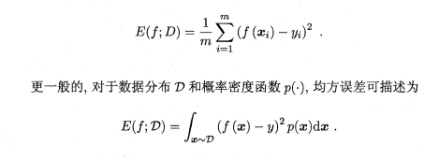Machine Learning是近来计算机科学的热点,作为一个计算机行业从业者,似乎不提ML都不好意思出门了。那么系统软件能否和ML搭上边呢?最近的一篇paper让我们脑洞大开,而Jeff Dean的Machine Learning for Systems and Systems for Machine Learning报告更是展示了系统软件发展无限的想象空间。也许未来系统软件工程师要不转行做ML,要不就失业了。。。我们需要拥抱变化了!
作者简介
朱延海,刘峥,Linux系统工程师,来自阿里云系统组。
本文中若有任何疏漏错误,有任何建议和意见,请回复内核月谈微信公众号,或通过zhu.yanhai at linux.alibaba.com或者 tao.ma at linux.alibaba.com反馈。
阿里云系统团队,是由原淘宝内核组扩建而成,2013年淘宝内核组响应阿里巴巴集团的号召,整建制转入阿里云,开始为云计算底层系统构建完善的系统支持。 阿里云系统团队是由一群具有高度使命感和自我追求的内核开发人员组成,团队中的大多数人,都是活跃的社区内核开发人员。目前的工作领域主要涉及(但不限于) Linux内核的内存管理、文件系统、网络和内核维护构建,以及和内核相关联的用户态库和工具。如果你对我们的工作很感兴趣,欢迎加入我们,请将简历发送至 tao.ma at linux.alibaba.com或者 boyu.mt at alibaba-inc.com。
原始论文链接:https://www.arxiv-vanity.com/papers/1712.01208v1/ The Morning Paper上的评论:https://blog.acolyer.org/2018/01/08/the-case-for-learned-index-structures-part-i/
概述
Learned Index Structure巧妙地把传统数据库系统研究和最新的机器学习技术结合起来,这很可能预示着未来的系统软件研究方向。本文首先简要概述这篇文章的核心想法,然后再深入其各种细节。
我们认为这篇文章中最有趣的一点是它为系统优化提供了一种全新的思路:结合被处理对象的分布情况做优化。尽管文章中提出的当前实现方法仍然还有许多限制,但其结果已经相当有吸引力:约70%的速度提升,同时节省一个数量级的存储空间。如果你觉得这个结果仍然不够好,请注意参与比较的那些传统算法已经经过了几十年的持续优化,能在此基础上再进一步相当不易。
“…we believe that the idea of replacing core components of a data management system through learned models has far reaching implications for future systems designs and that this work just provides a glimpse of what might be possible.”
在系统软件中使用基于机器学习得到的数据结构来替代纯粹由程序员设计的数据结构到底意味着什么呢?我们能想到的与此最相近的场景就是互联网服务商的各种个性化推荐,在互联网发展的早期,不管你是一个什么样的用户,电商、博客、新闻、音乐网站给你看到的内容都是一模一样的,它们并不在乎你到底喜欢什么。然而今天,几乎所有的网站都在收集用户行为,根据猜测到的用户喜好去推荐相应内容。类似地,对于系统软件来说,任务负载的数据分布还有它的访问行为模式就是系统软件的用户特征,也许未来的系统软件程序员也会说:“早期的系统软件程序员对于所有的负载都使用相同的配置、数据结构还有算法,然而今天我们会为每一种特定的负载做自动优化”
由程序员手工实现此类优化显然成本过高并不现实,它需要一种在线的机器学习机制,正如论文的作者所说
“the engineering effort to build specialized solutions for every use case is usually too high… machine learning opens up the opportunity to learn a model that reflects the patterns and correlations in the data.”
在本篇论文中,此类自动优化的方法被应用到了定制化的数据结构中,作者把它们称为learned indexes。
CPU、GPU和TPU
本篇文章所介绍的方法是在CPU上实现的。一但它们被移植到GPU甚至TPU上实现,其程度提升将更为可观。与CPU的速度提升已经趋于停滞相对应的是,Nvidia预测到2025年时GPU的速度将是现在的1000倍,这使得本文所介绍的方法更具吸引力,因为此类基于深度神经网络的方法在“扮演”索引结构时只是在做网络推断,也即一连串的矩阵运算,可以免费享用到上述GPU速度提升带来的红利。而传统的索引算法,如B树、哈希表等等具有鲜明的串行特征,很难充分利用GPU的计算能力。
Learned (range) indexes
本篇文章提出的这些新方法主要是针对常驻内存且只读的数据索引场景而提出的(作者在后边也对数据结构的修改需求提出了一些简单的解法,但如果应用场景要求数据结构必须频繁修改的话肯定不适用本文的方法)。
典型的Range index就是经典B树,向B树输入一个Key,B树会输出这个Key对应的数据在一个有序序列中的偏移。通常B树的最末一级索引会指向一个有序小数据集——通常是一个page——的第一个元素,最终的搜索通过在这个小数据集里顺序查找或者二分查找完成。B树会保证如果树中确实存在查找的那个key,那么你拿着这个key一路找下去,最终一定能在它指向的那个page里找到这个key。我们可以把B树视为一个从key映射到偏移的函数,并且其输出带有error bound(误差界)保证(即最大误差小于等于一个page的大小,确切地说,其估计值只会大于等于真实值,不会小于真实值)。可以证明深度神经网能够拟合任意一个函数,因此大致上可以让它扮演一个B树的角色,这并不难,难点在于error bound的处理。
“At first sight it may be hard to provide the same error guarantees with other types of ML models, but it is actually surprisingly simple. The B-tree only provides this guarantee over the stored data, not for all possible data. For new data, B-Trees need to be re-balanced, or in machine learning terminology re-trained, to still be able to provide the same error guarantees. This significantly simplifies the problem: the min- and max-error is the maximum error of the model over the training (i.e. the stored) data.”
初看起来似乎很难:一个深度神经网络的拟合精度很难像B树那样得到完美控制,然而作者采取了一种相当机智的办法。首先,作者注意到B树只对存在于树中的key有误差界保证(回忆我们使用B树的过程,会一级一级找到最后一个page,然后在page里查找确认key是否存在)。因此当一个DNN网络训练结束后,我们可以把期待由它索引的那些key逐一输入给它,同时记录其输出的估计偏移与真实偏移之间的最大正负误差。随后使用时我们就可以说当给定一个key时,其真实偏移一定会落在网络输出值 ± 正负最大误差范围内。只要在此范围内做顺序查找或者二分查找即可。反过来我们也可以确信如果没有找到,那么这个key一定不在B树中。这就从理论上完全解决了使用网络拟合B树的问题,并且把原本时间复杂度为O(log n)的B树查找过程变成了O(1)的过程。
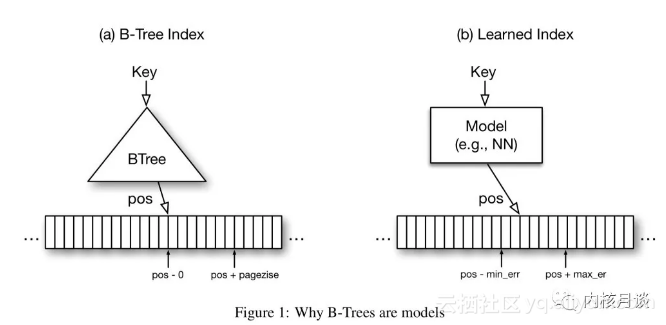
或者我们也可以换一个角度来看待B树:给定一个key,去预测其在一个有序数列中的偏移的模型,本质上其实是在刻画这些偏移的累积概率密度分布(CDF)
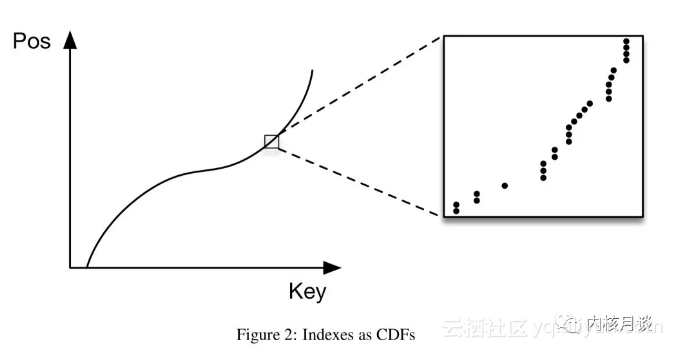
而估计一个数据集的CDF并不是什么新鲜的话题,learned index可以从过去几十年的研究中得到很多经验。
下边我们来简单考察一下此种方法的性能。
遍历一个有100个元素的B树结点大约需要花50个时钟周期,为了在一个有N个Key的B树中定位一个page,我们需要log100N次这种遍历。与之相对的是,在Nvida最新的Tesla V100 GPU上,每30个时钟周期可以执行一百万次神经网络操作。
作者首先用Tensorflow给出了一个朴素的原型实现,由两层全连接、每层32个神经元的单个网络来拟合一整棵B树。其查询速度是1250QPS,而作者的机器上传统B树的速度是它的两到三倍。慢在哪里了呢?
-
调用Tensorflow的额外开销太大,特别是从Python发起调用时(这是纯粹的工程问题,网络的推断过程要远比训练简单,可以通过将训练好的网络权重输出,然后用C/C++重写推断过程来解决)
-
按机器学习的说法,对于每一个Key,或者说采样点,B树都是严重过拟合的。它追求的是让其输出的偏移精确贴合真实偏移,误差不超过一个page。然而通过训练得到的CDF函数是一个回归过程,它实际上正在试图对样本偏移的分布进行泛化,这要求网络只能大概地给出一个偏移的位置,而不是精确地走完“最后一公里”,换句话说对于每一个独立数据点就不会贴合得那么好。这并不是在这个场景里我们想要的:我们完全没有兴趣去预测如果日后新添加一些Key,它可能的偏移会是什么样的,我们追求的恰恰正是传统DNN训练中竭力避免的事情——过拟合,完全丢掉网络的泛化、预测能力。
-
传统DNN训练中的目标一般是最小化平均误差,比如最小化误差的平方和。而我们这里追求的实际上是最小化最大误差。
-
B树本身的实现一般针对Cache做了高度优化,标准的神经网络实现在这方面考虑较少。
为了克服上述缺点,作者提出了Learning index framework框架(LIF)。接下来我们将详细考察这个框架,并且讨论作者提出的另外两种索引:learned point index(用来代替哈希表)和learned existence index(用来代替Bloom filter)
改进learned (range) index
本文开头时已经提过,最终得到的测试结果新方法的速度是B树的三倍,同时空间占用最高下降了一个数量级。而上一小节的原型速度是B树的二分之一至三分之一。这里都需要哪些优化呢?
recursive regression model (递归回归模型)
正如我们之前所说,由一个网络去拟合B树,或者说拟合CDF,其难度较高。而如果只是用来拟合一层B树结点,那就要简单得多。这就是作者提出的recursive regression model (递归回归模型)。
“…we build a hierarchy of models, where at each stage the model takes the key as an input and based on it picks another model, until the final stage predicts the position.”
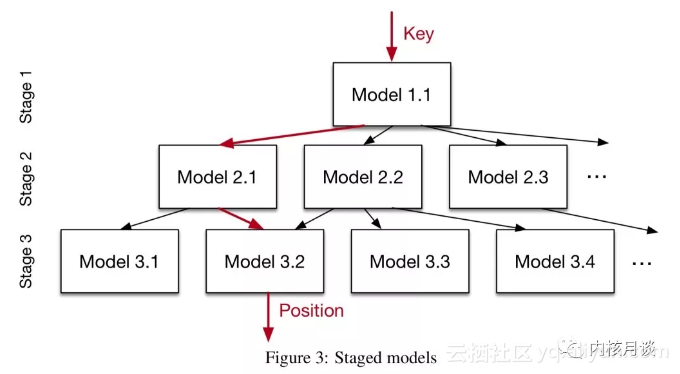
注意这里的stage与B树的层次并不是一一对应的。另外,这些stage构成的是一个有向无环图,不是一棵树——同一层stage上的不同模型有可能指向下一层的同一个模型。另外,这些模型也并不试图把key空间做均匀划分。在不同的stage上我们还可以使用不同的模型结构
“For example, whereas on the top-layer a small ReLU neural net might be the best choice as they are usually able to learn a wide-range of complex data distributions, the models at the bottom of the hierarchy might be thousands of simple linear regression models as they are inexpensive in space and execution time.”
整个索引(全体stage,论文中把它叫做Recursive Model Index,缩写RMI)过程可以用一个稀疏矩阵的乘法来表示。其构建过程可以在给定需要存储的数据、stage数、每个stage的模型数量、模型结构之后自动完成,见原始论文的3.3小节。
RMI的输出是一个Page,在对于数据分布没有任何先验知识的情况下,传统做法对这个page要么就顺序遍历,要么二分查找来找出最终的数据位置。然而……
“Yet again, learned indexes might have an advantage here as well: the models actually predict the position of the key, which likely to be much closer to the actual position of the record, while the min- and max-error is presumably larger.”
就是说,尽管RMI推测的位置可能并不精确,但它仍然有很大可能是在精确的位置附近的,如果一味地从page的起始位置开始搜索,这个信息就被浪费了。根据这个现象,作者提出了一种新的搜索方法,在page中取三个点,分别是、、,这里的就是RMI的推测位置,这三个点把page分成四份,由于page里的Key是有序的,用三个点上的key与正在查找的Key做比较就可以知道我们想要的点在这四份中的哪一份上。接下来再在这一份里做顺序查找。
在论文的评估阶段,作者使用了三个真实世界的数据集(每个最多200万行)。作者为每个数据集使用了一个高度优化过的B树实现,选择了五种page大小;在RMI模型这一边,作者试验了多种stage大小,10K、50K、100K、200K。每次训练RMI模型仅需要几秒钟。结果如图所示。
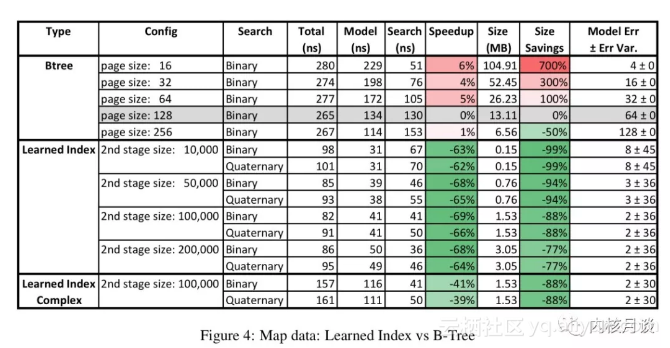
RMI模型在速度上全面优于B树,且占用更少的空间。其他数据集也有类似结果,此处不再赘述,感兴趣的读者可以参考原始论文的图5、图6。
值得注意的是,对于一些需要定期更新的数据结构,RMI可能也同样适用。特别是新数据依然大致服从旧数据的分布规律时。如果分布确实改变了,那么要么就彻底地重新训练,要么可以建立一个delta index来临时描述其中的差异。
Learned point indexes
前面我们以B树为例子,考察了range index,下边以哈希表为例讨论point index。
对于哈希表来说,最需要注意的事情就是减少哈希冲突。例如,有100万个记录要哈希到100万个slot上,大致来说会有33%的概率出现哈希冲突。实践中出现哈希冲突时一般就是通过在冲突链表中顺序查找来找到正确的key。
“Therefore, most solutions often allocate significantly more memory (i.e., slots) than records to store… For example, it is reported that Google’s Dense-hashmap has a typical overhead of about 78% of memory.”
为了降低哈希冲突,通常的哈希实现往往倾向于预分配比实际数据要多得多的slot来存储它们。如果不考虑内存空间消耗,那么本文这些learned index在速度上是不可能超过传统哈希表的,毕竟哈希表需要的计算实在太少了。然而如果要求哈希表占用的空间尽可能少,甚至要求slot数量和实际数据的数量一致,那么这时learned index就可能做得比传统哈希表要好(因为这时随着slot减少,传统哈希表的哈希冲突开始上升)
“Surprisingly, learning the CDF of the key distribution is one potential way to learn a better hash function… we can scale the CDF by the targeted size M of the hash-map and us h(K) = F(K)*M, with key K as our hash-function. If the model F perfectly learned the CDF, no conflicts would exist.”
把index考虑成一种CDF的想法在这里非常有用,如果我们可以完美地拟合index,那么直接把CDF映射到slots上,就得到了一个几乎完全没有冲突的hash函数。作者设计的对比试验包含了一个有两个stage的RMI,其中第二层stage有10万个模型。哈希表使用3次移位、3次异或及2次乘法。结果如下
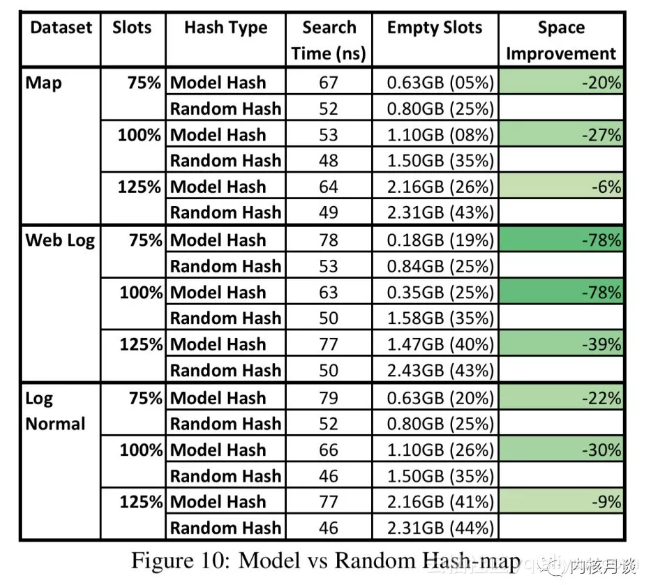
可见RMI与传统哈希表有相似的性能,但空间占用明显优于传统哈希表。
Learned existence index
典型的existence index就是bloom filter,用来判断一个key在数据集中存在与否。Bloom filter会确保没有假阴性结果(false negative),即是说如果bloom filter说这数据存在,那它不一定存在;如果bloom filter说这数据不存在,那么它一定不存在。Bloom filter本身占的空间较小,然而这里仍然还是有提升的空间。对于一个100万条记录、要求假阳性率小于0.1%的bloom filter,其所额外占用的空间会达到数据本身的14倍。
“… if there is some structure to determine what is inside versus outside the set, which can be learned, it might be possible to construct more efficient representations.”
用机器学习术语来说,bloom filter实际上是一个分类器,输出一个给定的key存在于数据集中的概率。我们可以给这个概率设定一个阈值,高于此阈值就认为key存在于数据集中。然而,不同于bloom filter,我们不能确保低于此概率时key就一定不存在。解决办法也很简单,为那些训练过程中出现的假阴性结果(即那些模型给出的概率低于阈值,模型认为它们不存在,然而实际上确实存在于数据集中的key)单独构建一个传统bloom filter。在工作中,如果模型给出的概率高于阈值,我们就报告这个key存在,如果低于阈值,就把它送到这个小bloom filter中再过一遍,如果给出的结果是仍然不存在,那么就一定不存在,否则报告存在。
作者使用了一个有170万条URL记录的数据集进行试验,作者训练了一个GNU-RNN来做为分类器。与传统bloom filter相比,当假阳性率小于1%时,新方法节省了47%的内存空间;当假阳性率小于0.01%时,新方法节省了28%的内存空间。
总的来说,模型分类得越精确,新方法节省的空间就越大。因此我们可以结合数据集的业务特点来进一步提升分类的准确度,比如针对URL采用WHOIS数据进行训练。
结语
“…we have demonstrated that machine learned models have the potential to provide significant benefits over state-of-the-art database indexes, and we believe this is a fruitful direction for future research.”
正如Jeff Dean在Machine Learning for Systems and Systems for Machine Learning报告中所说,大量传统系统软件都有结合实际业务特点进行在线自动优化的潜力,我们需要拥抱变化了。
原文发布时间为:2018-02-12
本文作者:朱延海 刘峥