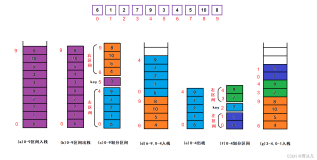
1.三种选择排序(简单选择排序,树形选择排序,堆排序)
#include<iostream> #include<cstring> #include<string> #include<queue> #include<map> #include<cstdlib> #include<cstdio> const int INF=0X3f3f3f3f; using namespace std; typedef struct { int a[100]; int len; void outList(){ for(int i=1; i<=len; ++i) cout<<a[i]<<" "; cout<<endl; } }list; list L; int smaller(int a, int b) { return a>b?b:a; } /**********************************************************************************/ void sample_selection_sort()//简单选择排序 { int i, j, k; for(i=1; i<=L.len; i++) { k=i; for(j=i+1; j<=L.len; j++) if(L.a[k]>L.a[j]) k=j; if(k!=i) { L.a[i]^=L.a[k]; L.a[k]^=L.a[i]; L.a[i]^=L.a[k]; } } } /**********************************************************************************/ int tree[400]; void tree_choose_sort(int ld, int rd, int p)//树形选择排序,和线段树差不多 { if(rd==ld) tree[p]=L.a[ld]; else { int mid=(ld+rd)/2; tree_choose_sort(ld, mid, p<<1); tree_choose_sort(mid+1, rd, p<<1|1); tree[p]=smaller(tree[p<<1], tree[p<<1|1]); } } void update_tree(int ld, int rd, int p, int key)//树形选择排序 { if(rd==ld) { if(key==tree[p]) tree[p]=INF; } else { int mid=(ld+rd)/2; if(key==tree[p<<1]) update_tree(ld, mid, p<<1, key); else update_tree(mid+1, rd, p<<1|1, key); tree[p]=smaller(tree[p<<1], tree[p<<1|1]); } } /**********************************************************************************/ typedef struct tree//树形选择排序 { int d; struct tree *lchild; struct tree *rchild; }*TREE; void build_tree(TREE &T, int ld, int rd)//树形选择排序 { if(ld==rd) { T->lchild=T->rchild=NULL; T->d=L.a[ld]; } else { int mid=(rd+ld)/2; T=(TREE)malloc(sizeof(tree)); T->lchild=(TREE)malloc(sizeof(tree)); T->rchild=(TREE)malloc(sizeof(tree)); build_tree(T->lchild, ld, mid); build_tree(T->rchild, mid+1, rd); T->d=smaller(T->lchild->d, T->rchild->d); } } void Update_tree(TREE &T, int key)//树形选择排序 { if(T) { if(!T->lchild && !T->rchild) { if(T->d==key) T->d=INF; } else { if(key==T->lchild->d) Update_tree(T->lchild, key); else if(key==T->rchild->d) Update_tree(T->rchild, key); T->d=smaller(T->lchild->d, T->rchild->d); } } } /**********************************************************************************/ void heapAdjust(int ld, int rd){//堆排序, 排序区间[ld,rd] int rc = L.a[ld]; int cur = ld; for(int p = ld*2; p<=rd; p=p*2){ if(p<rd && L.a[p] > L.a[p+1]) ++p;//取左右子树的最小值 if(rc < L.a[p]) break;//如果父节点的值比左右子树的值都小,那么已经调整好了,已经是小堆顶了 L.a[cur] = L.a[p];//否则交换父节点和左右子树最小的子树的值,父节点的值存在rc中,所以只要将最小子树的值赋给父节点就好 cur = p; } L.a[cur] = rc; } /**********************************************************************************/ int main() { int i; scanf("%d", &L.len); for(i=1; i<=L.len; i++) scanf("%d", &L.a[i]); //selection_sort();//选择排序 // tree_choose_sort(1, L.len, 1);//树形选择排序 // // int n=L.len; // while(n--) // { // printf("%d ", tree[1]); // update_tree(1, L.len, 1, tree[1]); // } // TREE T;//树形选择排序 // build_tree(T, 1, L.len); // int n=L.len; // while(n--) // { // printf("%d ", T->d); // Update_tree(T, T->d); // } for(int i=L.len/2; i>=1; --i)//将整个区间调整成小堆顶 heapAdjust(i, L.len); for(int i=1; i<=L.len; ++i) { cout<<L.a[1]<<" "; L.a[1] = L.a[L.len-i+1];//将最后一个元素赋给第一个元素 heapAdjust(1, L.len-i);//重新调整堆 } cout<<endl; return 0; }
2.冒泡排序
#include<iostream> #include<cstring> #include<string> #include<queue> #include<map> #include<cstdlib> #include<cstdio> const int INF=0X3f3f3f3f; using namespace std; typedef struct { int a[100]; int len; void outList(){ for(int i=1; i<=len; ++i) cout<<a[i]<<" "; cout<<endl; } }list; list L; void bubble_sort() { int i, j, change=1; for(j=L.len; change && j>=1; j--) { change=0; for(i=1; i<j; i++) if(L.a[i]>L.a[i+1]) { L.a[i]^=L.a[i+1]; L.a[i+1]^=L.a[i]; L.a[i]^=L.a[i+1]; change=1; } } } int main() { int i; scanf("%d", &L.len); for(i=1; i<=L.len; i++) scanf("%d", &L.a[i]); bubble_sort(); return 0; }
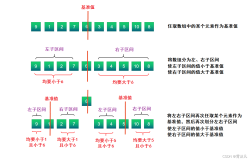
3.快速排序(有两种的分割方法,第二种分割方法效率更高一些)
#include<iostream> #include<cstring> #include<string> #include<queue> #include<map> #include<cstdlib> #include<cstdio> const int INF=0X3f3f3f3f; using namespace std; typedef struct { int a[100]; int len; void outList(){ for(int i=1; i<=len; ++i) cout<<a[i]<<" "; cout<<endl; } }list; list L; int partition(int low, int high)//将数据元素划分为左边都小于枢轴,右边元素都大于枢轴 { //采用三者取中的方法选择枢轴 if((L.a[high]-L.a[low]) * (L.a[high]-L.a[(low+high)/2]) < 0) swap(L.a[low], L.a[high]); else if((L.a[(low+high)/2]-L.a[low]) *(L.a[(low+high)/2]-L.a[high]) < 0) swap(L.a[low], L.a[(low+high)/2]); int pivotkey=L.a[low];// 枢轴关键字 while(low<high) { while(low<high && L.a[high]>=pivotkey) high--; L.a[low]=L.a[high]; while(low<high && L.a[low]<=pivotkey) low++; L.a[high]=L.a[low]; } L.a[low]=pivotkey; return low; }
int partitionTwo(int ld, int rd){
int mid = (ld+rd)>>1;
if((a[mid]-a[ld]) * (a[mid]-a[rd]) < 0)
swap(a[mid], a[ld]);
else if((a[rd]- a[ld]) * (a[rd]-a[mid]) < 0)
swap(a[rd], a[ld]);
int i=ld;//使得表a[ld.....i] 中的所有的元素都是小于pivot的元素,初始表为空, a[ld]表示枢轴
int pivot = a[ld];
for(int j=ld+1; j<=rd; ++j)
if(a[j] < pivot)
swap(a[++i], a[j]);
swap(a[i], a[ld]);
return i;
}
void Qsort(int low, int high)//快速排序 { if(low<high) { int p=partition(low, high); Qsort(low, p-1); Qsort(p+1, high); } } int main() { int i; scanf("%d", &L.len); for(i=1; i<=L.len; i++) scanf("%d", &L.a[i]); Qsort(1, L.len); L.outList(); return 0; }
4.归并排序
#include<iostream> #include<cstring> #include<string> #include<queue> #include<map> #include<cstdlib> #include<cstdio> const int INF=0X3f3f3f3f; using namespace std; typedef struct { int a[100]; int len; void outList(){ for(int i=1; i<=len; ++i) cout<<a[i]<<" "; cout<<endl; } }list; list L; void Merge(int lr, int rr)//归并排序 { int atemp[100], mid=(lr+rr)/2;//atemp[]存放两个有序表合并后的结果 int i, j, k; for(i=lr, j=mid+1, k=0; i<=mid && j<=rr; )//将两个有序表的合并代码 { if(L.a[i]<=L.a[j]) atemp[k++]=L.a[i++]; else atemp[k++]=L.a[j++]; } if(i>mid) for(k; j<=rr; j++) atemp[k++]=L.a[j]; if(j>rr) for(k; i<=mid; i++) atemp[k++]=L.a[i]; memcpy(L.a+lr, atemp, sizeof(int)*k);//将两段儿有序表合并后的结果 } //复制到原来对应的位置上 void Msort(int ld, int rd) { if(ld<rd) { int mid=(ld+rd)/2; Msort(ld, mid); Msort(mid+1, rd); Merge(ld, rd);//回溯法合并有序 序列 } } int main() { int i; scanf("%d", &L.len); for(i=1; i<=L.len; i++) scanf("%d", &L.a[i]); Msort(1, L.len); L.outList(); return 0; }
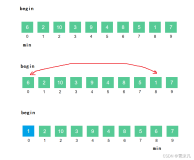
5.插入排序
#include<iostream> #include<cstring> #include<algorithm> #include<cstdio> using namespace std; const int INF=0X3f3f3f3f; typedef struct { int a[100]; int len; void outList(){ for(int i=1; i<=len; ++i){ cout<<a[i]<<" "; } cout<<endl; } }list; list L; /*********************************************************************/ void direct_insertion_sort()//直接插入排序 { int i, j; for(i=2; i<=L.len; i++) { L.a[0]=L.a[i]; for(j=i-1; L.a[0]<L.a[j]; j--) L.a[j+1]=L.a[j]; L.a[j+1]=L.a[0]; } } /*********************************************************************/ void benary_insertion_sort1()//折半插入排序 { int i, j, left, right, mid; for(i=2; i<=L.len; i++) { left=1; right=i-1; L.a[0]=L.a[i]; while(left<=right) { mid=(left+right)/2; if(L.a[mid]<=L.a[0]) left=mid+1; else right=mid-1; } for(j=i-1; j>=left; j--) L.a[j+1]=L.a[j]; L.a[j+1]=L.a[0]; } } /*********************************************************************/ void benary_insertion_sort2(){//折半插入排序 for(int i=2; i<=L.len; ++i){ L.a[0] = L.a[i]; int k = upper_bound(L.a+1, L.a+i, L.a[0]) - L.a;//返回最后一个大于key的位置 for(int j=i; j>k; --j) L.a[j] = L.a[j-1]; L.a[k] = L.a[0]; } } /*********************************************************************/ void twoWay_insertion_sort()//二路插入排序 { int *d=(int *)malloc(sizeof(int)*L.len); int first, final, i, j; first=final=0; d[0]=L.a[1]; for(i=2; i<=L.len; i++) { if(L.a[i]>=d[final])//直接添加在尾部 d[++final]=L.a[i]; else if(L.a[i]<=d[first])//直接添加在头部 d[first=(first-1+L.len)%L.len]=L.a[i]; else//在头部和尾部中间 { for(j=final++; d[j]>=L.a[i]; j=(j-1+L.len)%L.len) d[(j+1)%L.len]=d[j]; d[(j+1)%L.len]=L.a[i]; } } for(i=first, j=1; i!=final; i=(i+1)%L.len, j++) L.a[j]=d[i];
L.a[j] = d[i]; } /*********************************************************************/ void shell_insertion_sort(int d) { int i, j; for(i=d+1; i<=L.len; i++) { if(L.a[i]<L.a[i-d])//需要将L.a[i]插入有序增量字表 { L.a[0]=L.a[i]; for(j=i-d; j>=1 && L.a[0]<=L.a[j]; j-=d) L.a[j+d]=L.a[j]; L.a[j+d]=L.a[0]; } } } void shellsort()//希尔排序 { int dk[]={5, 3, 1};//设置子序列的增量 for(int i=0; i<3; i++) shell_insertion_sort(dk[i]); } /*********************************************************************/ typedef struct xxx{ int head;//头结点 int a[100]; int next[100];//记录下一个元素的位置 int len; xxx(){ head = 1; memset(next, 0, sizeof(next)); } void outList(){ for(int i=1; i<=len; ++i){ cout<<a[i]<<" "; } cout<<endl; } }Listx; Listx Lx; void table_insertion_sort(){//表插入排序,相当于静态链表 for(int i=2; i<=Lx.len; ++i){ int pre, p; for(p=Lx.head; p && Lx.a[p]<Lx.a[i]; pre=p, p=Lx.next[p]); if(p==0){ Lx.next[pre] = i; } else if(p==Lx.head){ Lx.next[i] = Lx.head; Lx.head = i; } else { Lx.next[pre] = i; Lx.next[i] = p; } } //输出 for(int i=Lx.head; i; i = Lx.next[i]) cout<<Lx.a[i]<<" "; cout<<endl; } void arrang_table() { int p = Lx.head, q; for(int i=1; i<Lx.len; ++i){ while(p < i) p = Lx.next[p];//第i个记录在表中的位置不应该小于 i,如果小于i,说明该元素已经被交换位置了,可以通过next继续寻找 q = Lx.next[p];//指向下一个节点 if(p!=i){//第p个元素应该在第i个位置 swap(Lx.a[i], Lx.a[p]); swap(Lx.next[i], Lx.next[p]); Lx.next[i] = p;//该元素之前的位置 p,指向被移走的记录,使得以后可由while循环找回 } p = q; } for(int i=1; i<=Lx.len; ++i) cout<<Lx.a[i]<<" "; cout<<endl; } /*********************************************************************/ int main() { int i; scanf("%d", &Lx.len); for(i=1; i<=Lx.len; i++) scanf("%d", &Lx.a[i]); // benary_insertion_sort2(); // L.outList(); table_insertion_sort(); arrang_table(); return 0; } /* 8 49 38 6 5 97 76 13 27 49 */
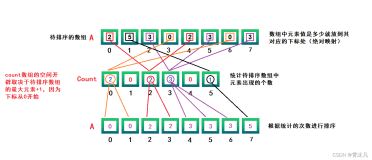
6.基数排序(LSD and MSD)
#include<iostream> #include<cstring> #include<cstdio> #include<algorithm> #include<cmath> #include<queue> #define N 1000 using namespace std; /* 题目:对基数排序的练习, 它是一种很特别的方法,它不是基于比较进行排序的,而是采用多关键字排序思想, 借助"分配" 和 "收集" 两种操作对单逻辑关键字进行排序, 分为最高位优先MSD排序和最低为优LSD先排序 */ int radix[]={1, 10, 100, 1000};//每个数字的位数最多是3位 int cnt[10]; int a[N], bucket[N]; int n; int k;//记录数字中位数最多的 /* (1)LSD最低位优先法实现 最低位优先法首先依据最低位关键码Kd对所有对象进行一趟排序, 再依据次低位关键码Kd-1对上一趟排序的结果再排序, 依次重复,直到依据关键码K1最后一趟排序完成,就可以得到一个有序的序列。 使用这种排序方法对每一个关键码进行排序时,不需要再分组,而是整个对象组。 */ void LSD_radixSort(){ for(int i=1; i<=k; ++i){ memset(cnt, 0, sizeof(cnt)); //统计各个桶中所盛数据个数, 关键字相同的数字放入到同一个桶中 for(int j=1; j<=n; ++j) ++cnt[a[j]%radix[i]/radix[i-1]]; //cnt[i]表示第i个桶的右边界索引 for(int j=1; j<10; ++j) cnt[j] += cnt[j-1]; //把数据依次装入桶(注意装入时候的分配技巧) for(int j=n; j>=1; --j){//这里要从右向左扫描,保证排序稳定性 int x = a[j]%radix[i]/radix[i-1]; //求出关键码的第k位的数字, 也就是第x个桶的编号, 例如:576的第3位是5 bucket[cnt[x]] = a[j];//放入对应的桶中,cnt[x]是第x个桶的右边界索引 --cnt[x];//对应桶的装入数据索引减一 } memcpy(a, bucket, sizeof(int)*(n+1)); } } /* (2)MSD最高位优先法实现 最高位优先法通常是一个递归的过程: <1>先根据最高位关键码K1排序,得到若干对象组,对象组中每个对象都有相同关键码K1。 <2>再分别对每组中对象根据关键码K2进行排序,按K2值的不同,再分成若干个更小的子组,每个子组中的对象具有相同的K1和K2值。 <3>依此重复,直到对关键码Kd完成排序为止。 <4> 最后,把所有子组中的对象依次连接起来,就得到一个有序的对象序列。 */ void MSD_radixSort(int ld, int rd, int radixI){//[ld, rd]是a数组的待排序的区间,radixI是当前这段数组每个数字的基数 int cnt[11];//必须每个栈中都定义 memset(cnt, 0, sizeof(cnt)); //统计各个桶中所盛数据个数, 关键字相同的数字放入到同一个桶中 for(int j=ld; j<=rd; ++j) ++cnt[a[j]%radix[radixI]/radix[radixI-1]]; //cnt[i]表示第i个桶的右边界索引 for(int j=1; j<=10; ++j) cnt[j] += cnt[j-1]; //把数据依次装入桶(注意装入时候的分配技巧) for(int j=rd; j>=ld; --j){//这里要从右向左扫描,保证排序稳定性 int x = a[j]%radix[radixI]/radix[radixI-1]; //求出关键码的第k位的数字, 也就是第x个桶的编号, 例如:576的第3位是5 bucket[cnt[x]] = a[j];//放入对应的桶中,cnt[x]是第x个桶的右边界索引 --cnt[x];//对应桶的装入数据索引减一 } for(int i=ld, j=1; i<=rd; ++i, ++j)//重排区间[ld, rd], a数组区间[ld,rd]对应bucket数组区间[1, rd-ld+1] a[i] = bucket[j]; for(int i=0; i<10; ++i){//对各个桶中的数据在进行下一个关键字的排序 int ldd = ld + cnt[i]; int rdd = ld + cnt[i+1] - 1; //获得子桶的子区间[ldd, rdd] if(ldd < rdd && radixI>1) MSD_radixSort(ldd, rdd, radixI-1); } } int main(){ cin>>n; k = 0; for(int i=1; i<=n; ++i){ cin>>a[i]; k = max(k, (int)log10(a[i])+1); } // LSD_radixSort(); // for(int i=1; i<=n; ++i) // cout<<a[i]<<" " ; // cout<<endl; MSD_radixSort(1, n, k); for(int i=1; i<=n; ++i) cout<<a[i]<<" " ; cout<<endl; return 0; } /* 7 329 457 657 839 436 720 355 */