今天要介绍的是如何使用MONGODB中提供的MapReduce功能进行查询。
今天介绍如何基于sharding机制进行mapreduce查询。在MongoDB的官方文档中,这么一句话:
Sharded Environments
In sharded environments, data processing of map/reduce operations runs in parallel on all shards.
即: map/reduce操作会并行运行在所有的shards上。
下面我们就用之前这篇文章中白搭建的环境来构造mapreduce查询:
首先要说的是,基于sharding的mapreduce与非sharding的数据在返回结构上有一些区别,我目前注意到的主要是不支持定制式的json格式的返回数据,也就是下面方式可能会出现问题:
return { count : total };
注意:上面的情况目前出现在了我的测试环境下,如下图:
就需要改成 return count;
下面是测试代码,首先是按帖子id来查询相应数量(基于分组查询实例方式):
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->public partial class getfile : System.Web.UI.Page
{
public Mongo Mongo { get; set; }
public IMongoDatabase DB
{
get
{
return this.Mongo["dnt_mongodb"];
}
}
/// <summary>
/// Sets up the test environment. You can either override this OnInit to add custom initialization.
/// </summary>
public virtual void Init()
{
string ConnectionString = "Server=10.0.4.85:27017;ConnectTimeout=30000;ConnectionLifetime=300000;MinimumPoolSize=512;MaximumPoolSize=51200;Pooled=true";
if (String.IsNullOrEmpty(ConnectionString))
throw new ArgumentNullException("Connection string not found.");
this.Mongo = new Mongo(ConnectionString);
this.Mongo.Connect();
}
string mapfunction = "function(){\n" +
" if(this._id=='548111') { emit(this._id, 1); } \n" +
"};";
string reducefunction = "function(key, current ){" +
" var count = 0;" +
" for(var i in current) {" +
" count+=current[i];" +
" }" +
" return count ;\n" +
"};";
protected void Page_Load(object sender, EventArgs e)
{
Init();
var mrb = DB["posts1"].MapReduce();//attach_gfstream.files
int groupCount = 0;
using (var mr = mrb.Map(mapfunction).Reduce(reducefunction))
{
foreach (Document doc in mr.Documents)
{
groupCount = int.Parse(doc["value"].ToString());
}
}
this.Mongo.Disconnect();
}
}
下面是运行时的查询结果,如下:
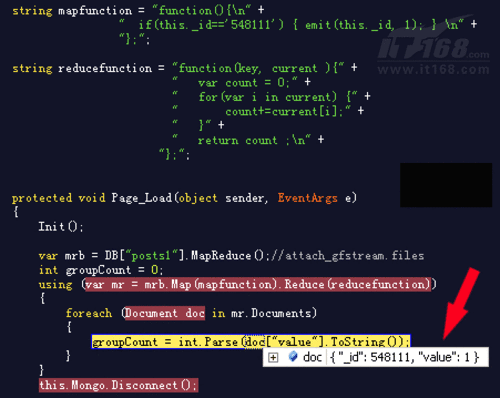
接着演示一下如何把查询到的帖子信息返回并装入list集合,这里只查询ID为548110和548111两个帖子:
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> string mapfunction = "function(){\n" +
" if(this._id=='548110'|| this._id=='548111') { emit(this, 1); } \n" +
"};";
string reducefunction = "function(doc, current ){" +
" return doc;\n" +
"};";
protected void Page_Load(object sender, EventArgs e)
{
Init();
var mrb = DB["posts1"].MapReduce();//attach_gfstream.files
List<Document> postDoc = new List<Document>();
using (var mr = mrb.Map(mapfunction).Reduce(reducefunction))
{
foreach (Document doc in mr.Documents)
{
postDoc.Add((Document)doc["value"]);
}
}
this.Mongo.Disconnect();
}
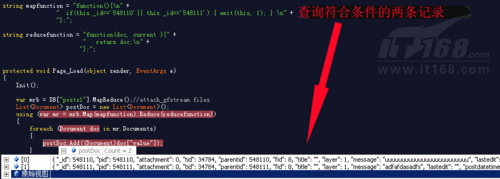
下面是运行时的查询结果,如下:
上面的map/reduce方法还有许多写法,如果大家感兴趣可以看一下如下这些链接:
http://cookbook.mongodb.org/patterns/unique_items_map_reduce/
http://www.mongodb.org/display/DOCS/MapReduce
以及之前我写的这篇文章:http://www.cnblogs.com/daizhj/archive/2010/06/10/1755761.html
当然在mongos进行map/reduce运算时,会生成一些临时文件,如下图:
我猜这些临时文件可能会对再次查询系统时的性能有一些提升(但目前未观察到)。
当然对于mongodb的gridfs系统(可使用它搭建分布式文件存储系统,我之前在这篇文章中已介绍过,我也做了测试,但遗憾的是并未成功,它经常会报一些错误,比如:
Thu Sep 09 12:09:29 Assertion failure _grab client\parallel.cpp 461
看来mapreduce程序链接到mongodb上时,会产生一些问题,但不知道是不是其自身稳定性的原因,还是我的机器环境设置问题(内存或配置的64位系统mongos与32位的client连接问题)。
