEFAULT_PINYIN_ALL);
- }
- public PinyinTokenFilter(TokenStream input, boolean shortPinyin,boolean pinyinAll) {
- this(input, shortPinyin,pinyinAll, Constant.DEFAULT_MIN_TERM_LRNGTH);
- }
- public PinyinTokenFilter(TokenStream input, boolean shortPinyin,boolean pinyinAll,int minTermLength) {
- this(input, shortPinyin,pinyinAll,Constant.DEFAULT_OUT_CHINESE, minTermLength);
- }
- public PinyinTokenFilter(TokenStream input, boolean shortPinyin,boolean pinyinAll,
- boolean isOutChinese,int minTermLength) {
- super(input);
- this.minTermLength = minTermLength;
- if (this.minTermLength < 1) {
- this.minTermLength = 1;
- }
- this.isOutChinese = isOutChinese;
- this.shortPinyin = shortPinyin;
- this.pinyinAll = pinyinAll;
- // 偏移量属性
- addAttribute(OffsetAttribute.class);
- }
- @Override
- public final boolean incrementToken() throws IOException {
- while (true) {
- // 开始处理或上一输入词元已被处理完成
- if (this.curTermBuffer == null) {
- // 获取下一词元输入
- if (!this.input.incrementToken()) {
- // 没有后继词元输入,处理完成,返回false,结束上层调用
- return false;
- }
- // 缓存词元输入
- this.curTermBuffer = ((char[]) this.termAtt.buffer().clone());
- this.curTermLength = this.termAtt.length();
- }
- String chinese = this.termAtt.toString();
- // 处理原输入词元
- if ((this.isOutChinese) && (!this.hasCurOut) && (this.termIte == null)) {
- // 准许输出原中文词元且当前没有输出原输入词元且还没有处理拼音结果集
- // 标记以保证下次循环不会输出
- this.hasCurOut = true;
- // 写入原输入词元
- this.termAtt.copyBuffer(this.curTermBuffer, 0,
- this.curTermLength);
- this.posIncrAtt.setPositionIncrement(this.posIncrAtt.getPositionIncrement());
- this.typeAtt.setType(StringUtils.isNumeric(chinese)? "numeric_original" :
- (StringUtils.containsChinese(chinese)?"chinese_original" : "normal_word"));
- return true;
- }
- String type = this.typeAtt.type();
- // 若包含中文且中文字符长度不小于限定的最小长度minTermLength
- if (StringUtils.chineseCharCount(chinese) >= this.minTermLength) {
- // 如果需要全拼+简拼
- if(this.pinyinAll) {
- Collection<String> quanpinColl = Pinyin4jUtil.getPinyinCollection(chinese);
- quanpinColl.addAll(Pinyin4jUtil.getPinyinShortCollection(chinese));
- this.terms = quanpinColl;
- } else {
- // 简拼 or 全拼,二选一
- this.terms = this.shortPinyin ?
- Pinyin4jUtil.getPinyinShortCollection(chinese) :
- Pinyin4jUtil.getPinyinCollection(chinese);
- }
- if (this.terms != null) {
- this.termIte = this.terms.iterator();
- }
- } else {
- if(null != type && ("numeric_original".equals(type) ||
- "normal_word".equals(type))) {
- Collection<String> coll = new ArrayList<String>();
- coll.add(chinese);
- this.terms = coll;
- if (this.terms != null) {
- this.termIte = this.terms.iterator();
- }
- }
- }
- if (this.termIte != null) {
- // 有拼音结果集且未处理完成
- while (this.termIte.hasNext()) {
- String pinyin = this.termIte.next();
- this.termAtt.copyBuffer(pinyin.toCharArray(), 0, pinyin.length());
- //同义词的原理
- this.posIncrAtt.setPositionIncrement(0);
- this.typeAtt.setType(this.shortPinyin ? "short_pinyin" : "pinyin");
- return true;
- }
- }
- // 没有中文或转换拼音失败,不用处理,
- // 清理缓存,下次取新词元
- this.curTermBuffer = null;
- this.termIte = null;
- this.hasCurOut = false;
- }
- }
- @Override
- public void reset() throws IOException {
- super.reset();
- }
- }
Java代码
- import java.io.IOException;
- import org.apache.lucene.analysis.TokenFilter;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.miscellaneous.CodepointCountFilter;
- import org.apache.lucene.analysis.pinyin.utils.Constant;
- import org.apache.lucene.analysis.pinyin.utils.StringUtils;
- import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
- import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
- import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
- import org.apache.lucene.analysis.tokenattributes.PositionLengthAttribute;
- import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
- import org.apache.lucene.analysis.util.CharacterUtils;
- /**
- * 对转换后的拼音进行NGram处理的TokenFilter
- *
- * @author Lanxiaowei
- *
- */
- @SuppressWarnings("unused")
- public class PinyinNGramTokenFilter extends TokenFilter {
- private char[] curTermBuffer;
- private int curTermLength;
- private int curCodePointCount;
- private int curGramSize;
- private int curPos;
- private int curPosInc, curPosLen;
- private int tokStart;
- private int tokEnd;
- private boolean hasIllegalOffsets;
- private int minGram;
- private int maxGram;
- /** 是否需要对中文进行NGram[默认为false] */
- private final boolean nGramChinese;
- /** 是否需要对纯数字进行NGram[默认为false] */
- private final boolean nGramNumber;
- private final CharacterUtils charUtils;
- private CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
- private PositionIncrementAttribute posIncAtt;
- private PositionLengthAttribute posLenAtt;
- private OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
- private TypeAttribute typeAtt;
- public PinyinNGramTokenFilter(TokenStream input, int minGram, int maxGram,
- boolean nGramChinese,boolean nGramNumber) {
- super(new CodepointCountFilter(input, minGram, Integer.MAX_VALUE));
- this.charUtils = CharacterUtils.getInstance();
- if (minGram < 1) {
- throw new IllegalArgumentException(
- "minGram must be greater than zero");
- }
- if (minGram > maxGram) {
- throw new IllegalArgumentException(
- "minGram must not be greater than maxGram");
- }
- this.minGram = minGram;
- this.maxGram = maxGram;
- this.nGramChinese = nGramChinese;
- this.nGramNumber = nGramNumber;
- this.termAtt = addAttribute(CharTermAttribute.class);
- this.offsetAtt = addAttribute(OffsetAttribute.class);
- this.typeAtt = addAttribute(TypeAttribute.class);
- this.posIncAtt = addAttribute(PositionIncrementAttribute.class);
- this.posLenAtt = addAttribute(PositionLengthAttribute.class);
- }
- public PinyinNGramTokenFilter(TokenStream input, int minGram, int maxGram,
- boolean nGramChinese) {
- this(input, minGram, maxGram, nGramChinese, Constant.DEFAULT_NGRAM_NUMBER);
- }
- public PinyinNGramTokenFilter(TokenStream input, int minGram, int maxGram) {
- this(input, minGram, maxGram, Constant.DEFAULT_NGRAM_CHINESE);
- }
- public PinyinNGramTokenFilter(TokenStream input, int minGram) {
- this(input, minGram, Constant.DEFAULT_MAX_GRAM);
- }
- public PinyinNGramTokenFilter(TokenStream input) {
- this(input, Constant.DEFAULT_MIN_GRAM);
- }
- @Override
- public final boolean incrementToken() throws IOException {
- while (true) {
- if (curTermBuffer == null) {
- if (!input.incrementToken()) {
- return false;
- }
- String type = this.typeAtt.type();
- if(null != type && "normal_word".equals(type)) {
- return true;
- }
- if(null != type && "numeric_original".equals(type)) {
- return true;
- }
- if(null != type && "chinese_original".equals(type)) {
- return true;
- }
- if ((!this.nGramNumber)
- && (StringUtils.isNumeric(this.termAtt.toString()))) {
- return true;
- }
- if ((!this.nGramChinese)
- && (StringUtils.containsChinese(this.termAtt.toString()))) {
- return true;
- }
- curTermBuffer = termAtt.buffer().clone();
- curTermLength = termAtt.length();
- curCodePointCount = charUtils.codePointCount(termAtt);
- curGramSize = minGram;
- curPos = 0;
- curPosInc = posIncAtt.getPositionIncrement();
- curPosLen = posLenAtt.getPositionLength();
- tokStart = offsetAtt.startOffset();
- tokEnd = offsetAtt.endOffset();
- hasIllegalOffsets = (tokStart + curTermLength) != tokEnd;
- }
- if (curGramSize > maxGram
- || (curPos + curGramSize) > curCodePointCount) {
- ++curPos;
- curGramSize = minGram;
- }
- if ((curPos + curGramSize) <= curCodePointCount) {
- clearAttributes();
- final int start = charUtils.offsetByCodePoints(curTermBuffer,
- 0, curTermLength, 0, curPos);
- final int end = charUtils.offsetByCodePoints(curTermBuffer, 0,
- curTermLength, start, curGramSize);
- termAtt.copyBuffer(curTermBuffer, start, end - start);
- posIncAtt.setPositionIncrement(curPosInc);
- curPosInc = 0;
- posLenAtt.setPositionLength(curPosLen);
- offsetAtt.setOffset(tokStart, tokEnd);
- curGramSize++;
- return true;
- }
- curTermBuffer = null;
- }
- }
- @Override
- public void reset() throws IOException {
- super.reset();
- curTermBuffer = null;
- }
- }
Java代码
- import java.io.IOException;
- import org.apache.lucene.analysis.TokenFilter;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.pinyin.utils.Constant;
- import org.apache.lucene.analysis.pinyin.utils.StringUtils;
- import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
- import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
- import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
- import org.apache.lucene.analysis.tokenattributes.PositionLengthAttribute;
- import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
- import org.apache.lucene.analysis.util.CharacterUtils;
- /**
- * 对转换后的拼音进行EdgeNGram处理的TokenFilter
- *
- * @author Lanxiaowei
- *
- */
- public class PinyinEdgeNGramTokenFilter extends TokenFilter {
- private final int minGram;
- private final int maxGram;
- /** 是否需要对中文进行NGram[默认为false] */
- private final boolean nGramChinese;
- /** 是否需要对纯数字进行NGram[默认为false] */
- private final boolean nGramNumber;
- private final CharacterUtils charUtils;
- private char[] curTermBuffer;
- private int curTermLength;
- private int curCodePointCount;
- private int curGramSize;
- private int tokStart;
- private int tokEnd;
- private int savePosIncr;
- private int savePosLen;
- private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
- private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
- private final PositionIncrementAttribute posIncrAtt = addAttribute(PositionIncrementAttribute.class);
- private final PositionLengthAttribute posLenAtt = addAttribute(PositionLengthAttribute.class);
- private TypeAttribute typeAtt = addAttribute(TypeAttribute.class);
- public PinyinEdgeNGramTokenFilter(TokenStream input, int minGram,
- int maxGram, boolean nGramChinese, boolean nGramNumber) {
- super(input);
- if (minGram < 1) {
- throw new IllegalArgumentException(
- "minGram must be greater than zero");
- }
- if (minGram > maxGram) {
- throw new IllegalArgumentException(
- "minGram must not be greater than maxGram");
- }
- this.charUtils = CharacterUtils.getInstance();
- this.minGram = minGram;
- this.maxGram = maxGram;
- this.nGramChinese = nGramChinese;
- this.nGramNumber = nGramNumber;
- }
- public PinyinEdgeNGramTokenFilter(TokenStream input, int minGram,
- int maxGram, boolean nGramChinese) {
- this(input, minGram, maxGram, nGramChinese, Constant.DEFAULT_NGRAM_NUMBER);
- }
- public PinyinEdgeNGramTokenFilter(TokenStream input, int minGram,
- int maxGram) {
- this(input, minGram, maxGram, Constant.DEFAULT_NGRAM_CHINESE);
- }
- public PinyinEdgeNGramTokenFilter(TokenStream input, int minGram) {
- this(input, minGram, Constant.DEFAULT_MAX_GRAM);
- }
- public PinyinEdgeNGramTokenFilter(TokenStream input) {
- this(input, Constant.DEFAULT_MIN_GRAM);
- }
- @Override
- public final boolean incrementToken() throws IOException {
- while (true) {
- if (curTermBuffer == null) {
- if (!input.incrementToken()) {
- return false;
- }
- String type = this.typeAtt.type();
- if(null != type && "normal_word".equals(type)) {
- return true;
- }
- if(null != type && "numeric_original".equals(type)) {
- return true;
- }
- if(null != type && "chinese_original".equals(type)) {
- return true;
- }
- if ((!this.nGramNumber)
- && (StringUtils.isNumeric(this.termAtt.toString()))) {
- return true;
- }
- if ((!this.nGramChinese)
- && (StringUtils.containsChinese(this.termAtt.toString()))) {
- return true;
- }
- curTermBuffer = termAtt.buffer().clone();
- curTermLength = termAtt.length();
- curCodePointCount = charUtils.codePointCount(termAtt);
- curGramSize = minGram;
- tokStart = offsetAtt.startOffset();
- tokEnd = offsetAtt.endOffset();
- savePosIncr += posIncrAtt.getPositionIncrement();
- savePosLen = posLenAtt.getPositionLength();
- }
- if (curGramSize <= maxGram) {
- if (curGramSize <= curCodePointCount) {
- clearAttributes();
- offsetAtt.setOffset(tokStart, tokEnd);
- if (curGramSize == minGram) {
- posIncrAtt.setPositionIncrement(savePosIncr);
- savePosIncr = 0;
- } else {
- posIncrAtt.setPositionIncrement(0);
- }
- posLenAtt.setPositionLength(savePosLen);
- final int charLength = charUtils.offsetByCodePoints(
- curTermBuffer, 0, curTermLength, 0, curGramSize);
- termAtt.copyBuffer(curTermBuffer, 0, charLength);
- curGramSize++;
- return true;
- }
- }
- curTermBuffer = null;
- }
- }
- @Override
- public void reset() throws IOException {
- super.reset();
- curTermBuffer = null;
- savePosIncr = 0;
- }
- }
Java代码
- package org.apache.lucene.analysis.pinyin.lucene5;
- import java.io.BufferedReader;
- import java.io.Reader;
- import java.io.StringReader;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.Tokenizer;
- import org.apache.lucene.analysis.pinyin.utils.Constant;
- import org.wltea.analyzer.lucene.IKTokenizer;
- /**
- * 自定义拼音分词器
- * @author Lanxiaowei
- *
- */
- public class PinyinAnalyzer extends Analyzer {
- private int minGram;
- private int maxGram;
- private boolean useSmart;
- /** 是否需要对中文进行NGram[默认为false] */
- private boolean nGramChinese;
- /** 是否需要对纯数字进行NGram[默认为false] */
- private boolean nGramNumber;
- /**是否开启edgesNGram模式*/
- private boolean edgesNGram;
- public PinyinAnalyzer() {
- this(Constant.DEFAULT_IK_USE_SMART);
- }
- public PinyinAnalyzer(boolean useSmart) {
- this(Constant.DEFAULT_MIN_GRAM, Constant.DEFAULT_MAX_GRAM, Constant.DEFAULT_EDGES_GRAM, useSmart,Constant.DEFAULT_NGRAM_CHINESE);
- }
- public PinyinAnalyzer(int minGram) {
- this(minGram, Constant.DEFAULT_MAX_GRAM, Constant.DEFAULT_EDGES_GRAM, Constant.DEFAULT_IK_USE_SMART, Constant.DEFAULT_NGRAM_CHINESE,Constant.DEFAULT_NGRAM_NUMBER);
- }
- public PinyinAnalyzer(int minGram,boolean useSmart) {
- this(minGram, Constant.DEFAULT_MAX_GRAM, Constant.DEFAULT_EDGES_GRAM, useSmart,Constant.DEFAULT_NGRAM_CHINESE);
- }
- public PinyinAnalyzer(int minGram, int maxGram) {
- this(minGram, maxGram, Constant.DEFAULT_EDGES_GRAM);
- }
- public PinyinAnalyzer(int minGram, int maxGram,boolean edgesNGram) {
- this(minGram, maxGram, edgesNGram, Constant.DEFAULT_IK_USE_SMART);
- }
- public PinyinAnalyzer(int minGram, int maxGram,boolean edgesNGram,boolean useSmart) {
- this(minGram, maxGram, edgesNGram, useSmart,Constant.DEFAULT_NGRAM_CHINESE);
- }
- public PinyinAnalyzer(int minGram, int maxGram,boolean edgesNGram,boolean useSmart,
- boolean nGramChinese) {
- this(minGram, maxGram, edgesNGram, useSmart,nGramChinese,Constant.DEFAULT_NGRAM_NUMBER);
- }
- public PinyinAnalyzer(int minGram, int maxGram,boolean edgesNGram,boolean useSmart,
- boolean nGramChinese,boolean nGramNumber) {
- super();
- this.minGram = minGram;
- this.maxGram = maxGram;
- this.edgesNGram = edgesNGram;
- this.useSmart = useSmart;
- this.nGramChinese = nGramChinese;
- this.nGramNumber = nGramNumber;
- }
- @Override
- protected TokenStreamComponents createComponents(String fieldName) {
- Reader reader = new BufferedReader(new StringReader(fieldName));
- Tokenizer tokenizer = new IKTokenizer(reader, useSmart);
- //转拼音
- TokenStream tokenStream = new PinyinTokenFilter(tokenizer,
- Constant.DEFAULT_SHORT_PINYIN,Constant.DEFAULT_PINYIN_ALL, Constant.DEFAULT_MIN_TERM_LRNGTH);
- //对拼音进行NGram处理
- if(edgesNGram) {
- tokenStream = new PinyinEdgeNGramTokenFilter(tokenStream,this.minGram,
- this.maxGram,this.nGramChinese,this.nGramNumber);
- } else {
- tokenStream = new PinyinNGramTokenFilter(tokenStream,this.minGram,
- this.maxGram,this.nGramChinese,this.nGramNumber);
- }
- return new Analyzer.TokenStreamComponents(tokenizer, tokenStream);
- }
- }
Lucene5中PinyinAnalyzer分词器使用示例代码如下:
Java代码
- import java.io.IOException;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
- import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
- import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
- import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
- import org.wltea.analyzer.lucene.IKAnalyzer;
- import com.yida.framework.lucene5.pinyin.PinyinAnalyzer;
- @SuppressWarnings("resource")
- public class AnalyzerTest {
- public static void main(String[] args) throws IOException {
- String s = "京华时报2009年1月23日报道 the this that welcome to beijing 虽然我很丑,但是我很温柔,昨天,受一股来自中西伯利亚的强冷空气影响,本市出现大风降温天气,白天最高气温只有零下7摄氏度,同时伴有6到7级的偏北风。";
- //Analyzer analyzer = new IKAnalyzer();
- Analyzer analyzer = new PinyinAnalyzer();
- TokenStream tokenStream = analyzer.tokenStream("text", s);
- displayTokens(tokenStream);
- }
- public static void displayTokens(TokenStream tokenStream) throws IOException {
- OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
- PositionIncrementAttribute positionIncrementAttribute = tokenStream.addAttribute(PositionIncrementAttribute.class);
- CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
- TypeAttribute typeAttribute = tokenStream.addAttribute(TypeAttribute.class);
- tokenStream.reset();
- int position = 0;
- while (tokenStream.incrementToken()) {
- int increment = positionIncrementAttribute.getPositionIncrement();
- if(increment > 0) {
- position = position + increment;
- System.out.print(position + ":");
- }
- int startOffset = offsetAttribute.startOffset();
- int endOffset = offsetAttribute.endOffset();
- String term = charTermAttribute.toString();
- System.out.println("[" + term + "]" + ":(" + startOffset + "-->" + endOffset + "):" + typeAttribute.type());
- }
- tokenStream.end();
- tokenStream.close();
- }
- }
Java代码
- package org.apache.lucene.analysis.pinyin.solr5;
- import java.util.Map;
- import org.apache.lucene.analysis.TokenFilter;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.pinyin.lucene5.PinyinTokenFilter;
- import org.apache.lucene.analysis.pinyin.utils.Constant;
- import org.apache.lucene.analysis.util.TokenFilterFactory;
- /**
- * PinyinTokenFilter工厂类
- * @author Lanxiaowei
- *
- */
- public class PinyinTokenFilterFactory extends TokenFilterFactory {
- /**是否输出原中文*/
- private boolean outChinese;
- /**是否只转换简拼*/
- private boolean shortPinyin;
- /**是否转换全拼+简拼*/
- private boolean pinyinAll;
- /**中文词组长度过滤,默认超过minTermLength长度的中文才转换拼音*/
- private int minTermLength;
- public PinyinTokenFilterFactory(Map<String, String> args) {
- super(args);
- this.outChinese = getBoolean(args, "outChinese", Constant.DEFAULT_OUT_CHINESE);
- this.shortPinyin = getBoolean(args, "shortPinyin", Constant.DEFAULT_SHORT_PINYIN);
- this.pinyinAll = getBoolean(args, "pinyinAll", Constant.DEFAULT_PINYIN_ALL);
- this.minTermLength = getInt(args, "minTermLength", Constant.DEFAULT_MIN_TERM_LRNGTH);
- }
- public TokenFilter create(TokenStream input) {
- return new PinyinTokenFilter(input, this.shortPinyin,this.outChinese,
- this.minTermLength);
- }
- public boolean isOutChinese() {
- return outChinese;
- }
- public void setOutChinese(boolean outChinese) {
- this.outChinese = outChinese;
- }
- public boolean isShortPinyin() {
- return shortPinyin;
- }
- public void setShortPinyin(boolean shortPinyin) {
- this.shortPinyin = shortPinyin;
- }
- public boolean isPinyinAll() {
- return pinyinAll;
- }
- public void setPinyinAll(boolean pinyinAll) {
- this.pinyinAll = pinyinAll;
- }
- public int getMinTermLength() {
- return minTermLength;
- }
- public void setMinTermLength(int minTermLength) {
- this.minTermLength = minTermLength;
- }
- }
Java代码
- import java.util.Map;
- import org.apache.lucene.analysis.TokenFilter;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.pinyin.lucene5.PinyinEdgeNGramTokenFilter;
- import org.apache.lucene.analysis.pinyin.lucene5.PinyinNGramTokenFilter;
- import org.apache.lucene.analysis.pinyin.utils.Constant;
- import org.apache.lucene.analysis.util.TokenFilterFactory;
- /**
- * PinyinNGramTokenFilter工厂类
- * @author Lanxiaowei
- *
- */
- public class PinyinNGramTokenFilterFactory extends TokenFilterFactory {
- private int minGram;
- private int maxGram;
- /** 是否需要对中文进行NGram[默认为false] */
- private boolean nGramChinese;
- /** 是否需要对纯数字进行NGram[默认为false] */
- private boolean nGramNumber;
- /**是否开启edgesNGram模式*/
- private boolean edgesNGram;
- public PinyinNGramTokenFilterFactory(Map<String, String> args) {
- super(args);
- this.minGram = getInt(args, "minGram", Constant.DEFAULT_MIN_GRAM);
- this.maxGram = getInt(args, "maxGram", Constant.DEFAULT_MAX_GRAM);
- this.edgesNGram = getBoolean(args, "edgesNGram", Constant.DEFAULT_EDGES_GRAM);
- this.nGramChinese = getBoolean(args, "nGramChinese", Constant.DEFAULT_NGRAM_CHINESE);
- this.nGramNumber = getBoolean(args, "nGramNumber", Constant.DEFAULT_NGRAM_NUMBER);
- }
- public TokenFilter create(TokenStream input) {
- if(edgesNGram) {
- return new PinyinEdgeNGramTokenFilter(input, this.minGram, this.maxGram,
- this.nGramChinese, this.nGramNumber);
- }
- return new PinyinNGramTokenFilter(input, this.minGram, this.maxGram,
- this.nGramChinese,this.nGramNumber);
- }
- }
我已经将他们打包成了两个jar包:lucene-analyzer-pinyin.5.1.0.jar和solr-analyzer-pinyin.5.1.0.jar(这两个jar包我已经上传到最底下的附件里,特此提醒!!!),只需要把这两个jar放入core的lib目录下,如图:
然后在schema.xml中添加拼音分词的域类型,如图:
然后如图应用定义好的text_pinyin这个域类型,看图:
然后你就可以启动你的tomcat部署solr,进行拼音分词测试了:
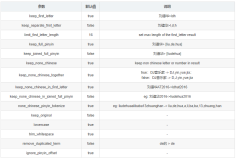
如果你看到如图效果,表明拼音分词已经部署成功且测试成功!如果你有任何疑问,请联系我!我的联系方式请查阅我之前的博客,打完收工,谢谢!就此晚安啦!
转载:http://iamyida.iteye.com/blog/2240657