摘要:在2017年云栖大会•北京峰会的大数据专场中,来自阿里云的高级技术专家李雪峰带来了主题为《金融级别大数据平台的多租户隔离实践》的演讲。在分享中,李雪峰首先介绍了基于传统IaaS单租户架构做隔离时面临的问题;然后,他重点分享了MaxCompute PaaS层面的多租户的架构以及MaxCompute在安全隔离方面的具体实践。
IaaS单租户大数据产品架构
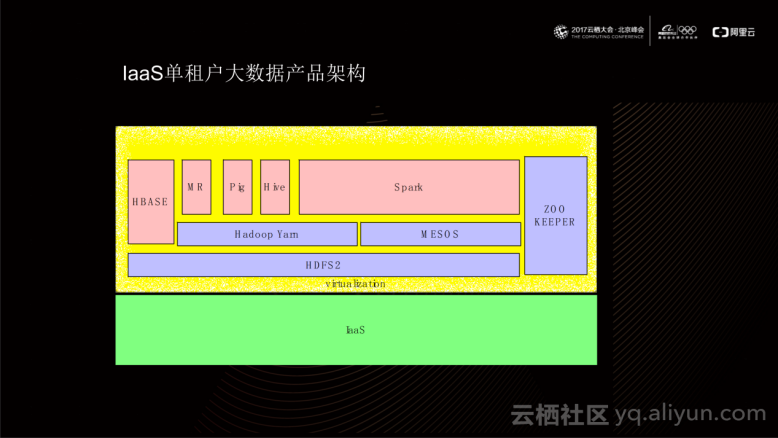
基于IaaS单租户大数据产品架构如上图所示,架构底层通常利用HDFS2实现;基于HDFS2之上搭建Hadoop Yarn或MESOS等资源管控平台;在其之上再实现具体的计算模型,如MR、Hive、HBASE以及Spark等。在这类生态环境中,IaaS平台通常作为同一租户存在,当用户产生新需求时,通过IaaS平台申请一批集群(虚机),再这些集群上部署相应的开源产品。从隔离的角度出发,这种生态面临以下问题:
首先,IaaS单租户大数据产品架构在实际使用时存在一定的逻辑问题。使用者进行数据分析时,需要了解使用的每种产品的具体逻辑,例如运行SQL时,需要理解Hive的逻辑,使用Spark时,需要学习spark的相关知识。当使用产品数量较少时,使用成本还能够得到有效控制;当需要多种产品相互协助使用时,学习成本便成几何倍数增加。并且,通常两款不同的开源产品之间的逻辑模型相互间无法识别,当遇到鉴权等问题时,逻辑问题更加突出。
其次,每一种开源产品在运行级别上都有其自身的优先级定义。在使用同一种开源产品时,任务的优先级会按照开源产品自身的优先级体系进行运行,高优先级的任务会比低优先级的任务得到更多的资源,运行的时长也会得到更好地保障。当同时使用多款开源产品时,基于IaaS单租户大数据产品架构无法做到运行优先级的全局最优化。
最后,上述这些开源产品通常会提供用户自定义逻辑,例如MR或Hive提供的UDF。当用户自定义的代码在大数据产品内运行时,会造成一定的安全风险。例如,Hadoop Yarn在运行用户自定义代码时,仅仅使用比较简单的Linux Container机制进行隔离。使用这种机制运行隔离时,用户的代码逻辑和Hadoop自身进程是运行在同一个内核(kernel)下的,也就是说如果这部分用户代码逻辑包含的攻击程序能够影响机器kernel,则在同一个内核下运行的大数据产品进程也会随之受到影响。通常情况下,大数据产品的一个Job会根据数据分片的大小同时运行在集群的大部分机器、甚至所有机器上。这种情况下,安全的风险便放大至整个集群。一种极端的情况是:当利用一个内核的漏洞攻击一台机器成功时,当所提交的Job分片足够大时,可能会使得整个计算集群瘫痪。
在认识到上述问题之后,MaxCompute通过独立自研整体系统架构,提供了PaaS层面的多租户能力。
MaxCompute PaaS多租户架构
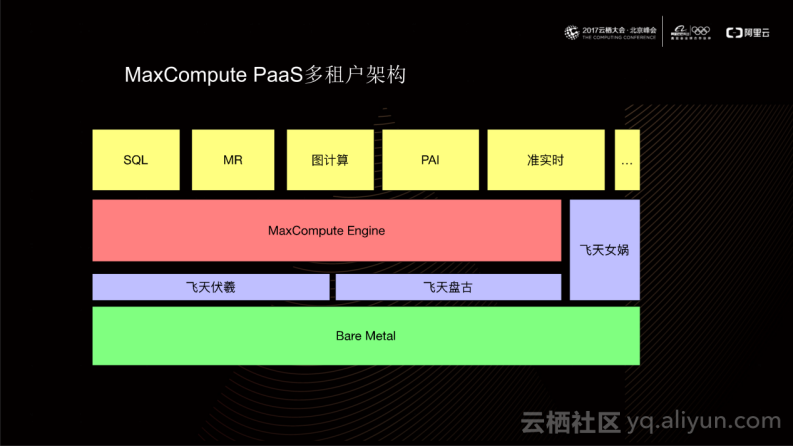
上图是MaxCompute PaaS多租户架构示意图。从图中可以看出,MaxCompute运行在飞天操作系统上,依赖于飞天伏羲模块提供统一资源管控;依赖于飞天盘古模块提供统一存储;依赖于飞天女娲模块提供一致性服务。MaxCompute通过提供同一套计算引擎为上层提供了多种计算形态,包括SQL、MR、图计算、PAI、准实时等。

目前,这套计算引擎已经为金融用户在公共云上提供了相应的计算能力。
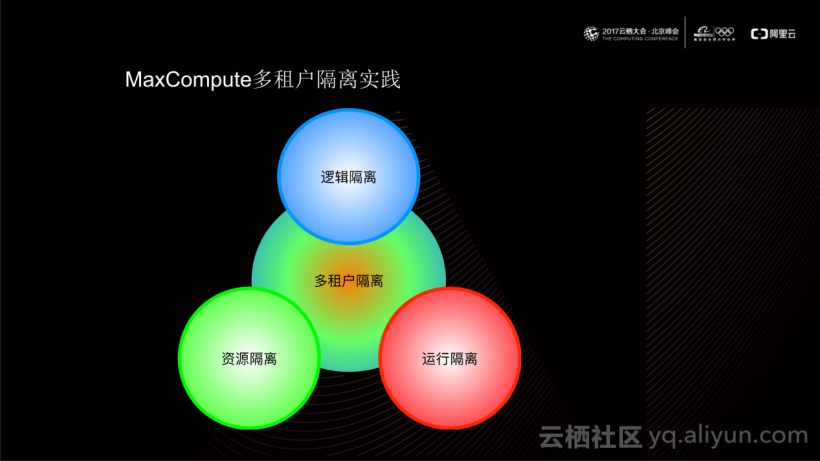
在解决MaxCompute多租户这一问题时,主要是从三个角度入手:
一是逻辑隔离。从租户的角度出发,每个租户都有自己独立的逻辑模型,拥有自己独立的资源以及基于相同的逻辑模型实现的统一授权模型。
二是资源隔离。对于不同租户的任务,在MaxCompute运行时,能够实现统一的、全局最优的任务调度能力以及资源隔离能力。
三是运行隔离机制。目前,MaxCompute提供了用户自定义逻辑的功能(如Python UDF),为用户自定义逻辑在MaxCompute上运行提供了一套完善的运行隔离机制。
下面来具体分析下MaxCompute提供的这三种隔离机制。
MaxCompute 逻辑隔离
目前,对于同一个MaxCompute实例,无论其运行在多少个物理集群上,都能在逻辑层提供统一的租户体系。对于这套租户体系,同一个租户的数据资源视图和权限管理模型是唯一的,并与租户模型绑定。在实际使用中,MaxCompute上的租户对应于MaxCompute的Project,其中Project包含租户所有的资源、属性以及权限等信息。
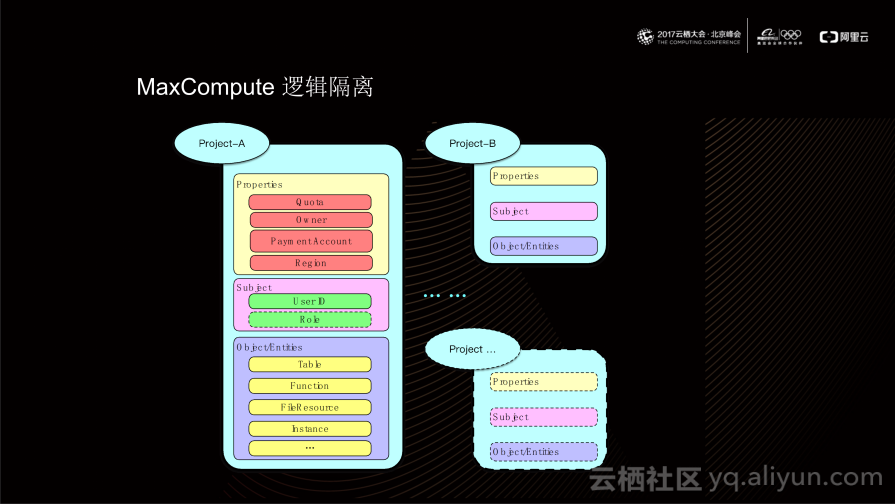
如上图所示,Project由属性(Properties)、主题(Subject)、实体(Object)三部分组成。其中属性包括Quota、Owner、Payment Account、Region等信息;在Project内部所有的授权访问都需要以User ID为主题,基于这些主题,MaxCompute提供了角色模型用于实现授权聚集;上文所提到的计算模型(MR、Hive等)要操作的资源最终都落脚于Project中的某一实体上,例如SQL模型对应于Table实体、UDF对应Function实体。
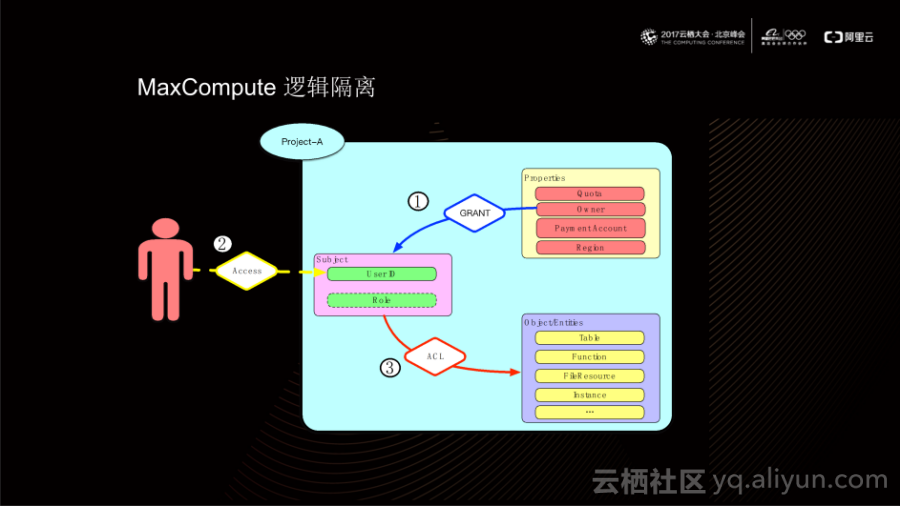
基于以上提供的逻辑模型,MaxCompute提供了一套完整的鉴权、授权机制用于管控权限。首先,所有权限均来源于Project Ower,作为Project的所有者,它拥有该Project内的全部权限,任何用户使用该Project进行计算时,首先需要Project Owner对其进行授权(具体实现是利用GTANT语句);当该用户访问Project时,它会以User ID的身份进行读写表、创建函数、添加删除资源等操作;这些操作被真正执行之前,会通过统一的ACL逻辑对当前User ID是否具有相应的权限进行判断。

上图给出了MaxCompute对不同类型对象支持的操作方式,更多详细操作说明请参考官方文档。
MaxCompute 资源隔离
MaxCompute 的计算引擎依赖于飞天操作系统提供资源运行、隔离能力。
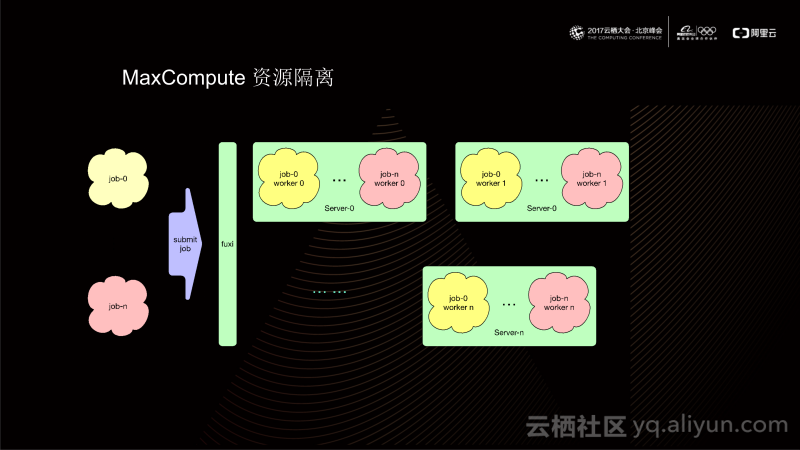
如上图所示,当不同任务Job-0、Job-n 提交到飞天伏羲模块时,伏羲的调度系统会根据不用用户的运行级别来分配任务的运行级别,这与上文提到的Project中的属性相对应。伏羲模块将不同的任务Job-0、Job-n转化为伏羲任务;然后调度到计算集群的节点上;最终在计算集群上,同一个server上会同时运行多个租户的任务,这些任务均以伏羲Worker形态运行。
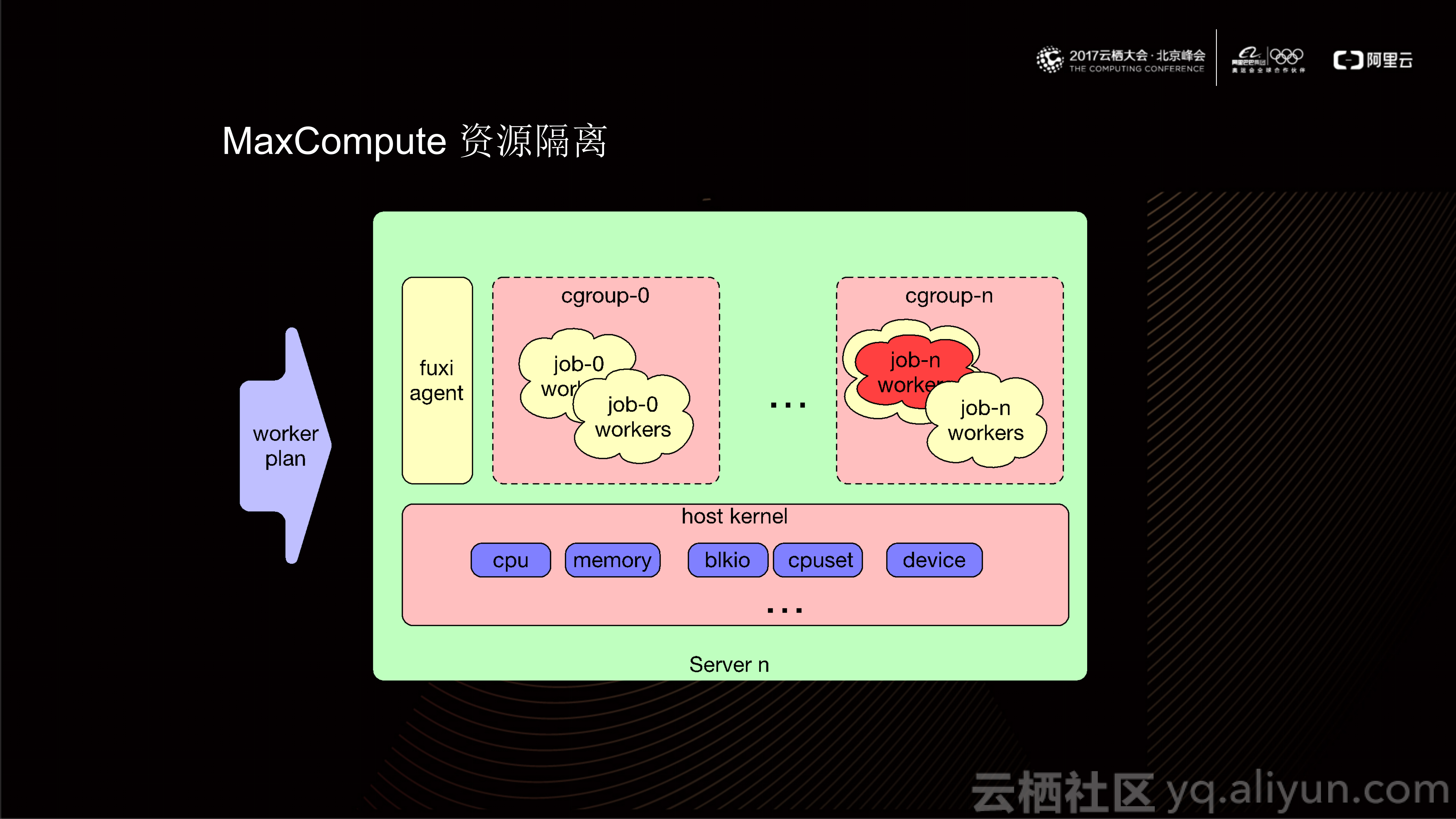
对于其中的一台机器,当该机器上的伏羲引擎收到Worker Plan后,它会根据Worker所对应用户的quota值去配置当前这台机器上的Cgroup的参数。这样一来,就保证不同用户提交的Job最终在物理机上运行的Cgroup配置参数不同。目前,MaxCompute依赖于Linux Kernel提供的Cgroup能力来规划某个特定进程在物理机上所得的CPU、Memory等资源。
MaxCompute 运行隔离
最后来分析下MaxCompute为了安全运行用户自定义逻辑所提供的运行隔离机制。当伏羲运行用户自定义代码逻辑时,它会拉取一个隔离的环境,把用户的代码运行在隔离的进程中。该进程对与伏羲而言与其他进程无差别,但其运行环境是在隔离系统中;也就说对于伏羲而言,这个进程是普通的进程,但对于untrusted code进程是隔离的。
运行隔离又可以分为进程隔离、设备隔离和网络隔离。
进程隔离
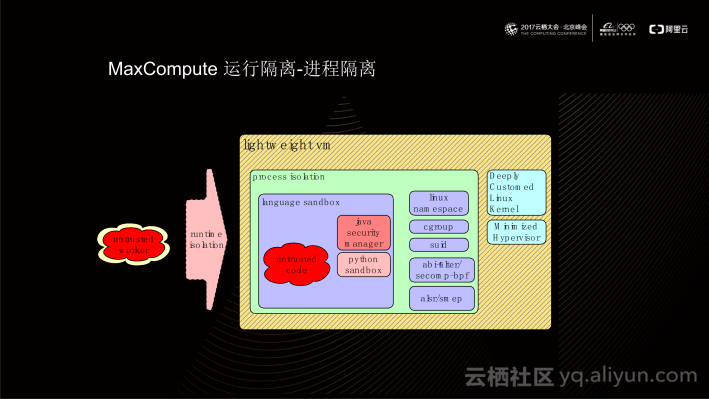
在进程隔离方面,对于单个进程而言,如果是运行的untrusted code(有可能包括恶意攻击的代码)进程,有可能会对计算平台造成损害。针对这一问题,MaxCompute提供了多层隔离嵌套方案以便规避这种潜在的安全风险。在最内部,MaxCompute提供了语言级沙箱,包括java sandbox和python sandbox,这种语言级别的沙箱为用户代码提供了最内层的隔离,例如java UDF 目前可以做到限制加载具体的类,python UDF可以做到函数级别的限制;外面一层,MaxCompute提供了进程隔离,它依赖于当前Linux Kernel提供的内核机制实现进程的隔离,使用的内核机制包括namespace、cgroup 、secomp-bpf等;最外侧,MaxCompute实现了一层轻量级的虚拟化,它的实现原理是通过深度定制Linux Kernel以及一个最小化的Hypervisor,进而提供非常轻量级的虚拟机(建立时间仅为几百毫秒)。这样一来,untrusted code最终会以hypervisor方式运行在物理机;也就是说,对于伏羲而言,它看到的仅仅是hypervisor的进程,但对于untrusted code,它看到的是一套隔离环境。
设备隔离
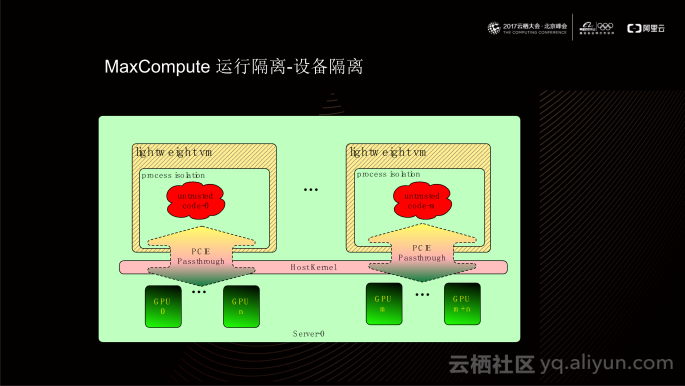
除此之外,MaxCompute也为用户自定义代码提供了硬件加速能力,例如PAI是支持直接GPU访问。目前,MaxCompute通过PCIE passthrough方式将GPU卡直接passthrough到VM内部,允许guest进程直接通过PCIE总线以及guest kernel 内的GPU driver来访问GPU。
这种VM通过PCIE总线访问GPU的实现方式相较于在物理机直接访问GPU,性能相近;另一方面,在物理机上无需安装GPU driver,规避掉了GPU driver对平台稳定性和可靠性影响。
网络隔离
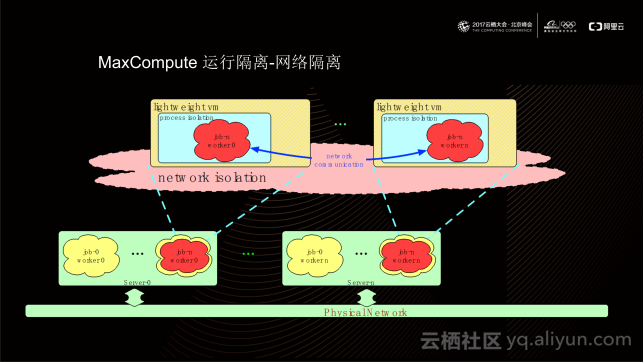
在某些产品上,MaxComputer为用户代码逻辑提供了网络隔离能力。在伏羲拉起的VM之间实现了一层虚拟网络。这些VM可以通过虚拟网络进行直接通信,这也为在VM内部运行一些开源代码提供了良好的兼容性。同时,从上图可以看到,用户自定义的代码逻辑并不是直接访问物理网络的;而伏羲拉起的tursted code包括MaxCompute框架上的代码是通过物理网络进行通信的,这种做法保证了MaxCompute框架在通信上的低时延。
关于分享者:阿里云高级技术专家 李雪峰,目前在阿里云负责Maxcompute系统方面的工作。
华北2(北京)Region MaxCompute购买地址:https://common-buy.aliyun.com/?commodityCode=odpsplus#/buy
欢迎加入“数加·MaxCompute购买咨询”钉钉群(群号: 11782920)进行咨询,群二维码如下: