前段时间在公司小范围做了一个关于PG事务实现的讲座,最后总结了一个摘要性的东西,分享一下,欢迎拍砖。
背景说明:
以ACID为特征的事务是关系数据库的一项重要的也是基本的功能。了解事务的实现原理不仅对数据库产品本身的开发,对使用数据库的应用程序的开发也有一定的益处。因此本次以PostgreSQL为对象简单介绍了其事务实现的原理。
内容概述:
事务的实现原理可以解读为DBMS采取何种技术确保事务的ACID特性。PostgreSQL针对ACID的实现技术如下表所示。
表1:事务的4个特征ACID及响应的实现技术
| ACID |
实现技术 |
| 原子性 |
MVCC |
| 一致性 |
约束(主键,外键等) |
| 隔离性 |
MVCC |
| 持久性 |
WAL |
可以看到PostgreSQL中支撑ACID的主要是MVCC和WAL两项技术。MVCC和WAL是两个比较成熟的技术,通常的关系数据库中都有相应的实现,但每个数据库具体的实现方式又存在很大差异。下面介绍一下PostgreSQL中MVCC和WAL的基本实现原理。
1. MVCC
MVCC(Multiversion Concurrency Control)即多版本并发控制,它可以避免读写事务之间的互相阻塞,相比通常的封锁技术可极大的提高业务的并发性能。PostgreSQL中的MVCC实现原理可简单概括如下:
1)数据文件中存放同一逻辑行的多个行版本(称为Tuple)
2)每个行版本的头部记录创建以及删除该行版本的事务的ID(分别称为xmin和xmax)
3)每个事务的状态(运行中,中止或提交)记录在pg_clog文件中
4)根据上面的数据并运用一定的规则每个事务只会看到一个特定的行版本
通过MVCC读写事务可以分别在不同的行版本上工作,因此能够在互不冲突的情况下并发执行。
图1:基于MVCC的数据更新举例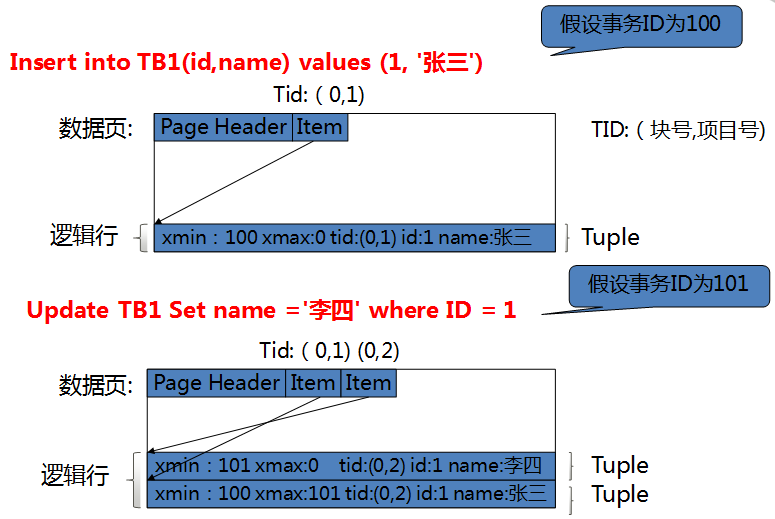
2. WAL
当系统意外宕机后,恢复时需要回退未完成事务所做的更改并确保已提交事务所作的更改均已生效。在PostgreSQL中通过前面提到的MVCC很容易做到的第一点,只要把所有pg_clog文件中记录的所有“运行中”的事务的状态置为“中止”即可,这些事务在宕机时都没有结束。对于第二点,必须确保事务提交时修改已真正写入到永久存储中。但是直接刷新事务修改后的数据到磁盘是很费时的,为解决这个问题于是引入了WAL(Write-Ahead Log)。
WAL的基本原理如下:
1)更新数据页前先将更新内容记入WAL日志
2)异步刷新数据Buffer的脏页和WAL Buffer到磁盘
3)Buffer管理器确保绝不会先于对应的WAL记录刷新脏数据到磁盘
4)事务提交时,将WAL日志同步刷新到磁盘
5)Checkpoint发生时,将数据Buffer的所有脏页刷新到磁盘
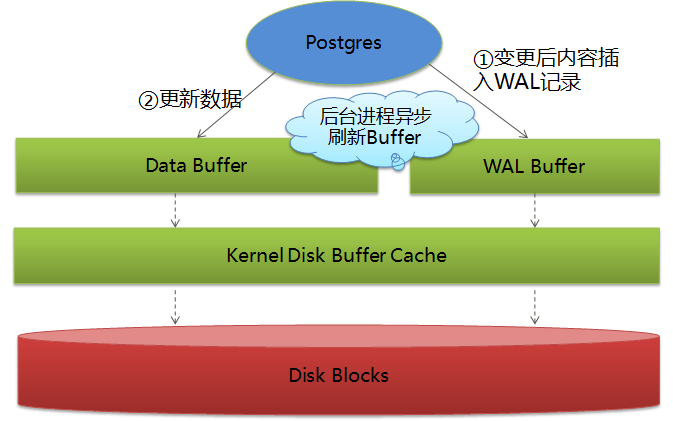
图3:更新提交和Checkpoint时的磁盘同步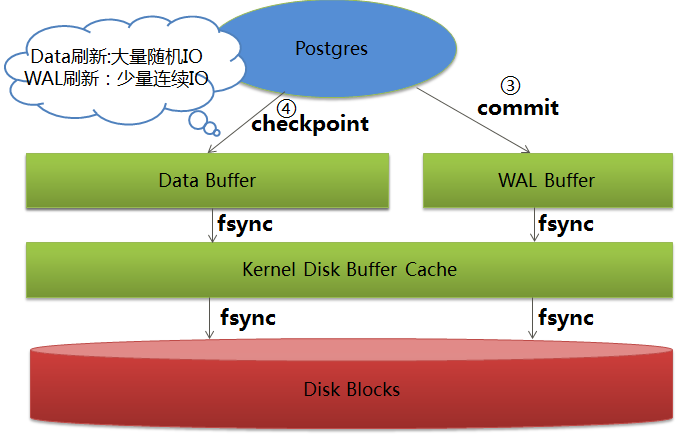
Q&A:
1、Q:PostgreSQL中DDL支不支持事务?
A:支持。PostgreSQL中对DDL的处理方式和普通的DML类似,也是支持事务的。
2、 Q:PostgreSQL中对BLOB数据的处理支不支持事务?
A:支持。对BLOB(bytea或large object)数据的事务处理和普通数据的差别不大,但由于BLOB数据较大涉及BLOB的事务会产生很大的WAL日志文件。
3、Q:PostgreSQL中很大的数据,比如BLOB如何在数据页面中存储?
A:默认数据页面的大小是8K,当有很大数据时可能导致一个页面放不下整个数据行。针对这种情况,PostgreSQL采取一种叫做TOAST的技术,对于比较大的列只在行中放一个类似指针的东西,完整的数据放在另一个单独的TOAST表中。在TOAST表中数据被切割成若干个chunk,每个chunck以一个数据行的形式存放。
4、Q:PostgreSQL中可重复读和可串行化隔离级别都不会出现幻读那它们的区别是什么?
A: 根据SQL规约,能够回避幻读就已经满足了“可串行化”隔离级别的要求。但是SQL规约定义的“可串行化”并不是严格意义上的可串行化,仅仅能回避幻读不等于可以把并发执行的几个事务转化为几个事务严格按某个顺序先后执行 。PostgreSQL中的可重复读可以回避幻读但不是严格意义上的可串行化,但是可串行化就是。顺便说一下,Oracle中的可串行化也不是严格意义上的可串行化,实际上它等价于PostgreSQL中的可重复读。
5、Q:PostgreSQL中事务ID分配完了怎么办?
A:从头开始重新分配(实际上从3开始重新分配,0,1,2已做为特殊用途,这称之为事务回卷)。但这样可能形成事务ID冲突的问题,PostgreSQL中解决这个问题的措施有两个。第一,定期清理留在数据文件中的过老的事务ID,将它们统一设置为一个特殊值(2),在做事务新旧比较时,这个特殊的事务ID永远比其他普通的事务ID旧。这就保证了系统中事务ID的范围跨度不会过大。第二,在做事务新旧比较时不是简单的比较两个事务ID的算数值大小,而且考虑到了特殊事务ID和事务回卷的情况。比如根据内部的比较规则,无符号INT类型的事务ID 0x00000005比0xFFFFFFFF新。因为第一个措施已经保证了系统中事务ID间的跨度不会过大(不超过2^31),所以0x00000005一定是事务ID回卷后的结果而0xFFFFFFFF还没有发生回卷(或者说比0x00000005少回卷一次)。
PPT下载: 浅析PostgreSQL事务处理机制.pdf
浅析PostgreSQL事务处理机制.pdf
